Lo sé, llevo más de un mes sin publicar artículos en el blog. No ha sido precisamente porque se me haya olvidado escribir. He estado metido hasta el cuello preparando cursos y sacando adelante otros proyectos. Parece que no pero estas cosas consumen las horas con una eficacia admirable y una compasión nula. El canal de YouTube también lleva cerca de dos meses parado por lo mismo. Así que vamos a retomar ambas cosas poco a poco, con algo que además creo que merece la pena.
Hace unos días me dejaron un comentario bastante sensato en un vídeo antíguo donde explicaba cómo funciona TDE en SQL Server. @eadames2 venía a decir que el vídeo era demasiado básico y que faltaban ejemplos de vida real, contexto y, sobre todo, criterio para decidir qué método de cifrado conviene según el caso. Y sí, la observación es buena. En el vídeo enseñé el cómo. Hoy, aquí, toca hablar del cuándo y del para qué.
Sobre cifrado ya había publicado en el blog el artículo “Cifrado de datos en SQL Server”, donde repasaba TLS, TDE, Always Encrypted y DDM, y también otro texto sobre qué pasa con la inicialización instantánea de ficheros al habilitar TDE, que entra en una consecuencia operativa muy concreta. No voy a repetir aquí lo que ya está explicado allí. Lo que quiero hacer en este artículo es completar esa parte que muchas veces se queda fuera: cómo elegir bien según la amenaza real, el tipo de datos y el precio operativo que estamos dispuestos a pagar.
Antes de entrar en tecnologías concretas, conviene poner orden en una idea que suele venir torcida de fábrica.
El error habitual: elegir tecnología antes de definir la amenaza
Cuando alguien dice que quiere “cifrar la base de datos”, casi nunca está describiendo un requisito. Está describiendo una intuición. Y las intuiciones, en seguridad, suelen ser un punto de partida aceptable y un punto de llegada desastroso.
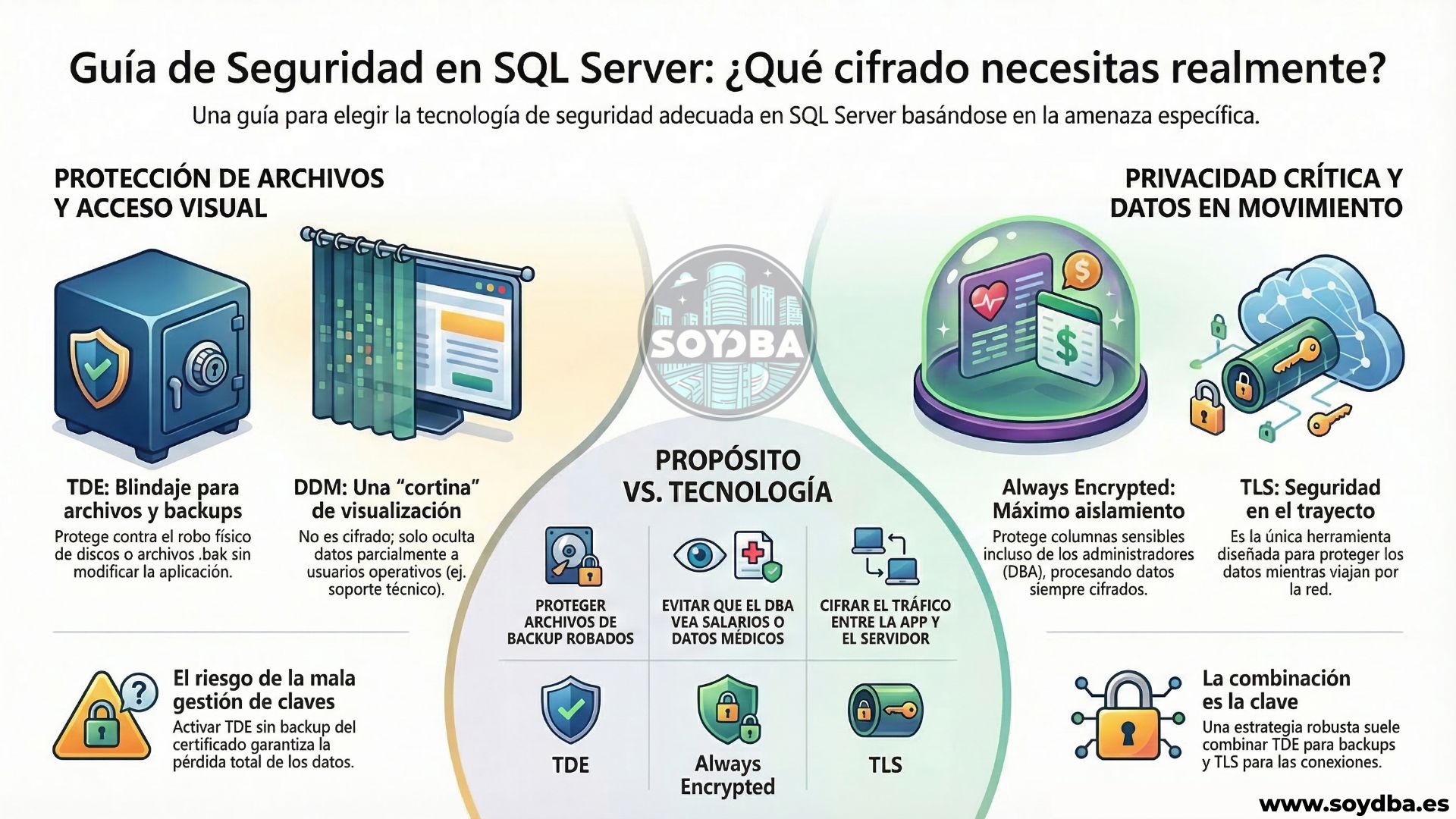
No es lo mismo proteger datos frente al robo de backups que impedir que un DBA vea una información concreta. Tampoco es lo mismo ocultar información sensible a usuarios funcionales que proteger el tráfico entre aplicación y servidor. Meter todo eso en la misma cesta y resolverlo con una sola tecnología suele acabar como acaban estas cosas: con un checkbox marcado, una falsa sensación de seguridad y una reunión desagradable más adelante.
TDE, Always Encrypted, TLS y DDM no compiten entre sí en todos los escenarios. A veces se complementan y a veces uno no sirve absolutamente para nada si el problema real está en otra parte. Por eso la pregunta correcta no es “qué método cifra más”. La pregunta correcta es “de qué quiero protegerme exactamente y quién es el adversario aquí”.
Ese matiz cambia bastante la conversación, así que vamos con casos reales.
Caso real 1: alguien roba un backup o se lleva los ficheros de la base de datos
Aquí es donde TDE encaja muy bien. Si tu preocupación principal es que alguien coja un .bak, un .mdf, un .ndf o un .ldf y se lo lleve alegremente a otro servidor para restaurarlo sin permiso, TDE es una solución razonable y bastante transparente.
La gran ventaja de TDE es precisamente esa, protege los datos en reposo sin obligarte a rediseñar la aplicación ni a reescribir consultas. El usuario legítimo sigue trabajando igual, y el motor cifra y descifra por debajo. En entornos corporativos donde el riesgo está en el acceso físico a discos, en copias de seguridad mal custodiadas o en procedimientos de restauración fuera de control, TDE tiene muchísimo sentido.
Ahora bien, conviene no pedirle milagros. TDE no evita que alguien con acceso lógico a la base de datos y permisos suficientes consulte los datos. No te protege de un SELECT bien autorizado, ni de un desarrollador con más privilegios de los que debería, ni de ese clásico “es solo para una prueba” que termina con un usuario leyendo más de la cuenta. TDE protege archivos y backups. No arregla un modelo de permisos chapucero, que es otra afición muy extendida.
Además, TDE tiene peaje. Ya conté en el artículo sobre inicialización instantánea de ficheros que al activarlo perdemos ciertas ventajas operativas y podemos notar impacto en crecimientos, restauraciones y tiempos de ciertas operaciones. Y hay otro punto que en las demos parece un detalle y en producción no lo es, el certificado. Si no haces backup del certificado y de su clave privada, el día que necesites restaurar en otro servidor te puedes ahorrar el café, porque no vas a restaurar nada. Si cifras con TDE y no haces copia de seguridad del certificado y de su clave privada, tu backup queda protegido incluso contra ti mismo. Muy seguro todo. Muy poco práctico también.
No todos los escenarios exigen llegar tan lejos. A veces el problema no es que alguien robe un backup, sino que ciertos usuarios ven más de lo que deberían ver en el día a día.
Caso 2: algunos usuarios no deberían ver los datos completos
Aquí entra DDM, y aquí conviene hablar sin maquillaje, porque bastante tiene la tecnología con el suyo propio. Dynamic Data Masking no es cifrado. Sirve para ocultar parcialmente datos cuando los consulta un usuario que no tiene permiso para verlos completos, pero el dato sigue estando almacenado tal cual en la base de datos.
Eso puede ser útil. En entornos de soporte, atención al cliente, explotación o consultas operativas, muchas veces necesitamos que ciertos perfiles trabajen con datos reales sin exponerles el valor completo de una columna sensible. Mostrar parte de un correo, ocultar tramos de un teléfono o limitar la visualización de un identificador puede tener bastante sentido. Reduce la exposición innecesaria y evita errores humanos bastante previsibles.
El problema viene cuando alguien intenta vender DDM como si resolviera necesidades de seguridad de alto nivel. No. DDM no protege un backup robado, no impide que el motor lea el dato y no sustituye ni a TDE ni a Always Encrypted. Lo que hace es modificar la presentación del dato para determinados usuarios. Nada más. Nada menos. Y mientras entendamos eso, puede ser perfectamente válido.
En otras palabras: si tu requisito es “que el personal de soporte no vea el valor completo del documento de identidad”, DDM puede encajar. Si tu requisito es “que nadie pueda extraer el dato real de la base si accede a los ficheros” o “que ni siquiera ciertos administradores puedan verlo”, entonces DDM no te sirve. Ahí ya estarías usando una cortina para parar un incendio, que tiene un punto optimista, pero poca eficacia.
A veces, sin embargo, el nivel de exigencia sube bastante más. Y en ese punto ya no basta con ocultar visualmente una parte del dato.
Caso 3: ni siquiera el DBA debería ver ciertos datos
Cuando el requisito es que ni siquiera un administrador de base de datos pueda consultar ciertos valores en claro, TDE y DDM se quedan cortos por definición. TDE porque el motor necesita descifrar la información para trabajar con ella. DDM porque solo maquilla la salida para algunos usuarios. Si el objetivo es separar de verdad quién puede ver el dato y quién solo puede administrarlo, entonces toca mirar Always Encrypted.
Always Encrypted está pensado para columnas concretas y para escenarios donde los datos son especialmente sensibles. Hablamos de información médica, datos financieros, salarios, identificadores personales o cualquier campo donde el requisito no sea simplemente proteger discos y copias de seguridad, sino impedir que ciertos perfiles con acceso a la infraestructura puedan leer el valor real. Es una diferencia importante.
La gracia de Always Encrypted está precisamente en esa separación. Las claves no se gestionan como en TDE y el modelo de confianza cambia bastante. Eso hace que el nivel de protección sea superior en algunos escenarios, pero también introduce complejidad técnica. No todas las consultas pueden hacerse igual, no todas las operaciones son cómodas y el desarrollo de la aplicación tiene que convivir con esas limitaciones. Vamos, que no es una opción para activar con alegría y descubrir el lunes que media aplicación ya no hace lo que hacía.
¿Merece la pena? Cuando el requisito lo exige, sí. Sin duda. Pero si solo quieres proteger backups o discos, meter Always Encrypted porque suena más serio es un error clásico. Aún hay quien cree que la mejor solución de seguridad es siempre la más compleja.
Hasta ahora hemos hablado de datos en reposo o de visibilidad dentro de la propia base. Pero queda una capa distinta, y conviene separarla para no mezclar churras con certificados.
Caso real 4: el problema está en la red, no en el disco
Si los datos viajan entre cliente y servidor, o entre servicios, y tu preocupación es que alguien intercepte ese tráfico, entonces lo que necesitas mirar es TLS. Ni TDE ni DDM ni Always Encrypted sustituyen el cifrado del canal de comunicación.
Esto es importante porque sigue habiendo entornos donde alguien activa TDE y se queda tan tranquilo, como si eso protegiera automáticamente el tráfico por red. No. Cifrar el archivo de base de datos no convierte mágicamente en segura una conexión mal configurada. Son capas distintas y problemas distintos.
TLS es el mecanismo adecuado para proteger datos en tránsito. Si tienes aplicaciones conectadas por red, servicios hablando entre sí, réplicas, integraciones o accesos remotos, necesitas que el canal vaya cifrado y, si puede ser, bien configurado. Lo contrario es confiar en que nadie mire. Una estrategia audaz, desde luego, aunque no especialmente profesional.
En muchos sistemas reales, de hecho, la respuesta correcta no es elegir una sola opción, sino combinar varias con un poco de sentido común.
Lo normal en producción: combinar tecnologías según el riesgo real
La mayoría de entornos serios no viven de absolutos. Viven de compromisos bien pensados. Y eso significa que muchas veces la solución buena no es “TDE o Always Encrypted”, sino “TDE y además TLS”, o “TLS para todo el tráfico y DDM para ciertos usuarios de soporte”, o incluso “TDE para la base completa y Always Encrypted en columnas concretas especialmente sensibles”.
Un ERP corporativo puede necesitar TDE para proteger backups y discos, TLS para las conexiones y un modelo de permisos competente. Un sistema de recursos humanos probablemente necesite además evaluar Always Encrypted en campos muy concretos. Una herramienta de soporte interno puede apoyarse en DDM para limitar lo que ciertos perfiles ven en pantalla, sin vender eso como la octava maravilla de la seguridad.
La decisión, por tanto, no depende tanto del “tipo de base de datos” en abstracto como del tipo de dato, del modelo de acceso y del riesgo que quieres mitigar. Una base de datos de facturación interna y una de analítica pueden tener tamaños parecidos y una necesidad de protección totalmente distinta. El nombre del sistema importa menos que la exposición del dato y las personas que pueden tocarlo.
Con todo esto encima de la mesa, ya se puede responder de forma más útil a la pregunta del comentario.
Entonces, ¿qué método conviene según el caso?
Si lo que te preocupa es el robo de copias de seguridad o de archivos físicos, empieza por TDE. Es la opción natural, tiene un impacto asumible en muchos entornos y protege precisamente ese escenario. Si además activas TDE, haz bien el trabajo completo: gestiona certificados, documenta el procedimiento de recuperación y prueba restauraciones. Porque un TDE sin backup del certificado es una bomba de relojería con modales.
Si el problema es que determinados datos no deberían estar visibles ni para personal con privilegios altos en la infraestructura, entonces TDE no basta y hay que mirar Always Encrypted. Aquí la complejidad sube, sí, pero también lo hace el nivel de aislamiento real.
Si lo que necesitas es limitar lo que ven ciertos usuarios operativos sin cambiar la aplicación de arriba abajo, DDM puede ser útil, sabiendo perfectamente que no estás cifrando nada. Y si la preocupación es el tráfico entre cliente y servidor, no des más rodeos y configura TLS como corresponde.
Dicho de otra manera: TDE protege datos en reposo a nivel de archivos y backups. Always Encrypted protege columnas frente a accesos que no deberían ver el valor real. DDM limita exposición visual en consultas para ciertos perfiles. TLS protege el canal de comunicación. Confundirlos es bastante común. Elegirlos bien ya no debería serlo tanto.
Conclusión
El comentario de @eadames2 iba bien encaminado: enseñar a activar TDE está bien, pero no basta si no explicamos cuándo tiene sentido usarlo y cuándo no. En seguridad, la tecnología correcta no es la más llamativa ni la más compleja, sino la que responde a la amenaza real sin convertir la operación diaria en una penitencia.
Ya tenemos en el blog el artículo general sobre cifrado en SQL Server y el análisis del impacto de TDE sobre la inicialización instantánea de ficheros. Este texto viene a completar esa parte que faltaba: el criterio. Porque cifrar por cifrar sirve de poco. Lo útil es saber qué proteges, de quién lo proteges y cuánto te va a costar mantenerlo. Lo demás es decorar el problema con terminología bonita y esperar que nadie haga demasiadas preguntas.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!



