Con SQL Server 2025, Microsoft ha decidido que ya era hora de dejar atrás el vetusto algoritmo MS_XPRESS para la compresión de backups y nos presenta a su nuevo juguete: Zstandard, o ZSTD para los amigos. No se trata de una mejora menor ni de un simple lavado de cara. Estamos ante un cambio real, tangible y, lo más importante, medible. Porque ya está bien de hacer backups comprimidos que no se sabe si salvan espacio o lo rellenan de aire.
En este artículo nos meteremos de lleno en las pruebas reales de rendimiento y compresión usando este nuevo algoritmo en la versión preliminar de SQL Server 2025 (17.x). Y sí, he hecho los deberes: mismo entorno, misma base de datos, mismas condiciones. Porque si vamos a hablar de rendimiento, hay que hacerlo como profesionales, no como vendedores de humo.
Un poco de contexto en esto de la compresión (pero solo el justo)
Hasta ahora, la compresión de backups en SQL Server se basaba principalmente en MS_XPRESS, ese algoritmo que venía con SQL Server y que, siendo honestos, cumplía. Pero cumplía como un coche de hace 20 años: te lleva, pero consume más de lo que debería y no gana ninguna carrera.
SQL Server 2025 introduce ZSTD como nuevo algoritmo de compresión, y según la propia documentación oficial, se trata de un método más rápido y más eficaz. No es marketing barato: ZSTD lleva años siendo la niña bonita del mundo open source, utilizado en proyectos como Facebook, zfs o Kubernetes. Y ahora por fin aterriza en SQL Server.
Escenario de pruebas: sin cuentos
He estado leyendo e intercambiando opiniones con otros compañeros MVPs de Microsoft y algunas pruebas les arrojaban reducciones de tiempo de hasta un 50%. Yo tenía que probarlo, y además he utilizado la base de datos StackOverflow2013 para las pruebas. Una base de datos con más de seis millones de páginas de datos (más de 50Gb) suficiente para ver diferencias significativas. Además con campos de texto grandes y pocos valores nulos o repetidos, cosas que siempre han puesto en aprietos a la compresión de SQL Server. Todo un reto para el nuevo algoritmo.
Todas las pruebas las he ejecutado en la misma instancia de SQL Server 2025 CTP 2.0, con la base de datos restaurada entre cada backup para mantener la consistencia. Ni trucos, ni trampa, ni memoria caché jugando sucio.
Backup tradicional con compresión MS_XPRESS
Para esta primera prueba vamos a realizar un backup con la comprensión tradicional de SQL Server para saber contra qué estamos comparándonos.
BACKUP DATABASE [StackOverflow2013]
TO DISK = N'C:\Program Files\...\StackOverflow2013.bak'
WITH NOFORMAT, NOINIT, SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10;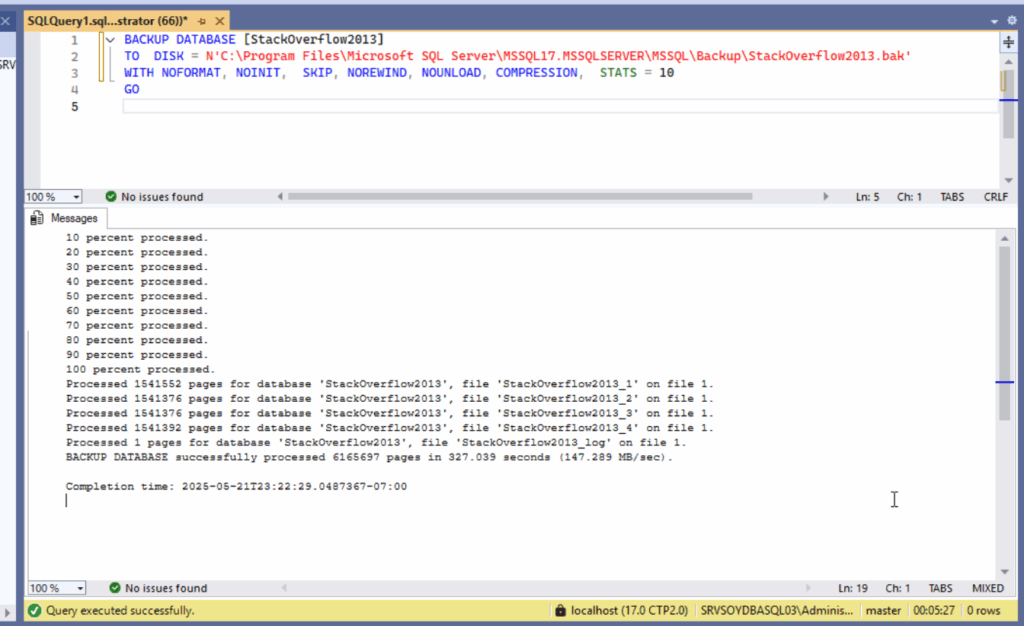
Resultados:
- Tiempo total: 327 segundos
- Velocidad media: 147.289 MB/seg
- Tamaño comprimido: 14.84 GB
Backup nuevo con compresión ZSTD
Llega el momento de la verdad, ahora que ya tenemos una base sobre la que mejorar vamos a probar con el nuevo algoritmo de compresión de backups ZSTD.
BACKUP DATABASE [StackOverflow2013]
TO DISK = N'C:\Program Files\...\StackOverflow2013_ZSTD.bak'
WITH NOFORMAT, NOINIT, SKIP, NOREWIND, NOUNLOAD, COMPRESSION (ALGORITHM = ZSTD), STATS = 10;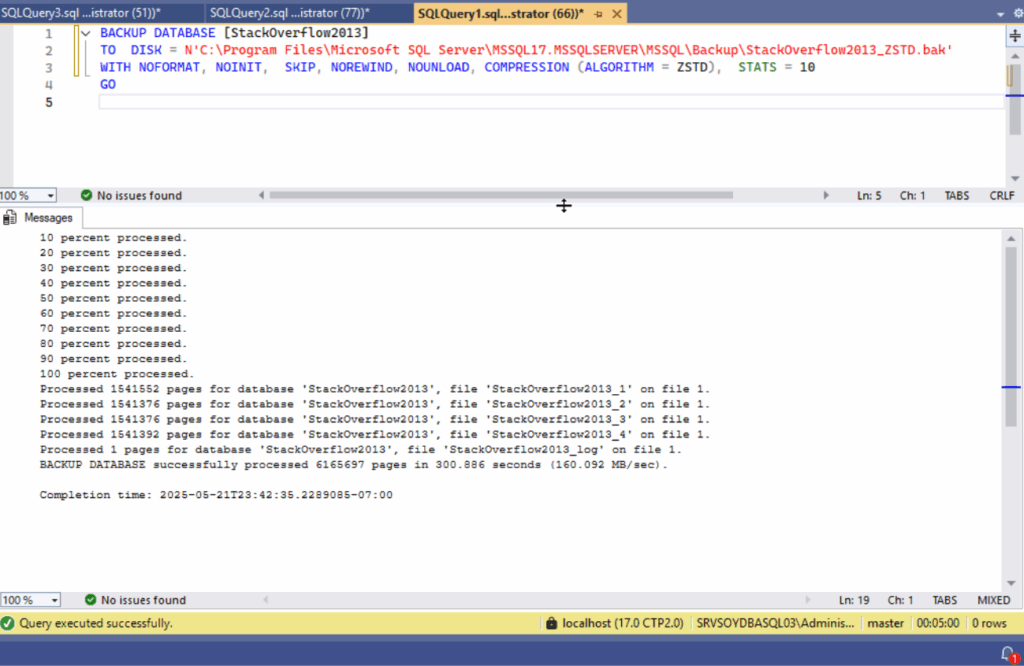
Resultados:
- Tiempo total: 300 segundos
- Velocidad media: 160.092 MB/seg
- Tamaño comprimido: 14.51 GB
Sí, has leído bien: más rápido y más comprimido. Porque para eso se inventan los algoritmos modernos, no para rellenar documentación técnica.
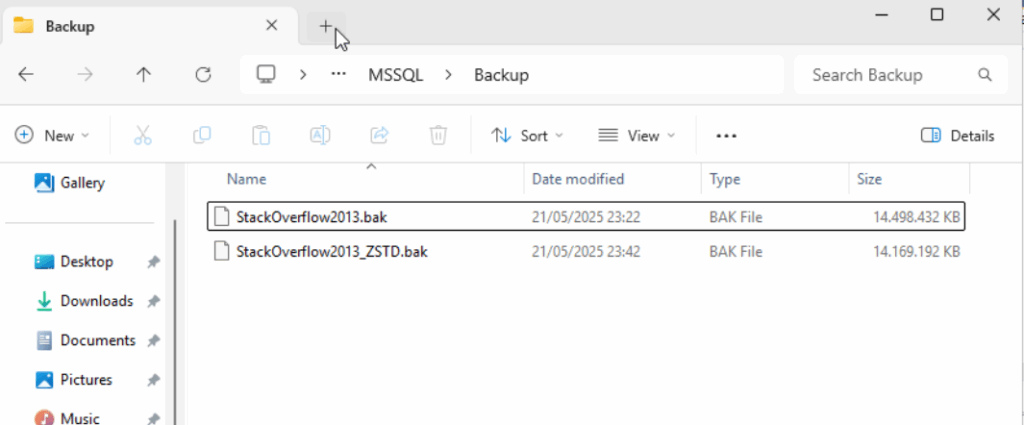
¿Y el espacio en disco? ¿Realmente hay más compresión?
Aquí no hay opiniones: hay archivos .bak. Si miramos los tamaños de las copias que acabamos de hacer estos son los datos:
- MS_XPRESS: 14.498.432 KB
- ZSTD: 14.169.192 KB
En torno a 329 MB menos por backup. Insisto: suma eso en entornos de alta frecuencia y multiinstancia, y deja que el almacenamiento te dé las gracias.
Restauraciones
También he restaurado ambas copias para verificar si hay diferencias apreciables en el proceso inverso. Al fin y al cabo, para eso hacemos backups. Y normalmente, cuando restauramos una copia de seguridad lo hacemos con prisa, no me preguntes por qué.
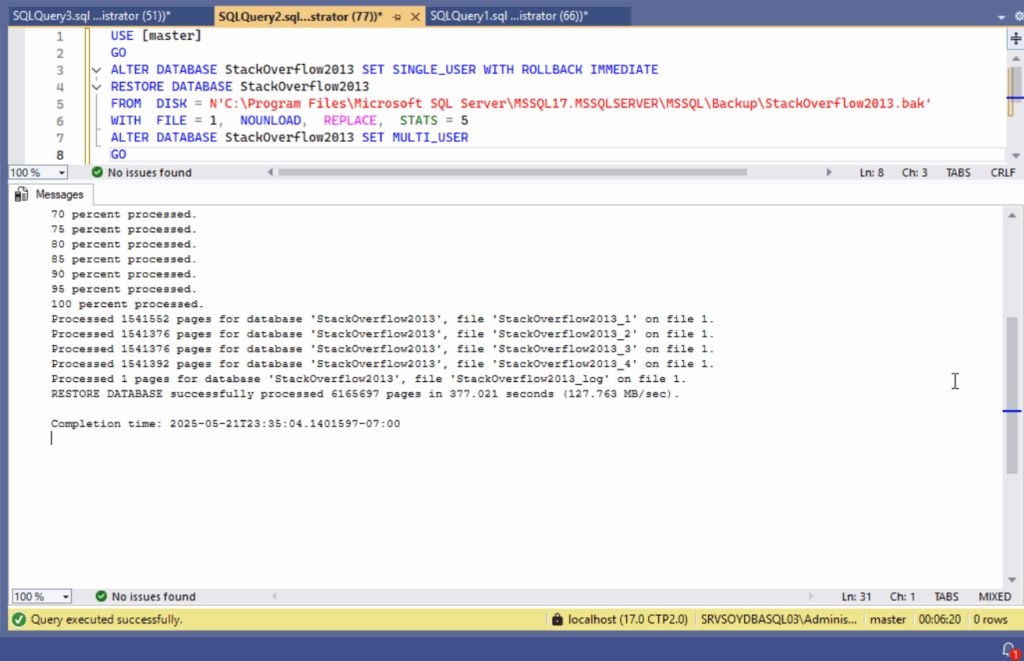
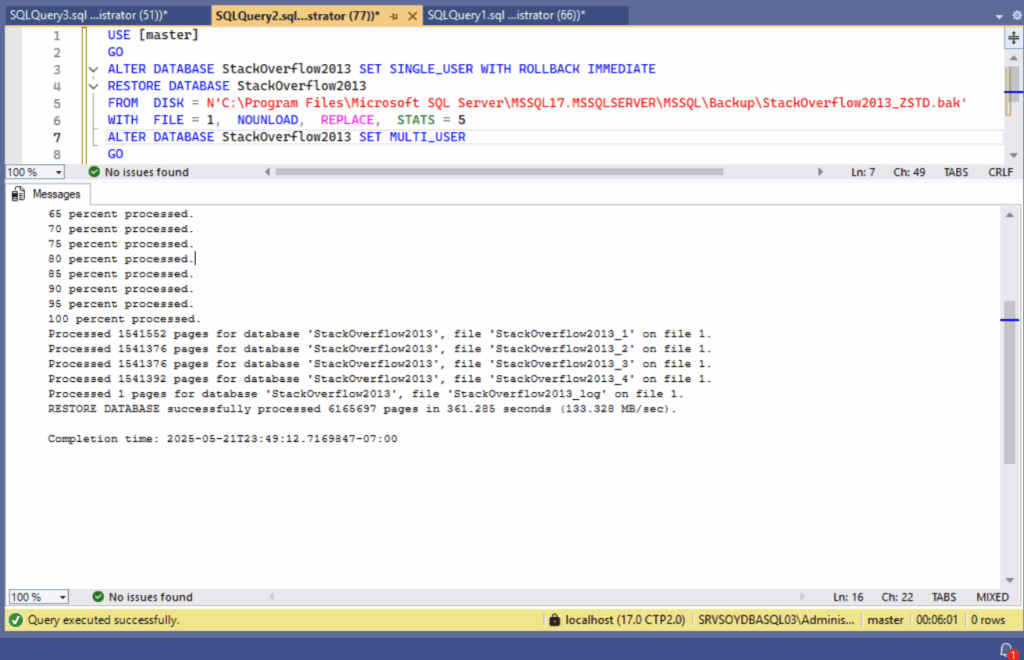
En este sentido, la copia con el algoritmo de compresión tradicional MS_XPRESS ha tardado 377 segundos, restaurando a 127.763 MB/seg. Por su parte, la copia con el nuevo algoritmo ZSTD se ha restaurado en 361 segundos a una media de 133.328 MB/seg.
Una diferencia de rendimiento modesta, pero constante, a favor de ZSTD. No rompe récords, pero definitivamente no es humo.
Relación de compresión
Veamos por último la relación de compresión de nuestras copias. Esto podemos verlo directamente de msdb.dbo.backupset con una sencilla consulta.
SELECT database_name, compression_algorithm, backup_size, compressed_backup_size, backup_size / compressed_backup_size AS CompressRatio
FROM msdb.dbo.backupset
WHERE database_name = 'StackOverflow2013';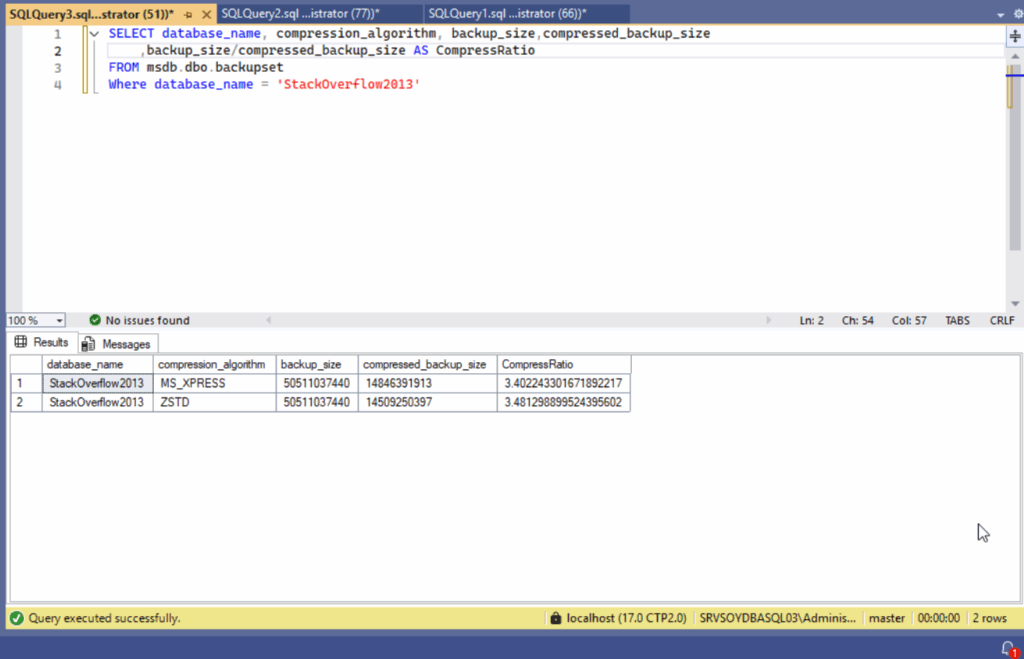
Tampoco estamos ante un milagro, pero la mejora es real. Y si alguien piensa que medio punto en ratio de compresión no importa, que multiplique eso por 500 bases de datos diarias y hablamos. Además, recuerda, el ejemplo que he usado es de los menos favorables para una compresión.
Cómo habilitar la compresión ZSTD (cuando funcione bien)
ZSTD se puede usar de dos formas, la forma explícita que acabamos de ver, indicando el algoritmo en el comando BACKUP WITH COMPRESSION (ALGORITHM = ZSTD) o bien configurando el servidor para usarlo como valor predeterminado. Para eso lo definiremos en la configuración con este comando:
EXEC sp_configure 'backup compression algorithm', 3;
RECONFIGURE;Ahora bien, aquí viene la parte divertida (léase con sarcasmo): actualmente hay un bug conocido en la configuración global. Es decir, puedes especificarlo manualmente sin problema, pero si intentas poner ZSTD como predeterminado a través del sp_configure, el sistema puede ignorar olímpicamente. No lo decimos nosotros, lo dice la propia documentación oficial de Microsoft en letras púrpuras. Nada grave sabiendo que aun es una versión preliminar.
Así que por ahora, mejor dejar ese WITH COMPRESSION (ALGORITHM = ZSTD) bien escrito en los scripts de mantenimiento y olvidarse de configuraciones globales hasta que alguien en Redmond se acuerde de arreglarlo antes de la disponibilidad general del producto.
Conclusión
ZSTD ha llegado a SQL Server y no como un simple añadido, sino como una alternativa seria al clásico MS_XPRESS. Mejora el rendimiento, reduce el tamaño y lo hace sin pedir permiso ni romper nada. ¿Es perfecto? No. ¿Está listo para producción? Aún no, está en preview. ¿Vale la pena probarlo? Sin duda.
En mis pruebas ha demostrado ser más eficiente, más rápido y ligeramente más eficaz en términos de compresión. Y si Microsoft arregla ese problemilla con la configuración global, puede convertirse en el nuevo estándar para backup en SQL Server.
Así que, si estás probando SQL Server 2025, ya estás tardando en incluir ZSTD en tus scripts. Y si aún sigues con backups sin compresión porque “es más seguro así”, quizás también sigas usando cintas magnéticas. En fin.
Yo por mi parte, ya lo tengo apuntado en el check de “cosas que sí merecen la pena en esta versión”. Habrá que ver si termina estando disponible en SQL Server Standard o solo en las versiones Enterprise.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!