Llevamos un par de artículos ya hablando sobre compresión de datos y ya hemos visto cómo esta afecta tanto a las tablas como a los índices tanto en SQL Server como en Azure SQL. Sin embargo, hay un tipo de índice que no se ve afectado por la compresión y son los índices columnares. Lo cierto es que este tipo de índices ya tienen un nivel altísimo de compresión de datos al ser columnares pero, aún podemos comprimirlos más si es lo que queremos. Estoy hablando de una opción no tan conocida y usada que es el COLUMNSTORE_ARCHIVE.
Índices Columnares y su naturaleza comprimida
Como he comentado ya en la introducción, la propia naturaleza columnar de los índices columnstore ya de por si facilita la compresión. En concreto, por defecto y por definición se aplican técnicas de compresión avanzadas. A diferencia de los índices tradicionales basados en filas, los índices Columnstore almacenan los datos en formato columnar, lo que permite aplicar técnicas de compresión más avanzadas.
Cuando creamos un índice Columnstore, SQL Server automáticamente aplica compresión de diccionario, codificación por lotes y compresión de bits, lo que reduce significativamente el tamaño del almacenamiento y mejora la eficiencia en la lectura de datos.
La compresión de diccionario reduce el tamaño del almacenamiento eliminando valores repetitivos dentro de cada segmento de datos. Por su parte, la codificación por lotes (Run-Length Encoding) optimiza la compresión al almacenar secuencias de valores repetidos como una sola entrada. Por último, la compresión de bits (Bit-Packing) reduce el tamaño del almacenamiento al optimizar el número de bits utilizados para representar los valores almacenados.
¿Qué es Columnstore_Archive?
El índice Columnstore_Archive es una extensión del índice Columnstore comprimido estándar, diseñado para proporcionar una comprensión aún mayor aplicando algoritmos de compresión adicionales. Mientras que un índice Columnstore ya aplica técnicas avanzadas de reducción de datos como codificación de diccionario, codificación por lotes y compresión de bits, Columnstore_Archive utiliza una compresión más agresiva basada en el algoritmo Xpress Compression Algorithm (XCA).
Diferencias clave entre Columnstore y Columnstore_Archive
| Característica | Índice Columnstore Normal | Columnstore Archive |
| Compresión aplicada | Codificación de diccionario, run-length, bit-packing | Todo lo anterior + compresión LZ77+Huffman |
| Impacto en almacenamiento | Reducción del 50-70% | Reducción del 70-90% |
| Impacto en CPU | Bajo | Alto (más procesamiento en consultas) |
| Velocidad de lectura | Alta | Reducida por el proceso de descompresión |
| Casos de uso ideales | Datos transaccionales y de consulta frecuente | Datos históricos, auditoría y repositorios de solo lectura |
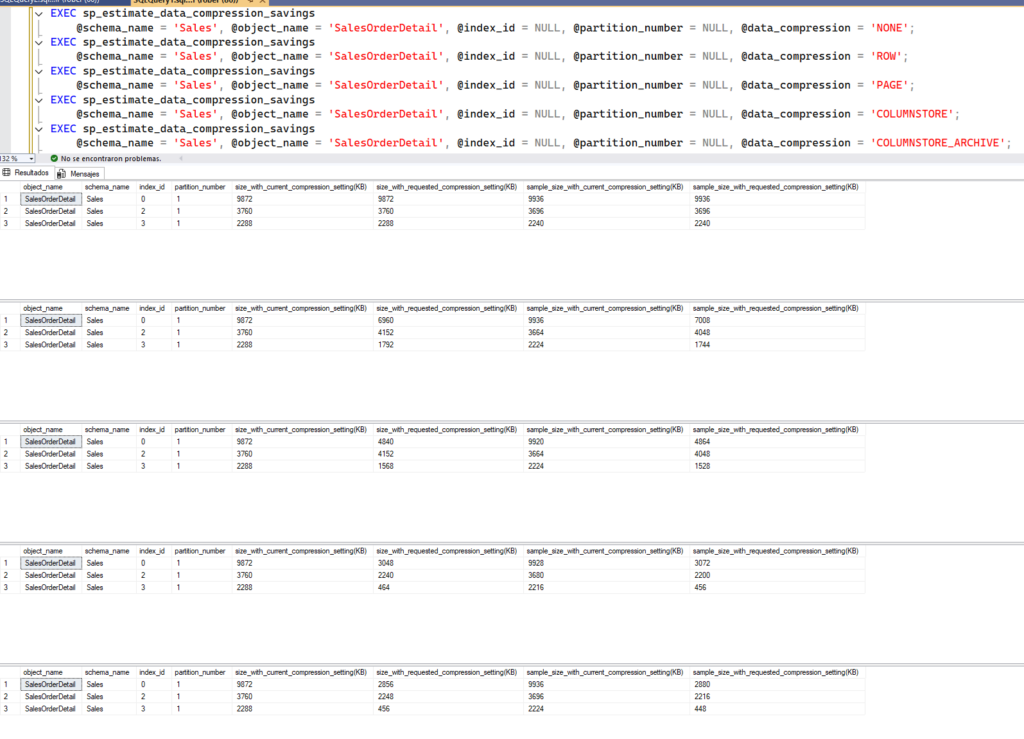
Cómo funciona la compresión en Columnstore_Archive
Como he comentado, el modo Columnstore_Archive añade una capa extra de compresión sobre los segmentos Columnstore existentes. Esto se logra mediante una combinación de técnicas de compresión basadas en LZ77 y Huffman, utilizadas en el algoritmo Xpress Compression Algorithm (XCA).
Fases del proceso de compresión de Columstore_Archive
- Compresión LZ77: Reemplaza secuencias repetidas de bytes con referencias a posiciones anteriores en el flujo de datos. Esto reduce el tamaño al eliminar redundancias en los segmentos Columnstore.
- Codificación Huffman: Utiliza un esquema de codificación basado en la frecuencia de los datos para minimizar aún más el tamaño. Los valores más comunes se almacenan con menos bits, mejorando la eficiencia de almacenamiento.
Cómo maneja SQL Server los datos comprimidos en Columstore_Archive
Cuando se escribe un índice Columnstore_Archive, SQL Server aplica la compresión LZ77 + Huffman a los segmentos Columnstore ya existentes. Al leer datos de un índice Columnstore Archive, SQL Server debe descomprimir estos segmentos antes de ejecutar la consulta, lo que implica un uso de CPU significativamente mayor.
Implementar Columstore_Archive
Si queremos habilitar Columnstore_Archive en una tabla o índice usaremos el comando ALTER TABLE o ALTER INDEX de la siguiente manera:
1. Habilitar Columnstore_Archive en una partición
ALTER TABLE ColumnstoreTable1
REBUILD PARTITION = 1 WITH (
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);2. Habilitar Columnstore_Archive en todas las particiones
ALTER TABLE ColumnstoreTable1
REBUILD PARTITION = ALL WITH (
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);3. Habilitar Columnstore en todas las particiones y Columnstore_Archive en alguna
ALTER TABLE ColumnstoreTable1
REBUILD PARTITION = ALL WITH (
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (4, 5));3b. Otra forma de habilitar Columnstore en todas las particiones y Columnstore_Archive en alguna:
ALTER TABLE ColumnstoreTable1
REBUILD PARTITION = ALL WITH (
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (4, 5),
DATA COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1, 2, 3));Impacto en el rendimiento de Columnstore_Archive
Columnstore_Archive permite una reducción extrema del tamaño de almacenamiento, lo que lo hace ideal para entornos donde el espacio en disco o las copias de seguridad representan un coste significativo. Al disminuir el tamaño de los datos almacenados, se reducen los costes operativos y se optimiza el uso del almacenamiento, especialmente en bases de datos alojadas en la nube.
Sin embargo, esta ventaja viene acompañada de un mayor consumo de CPU en las consultas, ya que los datos deben ser descomprimidos en tiempo de ejecución. En escenarios donde las consultas analíticas son frecuentes y de gran volumen, este aumento en el uso de CPU puede impactar el rendimiento general del sistema, por lo que es fundamental evaluar su aplicación caso por caso.
Casos de uso ideales para Columnstore_Archive
El uso de Columnstore_Archive está especialmente indicado en escenarios donde los datos almacenados son mayormente de solo lectura o tienen un acceso esporádico. Tablas con registros históricos, auditorías o grandes volúmenes de datos que rara vez se consultan pueden beneficiarse enormemente de la reducción de almacenamiento sin que el impacto en la CPU sea un problema. En entornos de Data Warehouse donde la retención de datos es fundamental, Columnstore_Archive puede ser clave para reducir los costes de almacenamiento sin comprometer la integridad de los datos.
También es una opción interesante en Azure SQL Managed Instance y otras bases de datos en la nube, donde los costes de almacenamiento suelen ser elevados. Reducir el tamaño de la base de datos mediante Columnstore_Archive puede generar ahorros significativos, especialmente en cargas de trabajo que dependen de replicaciones geográficas y copias de seguridad, donde el tamaño de los datos afecta directamente los costes de operación.
Buenas prácticas con Columnstore_Archive
Para aprovechar al máximo Columnstore_Archive, es fundamental evaluar cuidadosamente qué tablas o índices pueden beneficiarse de esta compresión. No es recomendable aplicarlo en datos de acceso frecuente, ya que el proceso de descompresión puede generar una sobrecarga en la CPU que afecte el rendimiento de las consultas. Monitorizar el impacto en el rendimiento con herramientas como Query Store y ejecutar pruebas antes de aplicar la compresión en entornos de producción son pasos esenciales para garantizar que los beneficios en almacenamiento no se vean opacados por problemas de latencia.
Conclusión
Columnstore_Archive es una solución avanzada para la compresión extrema de datos en SQL Server, útil en escenarios donde el almacenamiento es la principal preocupación. Sin embargo, su mayor consumo de CPU puede ser un factor limitante en bases de datos con consultas frecuentes. Si el objetivo es maximizar la eficiencia del almacenamiento sin comprometer demasiado el rendimiento, Columnstore Archive es una opción poderosa que debe aplicarse estratégicamente en los casos adecuados. Una planificación cuidadosa y una evaluación continua del impacto en rendimiento permitirán sacar el máximo provecho de esta tecnología sin afectar la operativa de la base de datos.


