Llevamos años viendo aplicaciones que convierten la busqueda de textos en una trituradora de CPU. El usuario escribe tres palabras, la capa de aplicación las trocea como puede, el ORM genera una consulta digna de un informe forense y SQL Server acaba haciendo lo que siempre hace, intentar salvarnos de nuestras propias decisiones. A veces lo consigue. A veces no. Y cuando no lo consigue, alguien abre una incidencia diciendo que “la base de datos va lenta”, como si el motor hubiera decidido por iniciativa propia montar un festival de LIKE ‘%texto%’.
La búsqueda de texto completo ha sido durante mucho tiempo nuestra herramienta principal para resolver este tipo de problemas. Los índices full-text permiten buscar términos dentro de columnas extensas, ordenar por relevancia y evitar que cada búsqueda acabe en un escaneo indecente. Ya hablé de esto con más detalle en el artículo sobre índices de texto completo o full-text indexes, porque siguen siendo una herramienta muy válida cuando necesitamos precisión léxica.
Pero ahora tenemos otro actor en escena: la búsqueda vectorial. SQL Server 2025, Azure SQL Database y SQL Database en Fabric incorporan capacidades nativas para trabajar con vectores, calcular distancias y ejecutar búsquedas aproximadas de vecinos más cercanos mediante VECTOR_SEARCH. En SQL Server 2025 estas capacidades están en vista previa y requieren habilitar PREVIEW_FEATURES. Además, Microsoft documenta que la versión más reciente de los índices vectoriales está disponible actualmente en Azure SQL Database y SQL Database en Microsoft Fabric.
La tentación evidente consiste en pensar que la búsqueda vectorial sustituye al full-text. Es una conclusión cómoda y moderna, pero equivocada. Es muy de presentación ejecutiva, lo que debería hacernos sospechar inmediatamente. La realidad es bastante más interesante, full-text y vectores resuelven problemas distintos, y la búsqueda híbrida aparece precisamente cuando dejamos de tratarlos como enemigos.
Antes de lanzarnos a escribir T-SQL como si no hubiera mañana, conviene dejar claro el problema de fondo.
La búsqueda híbrida no es IA pegada con cinta americana
La búsqueda híbrida combina una búsqueda léxica tradicional con una búsqueda semántica vectorial y fusiona después ambos conjuntos de resultados mediante una técnica de reordenación. La idea parece sencilla, una rama encuentra coincidencias de palabras con full-text indexes, la otra encuentra documentos semánticamente cercanos mediante comparación de embeddings, y una fase final decide qué documentos merecen aparecer arriba.
La clave está en esa última frase. No basta con ejecutar dos consultas y hacer un UNION. Eso no es búsqueda híbrida. Tampoco basta con sumar una puntuación full-text y una distancia vectorial, porque ambas magnitudes viven en universos matemáticos diferentes. SQL Server no va a convertir una escala relativa de relevancia textual y una distancia de coseno en una verdad universal solo porque usemos alias bonitos.
El full-text devuelve señales de relevancia asociadas a coincidencias lingüísticas. CONTAINSTABLE y FREETEXTTABLE devuelven una columna RANK con valores ordinales entre 0 y 1000, pero esos valores indican orden relativo dentro del conjunto devuelto. Microsoft advierte que el valor real no debe tratarse como una puntuación absoluta y puede variar entre ejecuciones.
La búsqueda vectorial, en cambio, devuelve una distancia. Si usamos coseno, valores más bajos indican mayor cercanía cuando trabajamos con VECTOR_DISTANCE o con la columna distance generada por VECTOR_SEARCH. Esa distancia expresa proximidad geométrica entre embeddings, no coincidencia literal de términos. Comparar directamente ambas señales es como comparar páginas leídas con cuanto agua está lloviendo fuera. Puedes hacerlo, pero no significa nada útil.
Por eso la búsqueda híbrida necesita una fase de fusión por rango. No fusionamos puntuaciones brutas, fusionamos posiciones. Y ahí entra Reciprocal Rank Fusion, más conocido como RRF.
Para entender por qué esto importa tanto, primero hay que asumir que full-text sigue siendo necesario.
Full-text: precisión léxica, no comprensión semántica
Un índice full-text sigue siendo una pieza excelente cuando necesitamos encontrar términos, variantes lingüísticas, prefijos, expresiones ponderadas o documentos donde aparecen palabras concretas. No es una tecnología vieja por no llevar “AI” en el nombre. De hecho, suele ser mucho más útil que una demo de embeddings cuando el usuario busca un código, una referencia contractual, un identificador de error o una cláusula exacta.
Imaginemos una base de conocimiento de soporte. Si el usuario busca OOM-802, lo normal es que quiera documentos que contengan OOM-802. No quiere artículos “conceptualmente relacionados con problemas de memoria”. Quiere ese código. Exactamente ese. Si le devolvemos un documento sobre “optimización general de memoria en servidores de aplicaciones” porque está cerca en el espacio vectorial, hemos hecho una búsqueda muy sofisticada y muy inútil. Todo muy moderno, todo muy mal.
Búsqueda de texto completo
Aquí full-text brilla. CONTAINSTABLE permite buscar en una columna indexada y obtener una lista ordenada por relevancia. Además, podemos limitar el volumen con el parámetro top_n_by_rank, algo especialmente importante cuando la condición puede devolver decenas o cientos de miles de filas. La documentación de Microsoft indica que limitar resultados con top_n_by_rank puede mejorar drásticamente el rendimiento, porque SQL Server ordena las coincidencias por rango y devuelve solo las primeras.
Esto no significa que full-text entienda el significado. Si buscamos “vehículo económico”, no podemos asumir que devuelva “coche barato”. Puede haber cierta ayuda lingüística según idioma, tesauro y configuración, pero no estamos ante comprensión semántica general. Full-text trabaja con términos, proximidad, formas lingüísticas y ranking textual. Los embeddings trabajan con representación numérica del significado. Mezclarlos sin entender esta diferencia es una forma estupenda de construir una solución que falle justo cuando el usuario la necesite.
En artículos anteriores del blog ya traté los índices de texto completo desde la perspectiva del DBA. Esa base sigue siendo necesaria. La búsqueda híbrida no elimina el conocimiento de full-text, lo potencia. Si alguien quiere saltar directamente a vectores sin entender CONTAINS, FREETEXT, CONTAINSTABLE, catálogos full-text, stopwords y ranking, adelante. Pero luego no vale llorar.
La otra mitad del problema está en la búsqueda semántica.
Vectores: significado aproximado, no magia contractual
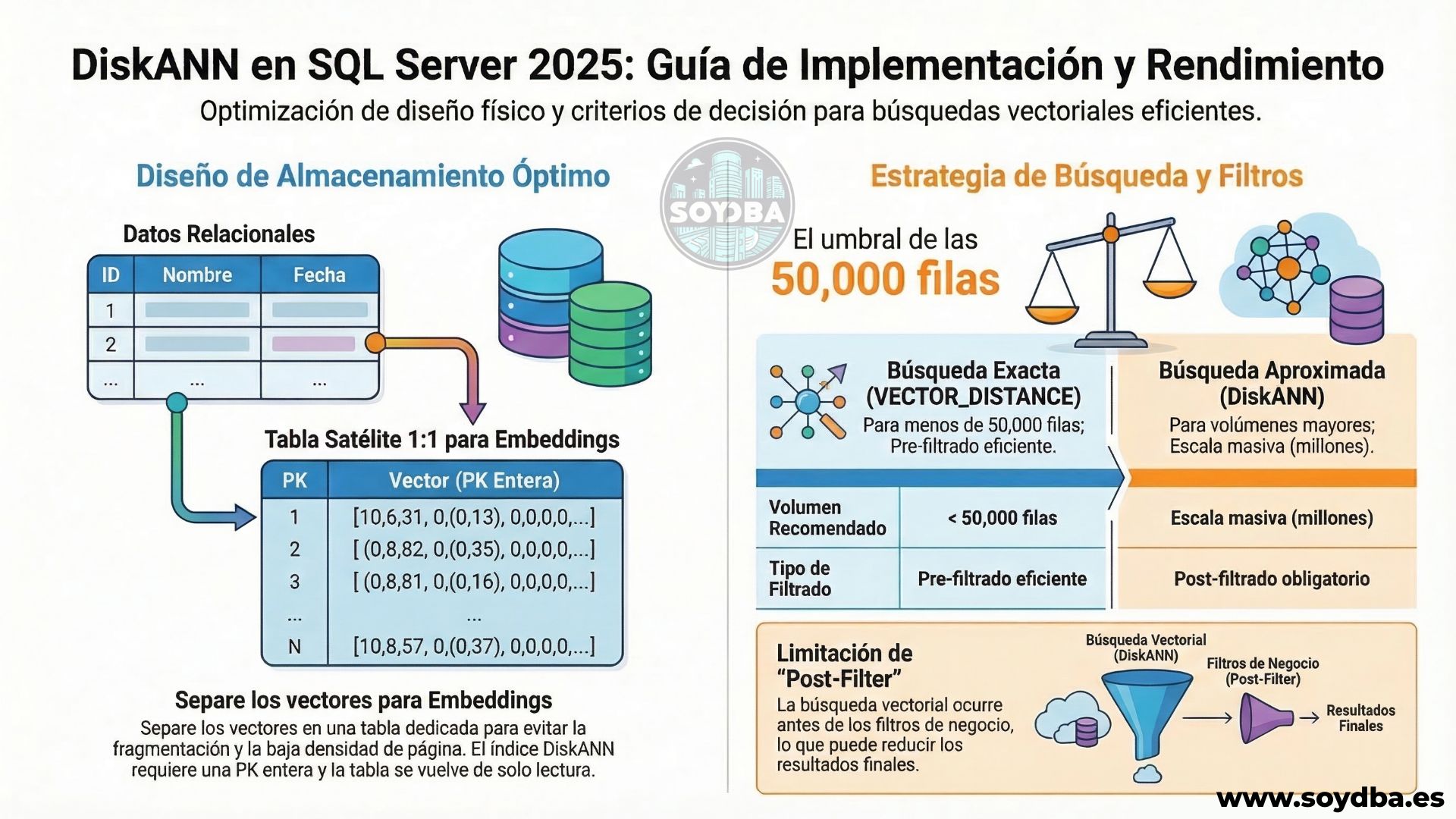
Un embedding representa un texto como un vector numérico. La idea práctica es que textos con significado parecido generen vectores cercanos. A partir de ahí, podemos medir distancias mediante coseno, producto escalar o distancia euclídea, y recuperar los documentos más cercanos al vector de consulta. SQL Server permite realizar búsquedas exactas con VECTOR_DISTANCE, calculando la distancia entre el vector de búsqueda y los vectores almacenados. Microsoft describe este enfoque exacto como un cálculo exhaustivo que garantiza recuperar los vecinos más cercanos, aunque puede resultar costoso en conjuntos grandes.
La búsqueda exacta tiene una ventaja fundamental, no aproxima. Calcula. Si filtramos primero por cliente, estado, idioma, producto o fecha, y después aplicamos VECTOR_DISTANCE sobre un conjunto pequeño, podemos obtener resultados muy buenos sin necesidad de crear un índice vectorial. Esta estrategia suele ser más sensata de lo que parece, sobre todo en tablas medianas o en escenarios donde los filtros relacionales reducen mucho el número de candidatos.
La búsqueda aproximada, por su parte, usa estructuras especializadas para evitar comparar contra todos los vectores. En SQL Server y Azure SQL hablamos de VECTOR_SEARCH, que busca vectores similares mediante un algoritmo aproximado de vecinos más cercanos. Con la versión más reciente de los índices vectoriales, la sintaxis recomendada usa SELECT TOP (N) WITH APPROXIMATE y deja atrás el antiguo parámetro TOP_N, que Microsoft marca como obsoleto para índices recientes.
Índices vectoriales: grafos de embeddings
Aquí aparece DiskANN. Un índice vectorial de tipo DiskANN acelera la recuperación aproximada navegando una estructura de grafo pensada para localizar vecinos cercanos sin recorrer todo el conjunto. Eso tiene un coste. Hay mantenimiento, requisitos, restricciones y decisiones de diseño. No creamos un índice vectorial porque la palabra “vector” aparezca en una reunión. Lo creamos cuando el volumen, la latencia esperada y el patrón de consulta lo justifican.
En el artículo sobre DiskANN y búsqueda vectorial en SQL Server 2025 ya expliqué por qué no conviene indexar vectores en cualquier tabla. Esta recomendación sigue siendo válida. Si tienes 3.000 filas y filtros buenos, probablemente VECTOR_DISTANCE con búsqueda exacta te dé una solución más simple, más predecible y más fácil de razonar. La complejidad innecesaria siempre encuentra la forma de facturarse más tarde.
Como véis, la búsqueda semántica resuelve muy bien consultas ambiguas. “Portátil ligero para viajar”, “incidencia parecida a error de memoria”, “cliente molesto por retrasos recurrentes” o “documentación sobre migración sin parada” son ejemplos donde la coincidencia literal se queda corta. Pero esa misma flexibilidad puede volverse peligrosa cuando la consulta contiene un literal crítico.
Por eso necesitamos una arquitectura híbrida.
El patrón correcto: recuperar candidatos y fusionar rangos
La búsqueda híbrida no debería ejecutar una búsqueda vectorial contra toda la tabla y otra full-text sin límite para después cruzar todo alegremente. Eso solo consumiría recursos a lo loco. El patrón correcto consiste en recuperar un número razonable de candidatos por cada rama y fusionar después esos candidatos mediante un ranking controlado.
La rama léxica puede usar CONTAINSTABLE o FREETEXTTABLE, según queramos una búsqueda más precisa o más lingüística. Para códigos, identificadores, términos técnicos y mensajes de error, normalmente prefiero CONTAINSTABLE. Para búsquedas más naturales o descriptivas, FREETEXTTABLE puede encajar mejor. No son intercambiables, aunque en muchas aplicaciones se usen como si lo fueran. Luego nos extraña que el buscador parezca tener resaca.
La rama semántica puede usar VECTOR_DISTANCE o VECTOR_SEARCH. Si queremos una búsqueda exacta sobre pocos candidatos, VECTOR_DISTANCE es una buena opción. Si tenemos cientos de miles o millones de embeddings, baja tolerancia a latencia y un índice vectorial adecuado, VECTOR_SEARCH pasa a tener sentido. Microsoft también documenta que los índices vectoriales recientes aplican predicados de WHERE durante el proceso de búsqueda vectorial mediante filtrado iterativo, no simplemente después de recuperar vecinos, pero eso, de momento solo está en Azure.
Unir resultados
La fase final no debe sumar RANK full-text con distancia vectorial. Debe convertir cada lista en posiciones ordinales y aplicar RRF. La fórmula general es sencilla:
score(d) = Σ 1 / (k + rank_i(d))
Donde rank_i(d) es la posición del documento d en la lista i, y k es una constante de suavizado. Si un documento no aparece en una rama, esa rama aporta cero. No aporta un rango inventado de diez mil, salvo que queramos aplicar una penalización heurística deliberada. RRF canónico suma contribuciones de listas donde el documento existe, lo demás ya es cocina propia.
El valor k = 60 aparece a menudo como constante práctica. No es una ley divina, ni una recomendación que debamos tatuarnos pero si podríamos decir que es un estándar del mercado. Un k más bajo da más peso a las primeras posiciones; un k más alto suaviza la diferencia entre posiciones. En buscadores internos suelo empezar con 60, medir, revisar consultas reales y ajustar. Sí, medir. Esa costumbre extravagante que a veces evita reuniones.
Vamos a bajarlo a código.
Modelo de datos para un escenario realista
Supongamos una tabla de tickets de soporte. Cada ticket tiene una descripción textual, metadatos relacionales y un embedding generado a partir del contenido que queremos buscar. No voy a centrarme aquí en la generación del embedding porque ya traté las búsquedas semánticas con IA en SQL Server 2025 en otro artículo, y además dejé ejemplos prácticos en YouTube para quien quiera ver el flujo completo con más calma.
La tabla podría tener esta forma simplificada:
CREATE TABLE dbo.SoporteTickets
(
TicketID BIGINT NOT NULL,
ClienteID INT NOT NULL,
ProductoID INT NOT NULL,
Estado TINYINT NOT NULL,
FechaCreacion DATETIME2(3) NOT NULL,
Titulo NVARCHAR(250) NOT NULL,
DescripcionProblema NVARCHAR(MAX) NOT NULL,
EmbeddingProblema VECTOR(1536) NOT NULL,
CONSTRAINT PK_SoporteTickets
PRIMARY KEY CLUSTERED (TicketID)
);
GO
CREATE NONCLUSTERED INDEX IX_SoporteTickets_Filtros
ON dbo.SoporteTickets
(
ClienteID,
ProductoID,
Estado,
FechaCreacion
)
INCLUDE (Titulo);
GOEl índice relacional no es decorativo. En una arquitectura híbrida seria, los filtros siguen importando. Si buscamos tickets de un cliente concreto, de un producto concreto o de un rango temporal, no queremos que la parte vectorial se comporte como un turista perdido recorriendo toda la ciudad. Queremos acotar el problema antes de calcular distancias.
El índice full-text iría sobre las columnas textuales relevantes. En producción hay que cuidar idioma, catálogos, stoplists y fragmentación del índice full-text, pero el esqueleto sería este:
CREATE FULLTEXT CATALOG FTC_Soporte AS DEFAULT;
GO
CREATE FULLTEXT INDEX ON dbo.SoporteTickets
(
Titulo LANGUAGE 3082,
DescripcionProblema LANGUAGE 3082
)
KEY INDEX PK_SoporteTickets
WITH CHANGE_TRACKING AUTO;
GOEl LANGUAGE 3082 corresponde al español. En entornos multidioma, este detalle se complica bastante. Un catálogo global con textos mezclados en cinco idiomas y una sola configuración lingüística no es internacionalización; es una ruleta. Si el negocio necesita búsquedas multidioma, hay que diseñar para ello, no rezar para que el motor “lo entienda”.
Para la parte vectorial, un índice DiskANN puede crearse así cuando el volumen lo justifique:
CREATE VECTOR INDEX IX_SoporteTickets_EmbeddingProblema
ON dbo.SoporteTickets (EmbeddingProblema)
WITH
(
METRIC = 'COSINE',
TYPE = 'DISKANN'
);
GOLos índices vectoriales recientes exigen al menos 100 filas con vectores no nulos antes de poder crearse, requieren una clave primaria clustered y tienen limitaciones actuales como ausencia de particionado, restricciones con TRUNCATE TABLE, no replicarse a suscriptores y problemas de despliegue directo con DacPac o BACPAC porque el índice se crea antes de cargar datos.
Esto ya nos da una pista importante: no hablamos de un índice cualquiera. No es un IX_Tabla_Campo que añadimos a las tres de la tarde para callar una alerta. Un índice vectorial afecta al ciclo de vida de la tabla, al despliegue, al mantenimiento y a los procesos de carga. Si el plan de despliegue de tu base de datos ignora esto, no tienes un plan; tienes un problema.
Ahora sí, veamos una búsqueda híbrida exacta.
Búsqueda híbrida exacta con VECTOR_DISTANCE
El primer patrón usa VECTOR_DISTANCE. Es el más fácil de razonar porque calcula distancias reales contra los candidatos considerados. Conviene usarlo cuando el conjunto final no es enorme, cuando los filtros relacionales son selectivos o cuando la precisión importa más que la latencia extrema.
El siguiente ejemplo recibe una consulta textual, genera su embedding y combina la rama semántica con la rama full-text. Limitamos ambas ramas para no fusionar medio millón de filas, es la forma de decirle a SQL “no hagas barbaridades”.
DECLARE @texto_busqueda NVARCHAR(4000) = N'fallo de memoria OOM-802 después de actualizar el agente';
DECLARE @vector_busqueda VECTOR(1536) =
AI_GENERATE_EMBEDDINGS(@texto_busqueda USE MODEL Ada2Embeddings);
DECLARE @cliente_id INT = 42;
DECLARE @producto_id INT = 7;
DECLARE @estado_abierto TINYINT = 1;
DECLARE @top_semantico INT = 100;
DECLARE @top_lexico INT = 100;
DECLARE @top_final INT = 20;
DECLARE @rrf_k FLOAT = 60.0;
WITH CandidatosFiltrados AS
(
SELECT
T.TicketID,
T.Titulo,
T.DescripcionProblema,
T.EmbeddingProblema,
T.FechaCreacion
FROM dbo.SoporteTickets AS T
WHERE T.ClienteID = @cliente_id
AND T.ProductoID = @producto_id
AND T.Estado = @estado_abierto
),
RamaSemanticaBase AS
(
SELECT TOP (@top_semantico)
C.TicketID,
VECTOR_DISTANCE('cosine', C.EmbeddingProblema, @vector_busqueda) AS DistanciaCoseno
FROM CandidatosFiltrados AS C
ORDER BY
VECTOR_DISTANCE('cosine', C.EmbeddingProblema, @vector_busqueda)
),
RamaSemantica AS
(
SELECT
S.TicketID,
S.DistanciaCoseno,
ROW_NUMBER() OVER (ORDER BY S.DistanciaCoseno ASC, S.TicketID ASC) AS RangoSemantico
FROM RamaSemanticaBase AS S
),
RamaLexica AS
(
SELECT
FT.[KEY] AS TicketID,
FT.[RANK] AS RankFullText,
ROW_NUMBER() OVER (ORDER BY FT.[RANK] DESC, FT.[KEY] ASC) AS RangoLexico
FROM CONTAINSTABLE
(
dbo.SoporteTickets,
(Titulo, DescripcionProblema),
N'"OOM-802" OR FORMSOF(INFLECTIONAL, "memoria")',
100
) AS FT
INNER JOIN dbo.SoporteTickets AS T
ON T.TicketID = FT.[KEY]
WHERE T.ClienteID = @cliente_id
AND T.ProductoID = @producto_id
AND T.Estado = @estado_abierto
),
FusionRRF AS
(
SELECT
COALESCE(S.TicketID, L.TicketID) AS TicketID,
S.RangoSemantico,
L.RangoLexico,
S.DistanciaCoseno,
L.RankFullText,
COALESCE(1.0 / (@rrf_k + S.RangoSemantico), 0.0) +
COALESCE(1.0 / (@rrf_k + L.RangoLexico), 0.0) AS PuntuacionRRF
FROM RamaSemantica AS S
FULL OUTER JOIN RamaLexica AS L
ON L.TicketID = S.TicketID
),
SELECT TOP (@top_final)
F.TicketID,
T.Titulo,
T.FechaCreacion,
F.RangoSemantico,
F.RangoLexico,
F.DistanciaCoseno,
F.RankFullText,
F.PuntuacionRRF
FROM FusionRRF AS F
INNER JOIN dbo.SoporteTickets AS T
ON T.TicketID = F.TicketID
ORDER BY
F.PuntuacionRRF DESC,
COALESCE(F.RangoLexico, 2147483647) ASC,
COALESCE(F.RangoSemantico, 2147483647) ASC,
F.TicketID ASC;Hay varias decisiones intencionadas aquí. La rama semántica no calcula distancia contra toda la tabla, sino contra CandidatosFiltrados. Esto permite que el optimizador use índices relacionales antes de aplicar la parte matemática. Si el cliente tiene 4.000 tickets abiertos del producto, calcular 4.000 distancias puede ser razonable. Si tiene 40 millones, probablemente estamos diseñando otra cosa.
La rama léxica usa CONTAINSTABLE con top_n_by_rank. Ese cuarto parámetro limita el número de resultados full-text devueltos. No quiero traer todos los tickets que contengan “memoria” para después descubrir que el usuario solo verá 20 filas. Esa es la diferencia entre una consulta y un castigo.
La fusión usa FULL OUTER JOIN porque un documento puede aparecer solo en la rama semántica o solo en la rama léxica. Después, COALESCE(1.0 / (@rrf_k + rango), 0.0) suma cero cuando el documento no aparece en una rama. Esto es importante, no inventamos rangos artificiales. Si queremos penalizar más o menos los resultados huérfanos, podemos hacerlo, pero entonces debemos reconocer que estamos introduciendo una heurística adicional.
También ordeno por criterios secundarios. En producción, los empates ocurren. Si no defines desempates, el motor puede devolverte órdenes distintos entre ejecuciones. Y cuando el usuario dice “ayer salía primero”, a nadie le divierte explicar que una ordenación parcial no garantiza estabilidad. Bueno, a nadie normal, que yo estoy aquí preparando el artículo más largo de todos los que he escrito para explicaros eso.
Este patrón exacto es muy útil cuando trabajamos con filtros fuertes. Pero si el volumen semántico es grande y necesitamos latencia baja, toca pasar a búsqueda aproximada.
Búsqueda híbrida aproximada con VECTOR_SEARCH
VECTOR_SEARCH representa el patrón de búsqueda vectorial aproximada. Con índices vectoriales recientes, la sintaxis exige SELECT TOP (N) WITH APPROXIMATE y ordenación ascendente por la columna distance, que es la única clave de ordenación válida para los resultados aproximados. Si existe un índice ANN compatible con la misma métrica y columna, puede usarse, si no existe, el motor puede recurrir a kNN y emitir una advertencia.
Una versión híbrida aproximada puede quedar así:
DECLARE @texto_busqueda NVARCHAR(4000) = N'fallo de memoria OOM-802 después de actualizar el agente';
DECLARE @vector_busqueda VECTOR(1536) =
AI_GENERATE_EMBEDDINGS(@texto_busqueda USE MODEL Ada2Embeddings);
DECLARE @cliente_id INT = 42;
DECLARE @producto_id INT = 7;
DECLARE @estado_abierto TINYINT = 1;
DECLARE @top_semantico INT = 100;
DECLARE @top_lexico INT = 100;
DECLARE @top_final INT = 20;
DECLARE @rrf_k FLOAT = 60.0;
WITH RamaSemanticaBase AS
(
SELECT TOP (@top_semantico) WITH APPROXIMATE
T.TicketID,
VS.distance AS DistanciaCoseno
FROM VECTOR_SEARCH
(
TABLE = dbo.SoporteTickets AS T,
COLUMN = EmbeddingProblema,
SIMILAR_TO = @vector_busqueda,
METRIC = 'cosine'
) AS VS
WHERE T.ClienteID = @cliente_id
AND T.ProductoID = @producto_id
AND T.Estado = @estado_abierto
ORDER BY VS.distance ASC
),
RamaSemantica AS
(
SELECT
S.TicketID,
S.DistanciaCoseno,
ROW_NUMBER() OVER (ORDER BY S.DistanciaCoseno ASC, S.TicketID ASC) AS RangoSemantico
FROM RamaSemanticaBase AS S
),
RamaLexica AS
(
SELECT
FT.[KEY] AS TicketID,
FT.[RANK] AS RankFullText,
ROW_NUMBER() OVER (ORDER BY FT.[RANK] DESC, FT.[KEY] ASC) AS RangoLexico
FROM CONTAINSTABLE
(
dbo.SoporteTickets,
(Titulo, DescripcionProblema),
N'"OOM-802" OR FORMSOF(INFLECTIONAL, "memoria")',
100
) AS FT
INNER JOIN dbo.SoporteTickets AS T
ON T.TicketID = FT.[KEY]
WHERE T.ClienteID = @cliente_id
AND T.ProductoID = @producto_id
AND T.Estado = @estado_abierto
),
FusionRRF AS
(
SELECT
COALESCE(S.TicketID, L.TicketID) AS TicketID,
S.RangoSemantico,
L.RangoLexico,
S.DistanciaCoseno,
L.RankFullText,
COALESCE(1.0 / (@rrf_k + S.RangoSemantico), 0.0) +
COALESCE(1.0 / (@rrf_k + L.RangoLexico), 0.0) AS PuntuacionRRF
FROM RamaSemantica AS S
FULL OUTER JOIN RamaLexica AS L
ON L.TicketID = S.TicketID
),
SELECT TOP (@top_final)
F.TicketID,
T.Titulo,
T.FechaCreacion,
F.RangoSemantico,
F.RangoLexico,
F.DistanciaCoseno,
F.RankFullText,
F.PuntuacionRRF
FROM FusionRRF AS F
INNER JOIN dbo.SoporteTickets AS T
ON T.TicketID = F.TicketID
ORDER BY
F.PuntuacionRRF DESC,
COALESCE(F.RangoLexico, 2147483647) ASC,
COALESCE(F.RangoSemantico, 2147483647) ASC,
F.TicketID ASC;Este ejemplo es parecido al anterior, pero cambia la rama semántica. Ahora usamos VECTOR_SEARCH, que devuelve la columna distance. La consulta solicita explícitamente resultados aproximados con WITH APPROXIMATE. Esto no es un adorno sintáctico, en índices recientes, Microsoft separa claramente la búsqueda aproximada de la exacta mediante esta sintaxis.
La presencia del WHERE dentro de la rama semántica también importa. En versiones recientes de índices vectoriales, Microsoft documenta filtrado iterativo, es decir, los predicados se aplican durante el proceso de búsqueda vectorial, no únicamente después. En versiones antiguas, los filtros podían aplicarse solo después de recuperar vecinos, lo que provocaba resultados vacíos o incompletos si los primeros vecinos no cumplían el filtro. Esta diferencia no es teórica, afecta directamente a la calidad del resultado.
Si trabajas con índices vectoriales antiguos, conviene migrarlos. Microsoft indica que los índices creados con estructuras anteriores se mantienen en la versión actual, pero quedarán retirados en una versión futura, y para obtener las capacidades recientes hay que eliminar y recrear el índice. La propia DMV sys.vector_indexes, junto con sys.indexes y sys.tables, permite consultar la versión registrada en los parámetros de construcción.
Esto introduce una responsabilidad nueva para el DBA. Ya no basta con saber si el índice existe. Hay que saber qué versión tiene, qué sintaxis admite, cómo se comporta con filtros y si soporta mantenimiento DML completo. El “tenemos índice vectorial” se parece demasiado al “tenemos backup”: la frase tranquiliza hasta que preguntas cuándo se ha probado.
RRF con pesos: cuando no todas las señales valen lo mismo
RRF básico da el mismo peso a cada rama. Eso suele ser un buen punto de partida, porque evita discusiones prematuras. Pero no todos los dominios tienen la misma necesidad de precisión literal y contexto semántico. En una base de conocimiento técnica, los códigos de error, nombres de procedimiento, versiones y referencias internas suelen pesar mucho. En un catálogo de productos o una búsqueda documental abierta, la semántica puede tener más protagonismo.
Podemos introducir pesos sin romper la estructura:
DECLARE @peso_semantico FLOAT = 0.65;
DECLARE @peso_lexico FLOAT = 0.35;
DECLARE @rrf_k FLOAT = 60.0;
SELECT
COALESCE(S.TicketID, L.TicketID) AS TicketID,
COALESCE(@peso_semantico * (1.0 / (@rrf_k + S.RangoSemantico)), 0.0) +
COALESCE(@peso_lexico * (1.0 / (@rrf_k + L.RangoLexico)), 0.0) AS PuntuacionRRF
FROM RamaSemantica AS S
FULL OUTER JOIN RamaLexica AS L
ON L.TicketID = S.TicketID
ORDER BY PuntuacionRRF DESC;Esto ya no es RRF puro, sino RRF ponderado. No hay problema, siempre que seamos conscientes de ello. Lo peligroso no es ajustar el algoritmo, lo peligroso es hacerlo sin medir. Si damos demasiado peso a la rama semántica, un literal crítico puede quedar enterrado bajo documentos conceptualmente parecidos. Si damos demasiado peso a la rama léxica, perdemos recall semántico y volvemos al mundo de “no encuentro coche barato porque el documento dice vehículo económico”.
En entornos serios conviene registrar consultas reales, resultados seleccionados, clics, aperturas, tiempo hasta resolver la incidencia y feedback explícito si existe. Después podemos comparar configuraciones de pesos, tamaños de candidatos y valores de k. La relevancia no se calibra en una pizarra. Se calibra con datos y pruebas. Qué concepto tan revolucionario.
También podemos modificar pesos en función de la consulta. Si detectamos patrones de códigos, identificadores, GUIDs, números de versión o referencias internas, podemos favorecer full-text. Si la consulta es larga, descriptiva y sin literales críticos, podemos favorecer semántica. Este tipo de adaptación suele dar mejores resultados que una configuración fija para todos los casos.
La detección no tiene por qué ser perfecta. Basta con aplicar reglas prudentes. Una consulta con OOM-802, SQLSTATE 40001, KB500 o Procedure dbo.X probablemente necesita más precisión léxica. Una consulta como “el agente se queda bloqueado después de actualizar y consume mucha memoria” puede beneficiarse más del vector. El usuario no nos entrega una intención formal; nos entrega una frase. Nuestro trabajo consiste en no destrozarla.
El tamaño de los candidatos importa más de lo que parece
Uno de los errores más comunes en búsqueda híbrida consiste en recuperar pocos candidatos por rama. Si pedimos top 10 semántico y top 10 léxico para devolver top 10 final, apenas damos margen al algoritmo de fusión. RRF necesita espacio para encontrar documentos que quizá no sean número uno en ninguna rama, pero sí sean buenos en ambas.
Un documento que aparece en posición 12 en la rama semántica y posición 8 en la rama léxica puede ser mucho mejor resultado global que otro que aparece en posición 1 semántica y no aparece en léxica. Si solo recuperamos diez candidatos por rama, el primero puede sobrevivir y el segundo puede ni siquiera existir en la fusión. El algoritmo no puede ordenar documentos que nunca le hemos dado.
Por eso suelo trabajar con una ventana de candidatos bastante mayor que el resultado final. Si voy a mostrar 20 resultados, empezar con 100 o 200 por rama suele ser razonable. Luego hay que medir. No es lo mismo una tabla de tickets internos que una base documental de millones de artículos. Tampoco es lo mismo una búsqueda con filtros por cliente que un buscador global público.
El parámetro top_n_by_rank de full-text ayuda en la rama léxica. En la rama vectorial aproximada, TOP (N) WITH APPROXIMATE marca la ventana semántica. En la rama exacta con VECTOR_DISTANCE, TOP (N) limita el cálculo ordenado final, aunque el coste previo depende de cuántas filas sobrevivan a los filtros relacionales.
Aquí conviene vigilar planes de ejecución, memoria concedida, spills, paralelismo y lecturas lógicas. También hay que observar la distribución de distancias. Si todos los documentos tienen distancias muy parecidas, la señal semántica quizá no discrimina bien. Si el full-text devuelve rankings muy planos, la parte léxica quizá necesita mejorar sintaxis, tesauro, stopwords o normalización de contenido.
La búsqueda híbrida no elimina el tuning. Le añade dimensiones nuevas. Por si alguien echaba de menos complicarse la vida.
Exact search frente a ANN: elegir sin postureo
La búsqueda exacta con VECTOR_DISTANCE calcula distancias y ordena. Es simple, precisa y fácil de auditar. Si el conjunto candidato es pequeño, suele ser una gran elección. También es buena para validación, pruebas de calidad y comparación contra la búsqueda aproximada. En escenarios donde la exactitud es crítica, tener un modo exacto ayuda a detectar pérdida de recall introducida por ANN.
La búsqueda aproximada con VECTOR_SEARCH sacrifica exactitud teórica por velocidad. No tiene nada de malo. Muchos sistemas de búsqueda funcionan así porque el usuario necesita respuestas rápidas y suficientemente buenas. El problema aparece cuando alguien vende “aproximado” como si significara “igual pero más rápido”. No. Significa aproximado. La palabra está ahí, generosamente visible.
Microsoft documenta que VECTOR_SEARCH utiliza búsqueda aproximada de vecinos más cercanos, y que con índices recientes el optimizador puede decidir entre usar DiskANN o búsqueda kNN según las características de la consulta. También indica que, si no hay un índice ANN compatible con la métrica y la columna, se genera una advertencia y se usa kNN.
Esto tiene implicaciones operativas. Si una consulta esperada como aproximada cae a kNN por no tener índice compatible, puede cambiar radicalmente su coste. Si alguien crea el índice con métrica DOT y la consulta usa cosine, no esperes milagros. El motor no va a inventar un índice compatible porque el ticket esté marcado como urgente.
La métrica debe estar alineada con el modelo de embeddings y con la normalización aplicada. En muchos modelos textuales se usa coseno, pero no conviene asumirlo por costumbre. Hay que revisar cómo se generaron los embeddings, si están normalizados y qué distancia recomienda el proveedor o el patrón de uso. El DBA no tiene por qué entrenar el modelo, pero sí debe entender qué está almacenando y cómo se consulta.
Además, el índice vectorial no sustituye los índices relacionales. Microsoft recomienda combinar índices vectoriales con índices tradicionales en columnas usadas por filtros, especialmente cuando el filtrado iterativo puede aprovechar predicados selectivos.
Dicho de otra forma, seguimos necesitando buenos índices B-Tree. La IA no ha derogado la selectividad. Qué disgusto para algunos.
DML, versiones de índice y falsas verdades que caducan
Durante las primeras versiones, una de las limitaciones más agresivas de los índices vectoriales era que las tablas quedaban de solo lectura después de crear el índice. Para permitir DML había que aceptar índices obsoletos mediante configuración, con el riesgo de resultados no actualizados. Esa limitación existió y era importante.
Pero no conviene escribir arquitectura en piedra cuando la tecnología está en vista previa y cambia deprisa. Microsoft documenta que los índices vectoriales creados con la versión más reciente eliminan esa restricción: soportan INSERT, UPDATE, DELETE y MERGE, con mantenimiento automático y en tiempo real del índice. Los cambios son visibles para las búsquedas vectoriales después del commit.
Esto no significa que podamos olvidarnos del mantenimiento. Para reemplazos masivos de datos, por ejemplo al regenerar embeddings con otro modelo, Microsoft recomienda considerar eliminar y recrear el índice después de la carga para mantener calidad de búsqueda predecible. La estructura del índice se construyó con una distribución vectorial determinada; si cambiamos casi todos los embeddings, no deberíamos sorprendernos de que la calidad se resienta.
También siguen existiendo restricciones actuales. No hay soporte de particionado para índices vectoriales, la tabla necesita clave primaria clustered, TRUNCATE TABLE no puede ejecutarse directamente sobre tablas con índice vectorial y los despliegues con DacPac o BACPAC requieren cuidado porque el índice necesita datos no nulos existentes al crearse.
Esto cambia bastante el diseño de procesos ETL. Si regeneramos embeddings en bloque, quizá convenga cargar en una tabla staging, validar dimensiones, controlar nulos, medir duplicados y después hacer intercambio lógico. Si trabajamos en Azure SQL o Fabric con índices recientes, no tenemos que congelar la tabla para cada operación DML normal, pero sí debemos diseñar cargas masivas con cabeza.
También hay que monitorizar. La documentación menciona sys.dm_db_vector_indexes para observar salud del índice y tareas de mantenimiento. En sistemas donde el embedding cambia con frecuencia, esa DMV deja de ser curiosidad y pasa a ser parte del cuadro de mando operativo.
La conclusión práctica es sencilla, no repitas limitaciones antiguas sin mirar versión, pero tampoco vendas los índices vectoriales como índices normales. Ambas posturas son malas. Una por anticuada; la otra por ingenua.
Calidad de datos: embeddings duplicados y basura semántica
La búsqueda vectorial amplifica la calidad del contenido. Si generas embeddings sobre textos pobres, duplicados, genéricos o mal normalizados, el índice devolverá resultados pobres, duplicados, genéricos o mal normalizados. No hay misterio. El embedding no convierte documentación basura en conocimiento. Solo la representa numéricamente con mucha dignidad matemática.
Microsoft recomienda evitar conjuntos con alta proporción de embeddings duplicados, porque perjudican la calidad de resultados, desplazan vecinos más útiles y consumen recursos sin aportar valor.
Esto se ve mucho en bases de conocimiento donde múltiples artículos empiezan con la misma plantilla corporativa. “Estimado usuario, este documento describe el procedimiento para resolver incidencias relacionadas con…” Si generamos embeddings sobre todo el texto sin ponderar ni limpiar, la plantilla común puede contaminar la similitud. Después nos preguntamos por qué todos los documentos parecen iguales. Quizá porque hemos metido el mismo ruido en todos. Sorpresón.
Hay que decidir qué texto se embebe. No siempre interesa usar todo el documento. A veces conviene usar título, resumen, etiquetas, producto, síntomas y causa raíz. En otros casos interesa trocear documentos largos en fragmentos y buscar sobre chunks, no sobre documentos completos. Si un artículo de diez páginas contiene una sección relevante en la página ocho, el embedding global puede diluirla.
También hay que versionar el modelo de embeddings. Si hoy generamos vectores con un modelo y mañana con otro, no debemos mezclar ambos alegremente en la misma columna sin saber qué estamos haciendo. Las distancias entre vectores generados por modelos distintos pueden dejar de tener sentido. Como mínimo, guardaría ModeloEmbedding, FechaEmbedding, HashContenido y estado de generación.
Un diseño más serio podría separar documento y fragmentos:
CREATE TABLE dbo.Documentos
(
DocumentoID BIGINT NOT NULL,
ProductoID INT NOT NULL,
Titulo NVARCHAR(250) NOT NULL,
EstadoPublicacion TINYINT NOT NULL,
FechaActualizacion DATETIME2(3) NOT NULL,
CONSTRAINT PK_Documentos
PRIMARY KEY CLUSTERED (DocumentoID)
);
GO
CREATE TABLE dbo.DocumentoFragmentos
(
FragmentoID BIGINT NOT NULL,
DocumentoID BIGINT NOT NULL,
NumeroFragmento INT NOT NULL,
TextoFragmento NVARCHAR(MAX) NOT NULL,
EmbeddingFragmento VECTOR(1536) NOT NULL,
ModeloEmbedding SYSNAME NOT NULL,
HashContenido VARBINARY(32) NOT NULL,
FechaEmbedding DATETIME2(3) NOT NULL,
CONSTRAINT PK_DocumentoFragmentos
PRIMARY KEY CLUSTERED (FragmentoID),
CONSTRAINT FK_DocumentoFragmentos_Documentos
FOREIGN KEY (DocumentoID)
REFERENCES dbo.Documentos (DocumentoID)
);
GOEste modelo permite buscar fragmentos, no solo documentos. Después podemos agregar resultados por DocumentoID, aplicar RRF sobre fragmentos y mostrar el documento con el fragmento más relevante. Es más trabajo, claro. También es más útil. La alternativa es devolver documentos enormes y confiar en que el usuario encuentre el párrafo bueno. Eso no es buscador; es externalizar el problema.
Reordenación por documento cuando trabajamos con fragmentos
Cuando buscamos sobre fragmentos, aparece un problema adicional. Un documento largo puede tener muchos fragmentos y, por tanto, muchas oportunidades de aparecer. Si no controlamos esto, los documentos extensos dominan el ranking simplemente porque tienen más boletos. Es el mismo vicio de siempre, confundir cantidad con relevancia.
Una estrategia razonable consiste en fusionar primero a nivel de fragmento y después colapsar por documento, quedándonos con la mejor puntuación o aplicando una agregación controlada. Por ejemplo:
WITH FusionFragmentos AS
(
SELECT
COALESCE(S.FragmentoID, L.FragmentoID) AS FragmentoID,
COALESCE(1.0 / (@rrf_k + S.RangoSemantico), 0.0) +
COALESCE(1.0 / (@rrf_k + L.RangoLexico), 0.0) AS PuntuacionRRF
FROM RamaSemanticaFragmentos AS S
FULL OUTER JOIN RamaLexicaFragmentos AS L
ON L.FragmentoID = S.FragmentoID
),
FragmentosConDocumento AS
(
SELECT
F.FragmentoID,
DF.DocumentoID,
F.PuntuacionRRF,
ROW_NUMBER() OVER
(
PARTITION BY DF.DocumentoID
ORDER BY F.PuntuacionRRF DESC, DF.NumeroFragmento ASC
) AS OrdenFragmentoDocumento
FROM FusionFragmentos AS F
INNER JOIN dbo.DocumentoFragmentos AS DF
ON DF.FragmentoID = F.FragmentoID
),
RankingDocumentos AS
(
SELECT
DocumentoID,
MAX(PuntuacionRRF) AS MejorPuntuacionRRF,
COUNT(*) AS FragmentosCoincidentes
FROM FragmentosConDocumento
GROUP BY DocumentoID
),
SELECT TOP (20)
D.DocumentoID,
D.Titulo,
R.MejorPuntuacionRRF,
R.FragmentosCoincidentes,
FC.FragmentoID
FROM RankingDocumentos AS R
INNER JOIN dbo.Documentos AS D
ON D.DocumentoID = R.DocumentoID
INNER JOIN FragmentosConDocumento AS FC
ON FC.DocumentoID = R.DocumentoID
AND FC.OrdenFragmentoDocumento = 1
ORDER BY
R.MejorPuntuacionRRF DESC,
R.FragmentosCoincidentes DESC,
D.DocumentoID ASC;Aquí MAX(PuntuacionRRF) evita que un documento se dispare solo por tener muchos fragmentos moderadamente relevantes. El contador de fragmentos coincidentes puede servir como desempate suave, pero no debería dominar la ordenación. Si queremos algo más sofisticado, podemos usar una combinación entre mejor fragmento, número de fragmentos relevantes y diversidad de secciones.
En sistemas RAG, este patrón es especialmente útil. El buscador no solo decide qué documento mostrar; decide qué fragmento alimentar al modelo generativo. Si metemos fragmentos malos en el contexto, el modelo responderá con seguridad y poca vergüenza. La seguridad sin fundamento ya la conocemos de algunas reuniones de arquitectura, pero no hace falta automatizarla.
También podemos añadir filtros de seguridad y visibilidad antes de la búsqueda. Si un usuario no tiene permiso sobre un documento, ese documento no debe aparecer ni por semántica ni por full-text. Esto parece obvio hasta que alguien implementa el filtro después de generar el contexto para el modelo.
Seguridad, permisos y fuga semántica
La búsqueda híbrida no solo afecta al rendimiento. También afecta a la seguridad. Un embedding puede codificar información sensible del texto original. No es una copia literal, pero tampoco deberíamos tratarlo como un dato inocente. Si generamos embeddings de documentos confidenciales y permitimos búsquedas semánticas sin aplicar permisos correctamente, podemos filtrar conocimiento aunque no devolvamos el texto completo.
La seguridad debe aplicarse antes de formar candidatos o durante el proceso de búsqueda, no al final de manera cosmética. En VECTOR_SEARCH, con índices recientes y filtrado iterativo, los predicados pueden aplicarse durante la búsqueda vectorial. Eso ayuda, pero no sustituye un diseño de seguridad correcto.
En SQL Server podemos resolver parte del problema con predicados relacionales, Row-Level Security o filtros explícitos por tenant, organización, rol o ámbito documental. Lo importante es que la rama léxica y la rama semántica usen exactamente la misma lógica de visibilidad. Si full-text filtra por permisos y vector no, la fusión RRF puede devolver identificadores que la rama textual jamás habría permitido. Y entonces empieza el baile.
También hay que controlar quién puede generar embeddings. Si usamos AI_GENERATE_EMBEDDINGS, debemos revisar modelo, permisos, configuración del servicio y trazabilidad. Si los generamos fuera y los cargamos en SQL Server, debemos validar dimensiones, formato, modelo, nulos y correspondencia con el texto original. Un embedding desalineado con su documento es una mentira muy rápida de consultar.
En entornos multi-tenant, yo evitaría búsquedas vectoriales globales salvo que el aislamiento esté muy claro. Filtrar por tenant no es opcional. Y si el volumen por tenant permite búsqueda exacta con VECTOR_DISTANCE, quizá esa sea la opción más controlable. No todo problema necesita ANN global. A veces la arquitectura sencilla gana porque tiene menos formas de fallar.
La seguridad no debe aparecer como epígrafe al final del proyecto. Si el buscador ya está construido y alguien pregunta “¿cómo filtramos por permisos?”, lo más probable es que la respuesta correcta sea “reescribiendo más de lo que te gustaría”.
Observabilidad: medir relevancia y medir coste
Una búsqueda híbrida tiene dos planos de observabilidad. El primero es técnico: duración, lecturas, CPU, memoria, spills, número de candidatos por rama, uso de índice vectorial, uso de índice full-text, plan elegido, cardinalidades estimadas y reales. El segundo es funcional: consultas reales, documentos mostrados, documentos abiertos, posición del clic, reformulaciones y satisfacción del usuario.
Si solo medimos rendimiento, podemos construir un buscador rapidísimo que devuelve basura. Si solo medimos relevancia, podemos construir un buscador magnífico que tumba producción cada vez que se usa. Ninguna de las dos cosas debería darnos orgullo profesional.
A nivel técnico, conviene registrar para cada búsqueda el texto normalizado, tamaño de candidatos léxico, tamaño de candidatos semántico, top_final, valor de k, pesos aplicados, duración total y duración por rama si separamos ejecución. También podemos guardar si la consulta se trató como “literal crítica” o “semántica dominante”. Esta trazabilidad permite ajustar sin adivinar.
A nivel funcional, el dato más valioso suele ser qué resultado acaba usando el usuario. En soporte, podemos vincular búsqueda con ticket resuelto o artículo seleccionado. Si es documentación interna, podemos medir apertura y permanencia. En buscadores de catálogo, conversión o selección. La relevancia real no siempre coincide con nuestra intuición, especialmente cuando los usuarios escriben cosas que harían llorar a un parser.
También hay que comparar full-text puro, vector puro e híbrido. No para hacer una gráfica bonita, sino para demostrar que la complejidad añadida aporta valor. Si la híbrida no mejora precisión, recall o tiempo de resolución, quizá estamos decorando arquitectura. Y la decoración en producción suele ser cara.
Un enfoque serio consiste en crear un conjunto de consultas de evaluación con resultados esperados. No tiene que ser perfecto. Basta con consultas representativas, incluyendo códigos exactos, frases ambiguas, sinónimos, errores ortográficos, consultas largas y consultas absurdamente cortas. Sobre ese conjunto podemos probar distintos pesos, tamaños de ventana y valores de k.
Sin evaluación, la búsqueda híbrida se convierte en “a mí me parece que va mejor”. Esa frase ha causado más daño que algunos NOLOCK.
Casos donde no usaría búsqueda híbrida
No todo buscador necesita híbrida. Si el usuario busca exclusivamente códigos, referencias exactas, identificadores legales o claves de producto, full-text o incluso índices relacionales bien diseñados pueden bastar. Meter embeddings ahí puede añadir ruido. Una búsqueda de Factura 2024-000834 no necesita poesía semántica.
Tampoco usaría híbrida como primera respuesta a un problema de contenido mal estructurado. Si los documentos no tienen títulos decentes, categorías, producto, idioma, fecha, permisos o estado, la búsqueda híbrida no arreglará el desastre. Solo lo hará más caro. Primero se ordena el contenido; después se mejora la recuperación.
En tablas pequeñas, evitaría crear índices vectoriales salvo que exista una razón clara. Microsoft indica que VECTOR_SEARCH puede funcionar sin índice mediante escaneo brute-force, aunque el rendimiento se degrada con datasets grandes. Para desarrollo, pruebas y conjuntos pequeños, esto puede ser suficiente.
También sería prudente con cargas masivas frecuentes. Si regeneramos embeddings continuamente, cambiamos modelos a menudo o reemplazamos gran parte del dataset, el coste de mantenimiento y reconstrucción puede pesar más que la ventaja de ANN. En esos casos hay que diseñar ventanas de carga, staging, versiones de índice y validaciones. No conviene descubrirlo durante una migración nocturna con tres personas mirando una barra de progreso.
Por último, no usaría híbrida sin una estrategia de seguridad clara. La búsqueda semántica puede recuperar contenido inesperado porque no depende de palabras exactas. Eso es precisamente lo que la hace potente. También es lo que la hace peligrosa si los permisos se aplican tarde o mal.
El mejor buscador no es el que usa más tecnologías. Es el que devuelve lo correcto, rápido, dentro de permisos y con un coste operativo razonable. Parece una obviedad, pero hay arquitecturas enteras construidas para demostrar lo contrario.
Buenas prácticas para llevarlo a producción
La primera buena práctica es separar claramente recuperación y reordenación. La rama full-text recupera candidatos léxicos. La rama vectorial recupera candidatos semánticos. RRF fusiona posiciones. Si mezclamos estas fases sin orden, acabaremos con consultas imposibles de depurar.
La segunda es limitar candidatos por rama. Ni full-text ni vector deberían devolver volúmenes masivos si el resultado final tendrá 20 filas. top_n_by_rank en CONTAINSTABLE y TOP (N) WITH APPROXIMATE en VECTOR_SEARCH son herramientas básicas para controlar el tamaño del problema.
La tercera es conservar filtros relacionales fuertes. Cliente, tenant, producto, estado, idioma, fecha y permisos deben formar parte del diseño. No todo debe resolverse por similitud. A veces una igualdad bien indexada vale más que un grafo vectorial entero. No queda tan bien en una presentación, pero ejecuta mejor.
La cuarta es versionar embeddings. Guarda modelo, fecha, hash del texto y estado de generación. Si cambias el texto, regenera el vector. Cuando cambies el modelo, no mezcles vectores sin control. Si falla la generación, no insertes basura silenciosa. La base de datos recordará tu negligencia con una precisión admirable.
La quinta es medir calidad, no solo latencia. Registra consultas reales y resultados usados. Ajusta pesos y ventanas con datos. RRF funciona muy bien como punto de partida, pero cada dominio tiene sus rarezas. En soporte técnico, los literales pesan mucho. Si es búsqueda documental, la semántica puede dominar. En comercio, atributos estructurados y disponibilidad pueden importar más que ambas.
La sexta es revisar versión y comportamiento de los índices vectoriales. Los índices antiguos tienen limitaciones distintas a los recientes. La sintaxis con TOP_N queda obsoleta para índices nuevos, mientras que SELECT TOP (N) WITH APPROXIMATE es el patrón actual documentado para la búsqueda aproximada con índices recientes.
La séptima es preparar despliegues y mantenimiento. Si usas DacPac, BACPAC, replicación, particionado o cargas masivas, revisa restricciones antes de comprometer la arquitectura. Los índices vectoriales no son invisibles para la operación diaria. El DBA va a convivir con ellos, y conviene que no sea en régimen de sorpresa permanente.
Todo esto suena menos emocionante que “hemos metido IA en el buscador”. También es bastante más probable que funcione.
Conclusión
La búsqueda híbrida no sustituye al full-text ni convierte la búsqueda vectorial en una solución universal. Lo interesante aparece precisamente al combinar ambas señales con criterio, full-text aporta precisión léxica, los vectores aportan contexto semántico y RRF permite fusionar resultados sin mezclar puntuaciones incompatibles.
El diseño correcto no consiste en lanzar dos consultas y rezar. Hay que limitar candidatos, aplicar filtros relacionales, elegir entre búsqueda exacta y aproximada, revisar versiones de índice, controlar permisos, medir relevancia y entender el coste operativo. La parte bonita de la demo dura diez minutos. La parte seria vive dia a dia en producción.
SQL Server está incorporando capacidades muy potentes para búsqueda semántica e híbrida, pero potencia no significa simplicidad. Un índice vectorial mal usado, una rama full-text sin límite o una fusión de puntuaciones mal planteada pueden convertir una gran idea en otra incidencia con prioridad alta.
La búsqueda híbrida merece sitio en arquitecturas modernas, especialmente en bases de conocimiento, soporte, documentación interna y sistemas RAG. Pero exige DBAs que entiendan el motor, no operadores que copien sintaxis de una demo. Como casi siempre, la diferencia entre una solución elegante y una chapuza cara está en los detalles. Y los detalles, por suerte o por desgracia, siguen sin indexarse solos.