Con SQL Database en Fabric Microsoft hizo algo realmente inteligente, coger un motor que conocemos bien, Azure SQL Database, y colocarlo dentro del perímetro operativo de Fabric para vender una historia unificada de datos, analítica y desarrollo. La pregunta útil no es si “es SQL”, porque sí lo es. La pregunta útil es otra: cuánto de Azure SQL conserva, cuánto sacrifica por vivir en Fabric y en qué escenarios compensa ese intercambio. El servicio está en disponibilidad general desde noviembre de 2025 y Microsoft lo presenta como una base de datos SQL serverless y “SaaS-native” dentro de Fabric.
Antes de entrar en límites y promesas, conviene despejar el malentendido principal.
¿Qué significa realmente que sea una Azure SQL Database en Fabric?
Cuando Microsoft dice que SQL Database en Fabric está “basada en Azure SQL Database”, no está jugando con las palabras. Usa el mismo SQL Database Engine que Azure SQL Database, expone TDS, se puede atacar con SSMS, VS Code, sqlcmd o bcp, y mantiene una experiencia T-SQL muy reconocible para cualquiera que lleve años peleándose con SQL Server y su descendencia cloud. Hasta aquí, bien, no es un juguete con icono nuevo y marketing con esteroides.
Ahora viene la parte que importa. No es “Azure SQL Database metida dentro de un workspace” y listo. El contrato de servicio cambia. El licenciamiento cambia. El modelo de consumo cambia. La red cambia. La seguridad cambia. Y varias capacidades de plataforma que en Azure SQL ya damos por sentadas aquí no están, o han llegado más tarde, o llegan con otra forma. Dicho de otro modo, el motor sí, el producto no del todo. Y en arquitectura de datos, como ya sabemos, el diablo se esconde en la letra pequeña
Aquí está la clave técnica que explica casi toda la propuesta.
Arquitectura: no es un único almacén, son dos representaciones coordinadas
SQL Database en Fabric guarda sus datos operacionales en ficheros .mdf, igual que Azure SQL Database, pero además replica automáticamente los datos a OneLake en formato Delta Parquet. Sobre esa copia se crea un SQL analytics endpoint de solo lectura, accesible por TDS, para lanzar consultas analíticas sin castigar el workload transaccional. El espejo arranca al crear la base de datos, no requiere configuración manual y, en su comportamiento base, siempre ha estado activado. Técnicamente, por tanto, no hablamos de “el mismo dato en el mismo motor para todo”, sino de una base operacional más una representación analítica mantenida casi en tiempo real dentro de la misma plataforma.
Eso hace que el nuevo mensaje de “translítico” que nos quieren vender tenga su parte de verdad pero también una gran parte de jerga comercial. Sí, los datos operativos quedan disponibles casi al momento para analítica, Spark, notebooks, Power BI y otras piezas de Fabric. Pero no porque el OLTP y la analítica compartan mágicamente el mismo camino de ejecución, sino porque Fabric automatiza el reflejo a OneLake y pone un endpoint analítico encima. El resultado práctico puede ser muy bueno. La simplificación conceptual que a veces se cuenta, no tanto.
Una vez entendido eso, ya podemos responder la pregunta incómoda de verdad.
Anatomía interna: plano de control, plano de datos y replicación
Si queremos entender de verdad qué es SQL Database en Fabric, no basta con decir que “es Azure SQL dentro de Fabric”. Hay que separar claramente el plano de control del plano de datos. Y aquí está una de las claves del producto.
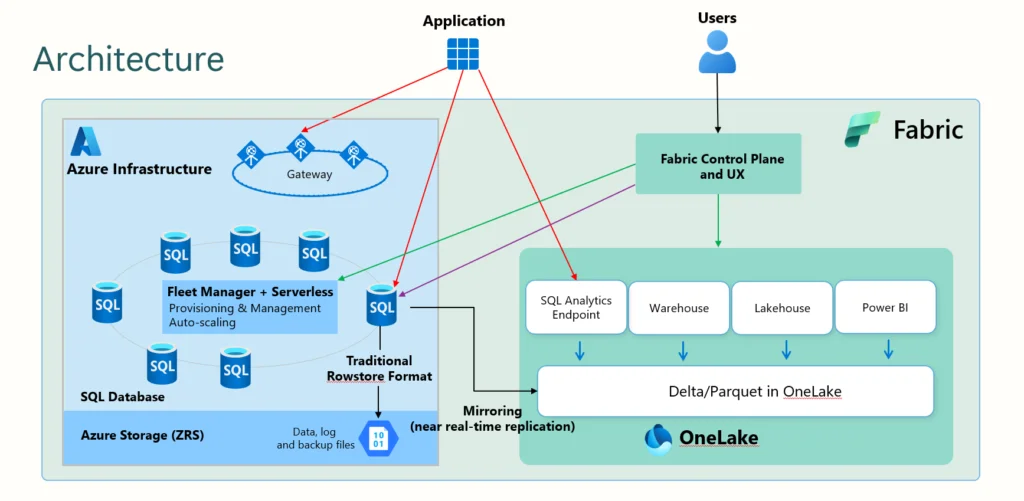
La experiencia de creación, gobierno, acceso y operación vive en Fabric, a través de su control plane y su UX. Pero la base de datos operacional sigue ejecutándose sobre infraestructura de Azure SQL, con almacenamiento propio de datos, log y copias de seguridad, y con un formato de almacenamiento transaccional clásico orientado a rowstore. Es decir, el envoltorio operativo es Fabric, pero el corazón que procesa las transacciones sigue siendo Azure SQL Database.
Ese matiz importa porque desmonta una simplificación bastante extendida. No estamos escribiendo directamente sobre tablas Delta en OneLake ni usando el lake como backend transaccional milagroso. La aplicación entra por el endpoint SQL, habla TDS con el motor relacional y trabaja sobre una base operacional de verdad. Después, y de forma desacoplada, Fabric replica ese contenido hacia OneLake casi en tiempo real para exponerlo en formato Delta/Parquet al resto de motores analíticos de la plataforma. Esa réplica alimenta el SQL analytics endpoint y deja los datos listos para que Warehouse, Lakehouse, notebooks o Power BI los consuman sin castigar el workload OLTP.
Visto así, la arquitectura tiene dos caminos distintos. El primero es el camino operacional: aplicación, gateway, motor SQL, almacenamiento transaccional y gestión automática del servicio. El segundo es el camino analítico: mirroring hacia OneLake, persistencia en Delta/Parquet y consumo desde los motores analíticos de Fabric. Microsoft vende esto como translítico, y la palabra no es del todo humo, pero tampoco conviene leerla con demasiada poesía. No es que una misma estructura sirva simultáneamente para OLTP y analítica pesada sin coste ni compromiso. Lo que ocurre es algo bastante más sensato: el dato nace en una base transaccional y Fabric lo proyecta automáticamente a un formato analítico común dentro de OneLake. Eso está muy bien diseñado. Y, por una vez, el truco real es más interesante que el eslogan.
Aquí además hay un detalle importante para el bolsillo y para la operación. La replicación desde SQL Database en Fabric hacia OneLake no consume coste de cómputo en CUs, y Microsoft indica que ese mirroring tiene latencia cercana al tiempo real. Es decir, el servicio no solo evita que montemos una canalización adicional para mover datos al plano analítico, sino que además no penaliza la capacidad por el mero hecho de reflejarlos. El consumo empieza cuando explotamos esos datos con otros motores, no cuando Fabric los materializa en OneLake. Que esto sea así cambia bastante la conversación, porque convierte la réplica en una capacidad estructural del producto y no en otro peaje operativo disfrazado de integración “moderna”.
Desde el punto de vista de arquitectura de datos, la consecuencia práctica es muy clara. SQL Database en Fabric no es un sustituto de Warehouse ni de Lakehouse, sino una pieza intermedia que conecta el mundo operacional con el analítico sin obligarnos a montar fontanería extra desde el minuto uno. Su valor no está en reinventar el motor SQL, sino en empaquetar el plano transaccional y el plano analítico dentro del mismo perímetro de gobierno. Y ahí es donde realmente tiene sentido: menos integración manual, menos duplicidad de circuitos y más cercanía entre la base que da servicio y la plataforma que analiza. Siempre, claro, que tengamos presente que son dos representaciones coordinadas del dato y no una fusión mística entre OLTP y analítica que resuelva por arte de magia todos los pecados de diseño acumulados durante años.
¿Hasta qué punto es SQL de verdad?
La respuesta es bastante. Soporta el motor relacional que esperamos para OLTP, tablas transaccionales, ACID, claves foráneas, stored procedures, vistas, funciones, aislamiento desde serializable hasta read committed snapshot, tuning automático e indexación automática de non-clustered según datos reales de ejecución. Para cargas operacionales normales, APIs, aplicaciones internas, ODS y bases de datos de servicio, el sabor es inequívocamente SQL. No hay que reaprender a hablar con la base de datos porque alguien haya decidido que todo debía acabar en “Lake”.
Pero tampoco conviene venderlo como paridad plena con Azure SQL Database. No hay SQL Authentication, solo Microsoft Entra ID. No hay logins de servidor ni roles a nivel servidor. SQL Server Agent tampoco está, y Microsoft te empuja a pipelines o Airflow. Tampoco están failover groups, geo-restore, elastic jobs, elastic pools, DMS, DMA, VNet endpoints o resource pools. Además, hay restricciones de superficie, no se pueden crear tablas in-memory, ledger, ledger history ni Always Encrypted, y ciertas capacidades siguen en preview, como OPENROWSET BULK, full-text indexing o algunas opciones de ALTER DATABASE SET.
Hay otra diferencia sutil pero importante. Las consultas cross-database con nombres de tres partes existen, pero el camino soportado pasa por el SQL analytics endpoint, no por el plano transaccional clásico. Es decir, el “todo habla con todo” existe, sí, pero vive del lado analítico. Eso tiene lógica técnica (y en Azure SQL Database es igual), aunque desmonta un poco la fantasía de que toda la plataforma es un gran SQL Server cósmico con camiseta de Fabric. No lo es, por suerte y por desgracia.
El siguiente punto es donde muchos proyectos se ganan o se arruinan el presupuesto.
Escala y consumo: hasta dónde llega y cómo te cobra el chiste
Llegamos a la parte escabrosa. Microsoft coloca SQL Database en Fabric en el rango de datos estructurados de volumen moderado, desde varios GB hasta unos pocos TB. La documentación de arquitectura para Fabric lo sitúa claramente por debajo del terreno natural de Warehouse o Lakehouse cuando hablamos de big data, petabytes, tablas multi-TB y analítica masiva. Dicho sin diplomacia, esto no es el nuevo sitio donde aparcar todo “porque total también es SQL”. Para eso ya tenemos suficientes cementerios de arquitectura.
En límites documentados, la base puede escalar hasta 32 vCores y 4 TB, con tempdb de hasta 1.024 GB y throughput de escritura de log de hasta 50 MB/s. Además, Microsoft ha introducido un control máximo de vCores, aún en preview, que permite acotar el techo de cómputo. La propia documentación muestra el rango entre 4 y 32 vCores y deja claro que el servicio hace autoscaling dentro de ese tope. Es decir, escala sí, pero dentro de un corral bastante definido. Muy útil para OLTP moderno y ODS razonables. Menos impresionante cuando uno viene de leer promesas grandilocuentes sobre plataforma unificada universal definitiva, edición coleccionista.
El modelo de consumo es lo que cambia la conversación. Aquí no compras una base de datos con su SKU aislada, sino que consumes capacidad Fabric compartida. Un CU de Fabric equivale aproximadamente a 0,383 vCores de base de datos, y una F64 equivale a unos 24,512 vCores de SQL Database. La base autoscala, mantiene un mínimo de 2 GB de memoria mientras está online, y tras 15 minutos de inactividad para y libera CPU y memoria, eso sí, se sigue facturando el almacenamiento. Eso suena bien hasta que recuerdas que esa misma capacidad también la usan otros workloads de Fabric. Ahí empieza la parte divertida, en el sentido en que también es divertida una alerta a las tres de la mañana.
Particularidades de consumo de Fabric.
Los consumos en Fabric se dividen en dos tipos, los interactivos y los de background.
Y esto es un matiz decisivo, el consumo de SQL Database es una operación interactiva. En el Metrics app, “SQL Usage” recoge el coste de todas las sentencias T-SQL generadas por usuarios y por sistema, y cuando la capacidad entra en throttling las consultas pueden llegar a registrarse como rechazadas. Comparado con Warehouse, donde el consumo de consulta figura como background, aquí estamos mucho más cerca del mundo de la aplicación viva que del batch analítico tranquilo.
Dicho en lenguaje DBA SQL Server, un consumo interactivo es el que nace de una petición que alguien espera resolver ya: una query lanzada desde la aplicación, desde SSMS, desde un informe o desde cualquier proceso que está dando servicio en ese momento. El consumo en segundo plano, en cambio, es el trabajo diferido que la plataforma puede ejecutar con otra prioridad, como una carga, una transformación o una consulta analítica que no está sosteniendo la interacción directa de un usuario. SQL Database en Fabric cae en el primer grupo porque está pensado para cargas operacionales y transaccionales, no para esperar disciplinadamente su turno.
La implicación es clara, hay que competir no solo con lo que se está ejecutando ahora mismo sino con la parte proporcional (Smoothing) de los trabajos de backgrpund que se han ejecutado en las últimas 24 horas. Y claro, si la capacidad va justa, el mayor impacto lo sufre el workload vivo, el de SQL que va a ver más latencia, menos estabilidad y posibles rechazos.
Con esto claro, ya se entiende mejor la parte económica y de seguridad.
Licenciamiento, acceso y la letra pequeña
Para usar SQL Database en Fabric necesitas una capacidad válida de Fabric, Power BI Premium o Trial, y la facturación sigue el modelo de capacidad de Fabric, no el de Azure SQL Database. Los cargos aparecen en Azure Cost Management bajo la suscripción asociada a la capacidad. El coste combina cómputo y almacenamiento, y el backup storage solo empieza a cobrarse cuando supera el 100 % del tamaño aprovisionado de la base. Es un modelo cómodo para centralizar gasto, pero borra la separación mental entre “mi base de datos” y “la capacidad del resto de Fabric”, que, para la analítica contable, no siempre es una buena noticia.
En cuanto a accesos la historia es sencilla pero dura a la vez, solo podemos usar Entra ID. No hay SQL logins. Tampoco hay sa. Ni hay ese usuario legacy que vive de cadenas de conexión con usuario y contraseña incrustados desde 2017 “porque nunca dio problemas”. Además, el acceso mezcla dos planos de autorización que hay que tener siempre en mente. Por un lado primero tenemos que tener acceso a Fabric y por otro los permisos nativos SQL dentro de la base. Microsoft lo describe como una superposición “most permissive”, así que conviene dar acceso de conexión con Fabric y afinar de verdad la seguridad en el plano SQL. Seguridad moderna, sí pero también fricción con aplicaciones legacy.
Aquí además hay una novedad relevante. Tras la FabCon de marzo de 2026, Microsoft ya recoge como GA la auditoría para SQL Database en Fabric y las customer-managed keys con TDE automático a nivel de workspace. También anuncia recuperación de bases borradas y retención de backup configurable entre 1 y 35 días.
Y aquí conviene separar copia de seguridad operativa de disaster recovery real, porque no son lo mismo aunque a veces se vendan como si lo fueran. SQL Database en Fabric sí mantiene copias automáticas y permite point-in-time restore, con retención configurable entre 1 y 35 días, pero la restauración crea una base nueva dentro de Fabric y la documentación sigue marcando como no soportados el cross-workspace restore y el cross-region restore. Traducido al mundo real: estas copias nos cubren muy bien frente a borrados accidentales, despliegues fallidos o una metedura de pata humana, pero no son una copia portable que podamos sacar y restaurar donde nos convenga. Si queremos una estrategia de DR seria fuera de ese perímetro, hay que exportar periódicamente a BACPAC con SqlPackage y guardarlo en otra región o en almacenamiento externo, que es precisamente la vía que Microsoft recomienda para un fallo regional.
Con todo eso encima de la mesa, toca la pregunta estratégica.
¿Dónde sí tiene sentido el relato translítico y dónde todavía no?
Sí la pregunta es si todo esto de tener la parte operacional y la analítica juntas, si tiene sentido cuando quieres un núcleo operacional gobernado dentro de Fabric, con latencia baja, integridad relacional, tooling SQL clásico y una salida analítica casi inmediata sin montar otro circuito de ingestión. Ahí encajan muy bien los casos de uso que Microsoft empuja de forma oficial (Operational Data Store, reverse ETL y aplicaciones translíticas). También encaja para equipos que ya viven en Fabric y quieren reducir el impuesto de integración entre la base operativa y el resto del ecosistema.
Sin embargo, no tiene tanto sentido cuando tu analítica real pide otra cosa, grandes escaneos, históricos pesados, modelos dimensionales complejos, muchísima concurrencia analítica, ingestas masivas o escalado hacia decenas de TB y PB. Ahí Fabric ya tiene mejores piezas, y la propia guía de Microsoft coloca Warehouse, Lakehouse o Eventhouse por delante según el patrón. Tampoco lo veo claro si dependes de capacidades maduras de Azure SQL Database que aquí aún faltan, o si necesitas un aislamiento de red y de cómputo mucho más predecible. Una plataforma unificada ahorra fricción, sí, pero también puede concentrar demasiadas dependencias en el mismo sitio. Y eso solo parece bonito hasta el primer incidente transversal.
Queda la parte que de verdad ayuda a decidir.
Pros, contras y lo que le pediría para ser realmente usable
La principal virtud de SQL Database en Fabric es que resuelve muy bien el espacio intermedio que durante años ha quedado incómodo, una base operacional moderna, bastante SQL de verdad, con integración directa en la plataforma analítica y sin bricolaje constante entre servicios. Para ODS, serving layers, APIs, aplicaciones internas y escenarios donde OLTP y consumo analítico conviven cerca, la propuesta tiene mucho sentido. Y el hecho de que el espejo a OneLake salga de serie elimina una cantidad obscena de fontanería que hasta ahora hacíamos “a mano” y luego fingíamos que era arquitectura elegante.
Sus peajes están claros. La paridad con Azure SQL Database aún no es suficiente para ciertos entornos serios. El aislamiento de capacidad es más difuso. La dependencia de Entra ID para usuarios corta de raíz algunos escenarios heredados. La historia de red sigue siendo menos madura de lo que muchos equipos enterprise pedirían. Y la documentación aún necesita dejar de contradecirse entre tablas, notas de lanzamiento y páginas de detalle, algo normal para un producto tan nuevo por otra parte. Pero claro, en una solución que quiere ganarse a DBAs, eso no es un matiz: es parte del producto.
¿Qué le pediría para que sea más usable?
Hasta aquí la teoría, ahora me voy a mojar y os voy a dar mi opinión. Para mi, para hacer esto más usable pediría menos épica y más nitidez. Quiero una matriz de compatibilidad viva y fiable, una historia de migración de primera división, con DMS o equivalente real. Por pedir, quiero una solución de DR más madura, con geo-restore y failover groups. Y por supuesto, aislamiento y control de red más directos por base o por workspace sin rodeos ceremoniales. Quiero observabilidad y gobierno de capacidad cada vez más finos, porque cuando una base operacional compite por CUs con media plataforma, el problema ya no es solo de base de datos, es de convivencia. Y la convivencia, como sabemos, nunca se arregla con una keynote.
SQL Database en Fabric no viene a sustituir Azure SQL Database ni a jubilar Warehouse. Viene a ocupar un hueco muy concreto, y cuando encaja, encaja francamente bien. Pero conviene comprarla por lo que es, no por lo que el folleto insinúa. Es SQL, sí. Bastante SQL. Pero sobre todo es SQL bajo las reglas de Fabric. Y esa diferencia es exactamente la que decide si esto acaba siendo una gran pieza de plataforma o una bonita confusión con logo nuevo.
Conclusión
SQL Database en Fabric me parece una solución bastante más seria de lo que algunos quieren admitir, pero también bastante menos mágica de lo que Microsoft insinúa. Cuando el problema es OLTP moderado, integración rápida con analítica y menos fontanería entre la base operacional y el resto de la plataforma, encaja muy bien. Cuando necesitamos aislamiento más predecible, una historia de DR madura, más superficie de Azure SQL y menos dependencia del estado general de la capacidad, todavía no. No viene a sustituirlo todo, ni falta que hace. Viene a ocupar un hueco concreto, y ahí puede funcionar francamente bien. El error sería comprar el eslogan en lugar de entender la pieza. Porque aquí la diferencia importante no es que sea SQL. La diferencia importante es bajo qué reglas juega ese SQL.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!




