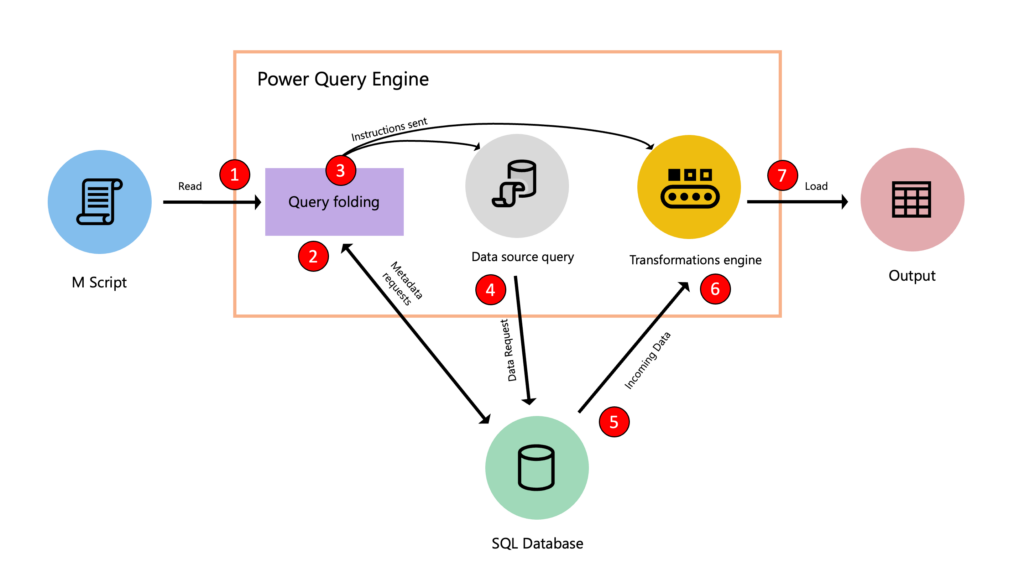
Hoy me he encontrado en LinkedIn con una cosa que me ha llamado la atención, Antonio Jurado había publicado un post en el blog mundo-datos respondiendo a un video de Nacho Cardenal. Este último habría publicado hace unos días la resolución al reto de FizzBuzz en Excel. En los comentarios de su publicación original en LinkedIn, Juan José Luna proponía la solución al reto en Access. A esto se sumó Toni (en la publicación que yo vi) resolviendo el reto en DAX. Así que, no vamos a ser nosotros menos y vamos a resolverlo en SQL, ¿no?
El reto FizzBuzz
El reto FizzBuzz es un sencillo desafío de programación que se emplea en las entrevistas de trabajo técnicas para que el evaluador vea la capacidad de escribir código del candidato.
Como digo, el reto es sencillo, debes codificar un algoritmo que, con los números del 1 al 100 devuelva la cadena “Fizz” si el número es múltiplo de 3, “Buzz” si es múltiplo de 5 o “FizzBuzz” si es múltiplo de 3 y de 5.
Esto es lo que buscamos:
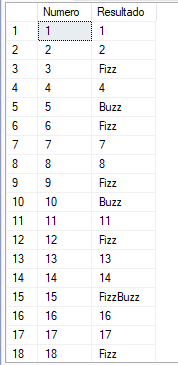
FizzBuzz con T-SQL
Esto es sencillo, tenemos que crear una tabla con los números del 1 al 100 y una columna resultado que será FizzBuzz, Fizz, Buzz o el propio número. Vamos a ello.
Paso 1: Crear la tabla FizzBuzz
El primer paso es crear la tabla FizzBuzz, para ello vamos a comprobar primero si existe y en ese caso la borramos y creamos una nueva. Necesitamos un campo numérico que admita los valores del 1 al 100, con un tinyint nos vale, no vamos a usar más de lo necesario. Para el resultado tendremos que almacenar cadenas de texto pero, no siempre van a tener la misma longitud, podrán ser de 1 a 8 caracteres así que usaremos un varchar(8).

Paso 2: Cargar la secuencia de números
Con la tabla ya creada vamos a empezar a cargar los datos, lo primero será cargar los números que luego vamos a evaluar. Para ello empezamos con la sintaxis INSERT INTO ya que la tabla existe de antes. A este insert le vamos a pasar el resultado de una función de tabla que se ha introducido nueva en SQL Server 2022, GENERATE_SERIES. Esta función tendrá como primer parámetro el primer número de nuestra cadena, como segundo el último y, opcionalmente, como tercero el número en el que se va a incrementar el contador. Como este tercer parámetro es opcional y si no ponemos nada va de uno en uno lo vamos a omitir.

Paso 3: Algoritmo FizzBuzz
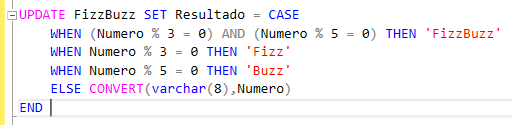
Llegó el momento de la verdad, hasta ahora solo habíamos preparado el escenario. Tenemos que actualizar nuestra tabla para poner los valores Fizz, Buzz o FizzBuzz cuando sea necesario. Lo primero que tendremos que saber es que en SQL Server podemos usar el operador % para devolver el resto de una división, por lo que si este es igual a 0 será que el número es múltiplo del dividendo que estemos comparando. Una vez tenemos eso resulto nos encontramos con el siguiente reto, para hacerlo de una sola vez tendremos que usar la sintaxis de UPDATE con un CASE dentro de la cláusula SET.
Hacer correctamente el case será nuestro tercer desafío, como sabéis, esta operación evalúa las condiciones en orden y si la primera de ellas se cumple ya no va a pasar por las siguientes. Esto hace que si o si tengamos que empezar por el caso de que un número sea múltiplo de 3 y de 5. A continuación ya podremos evaluar que sea múltiplo de 3 o de 5 en orden indistinto. Para terminar tenemos que devolver el mismo valor si no se ha cumplido con ninguna de las tres condiciones anteriores lo que nos puede dar más de un quebradero de cabeza si no estamos atentos. El tipo de datos del valor que estamos evaluando (el número) no se puede insertar en un campo de texto, antes tendremos que convertirlo o nos encontraremos con un error en la ejecución.
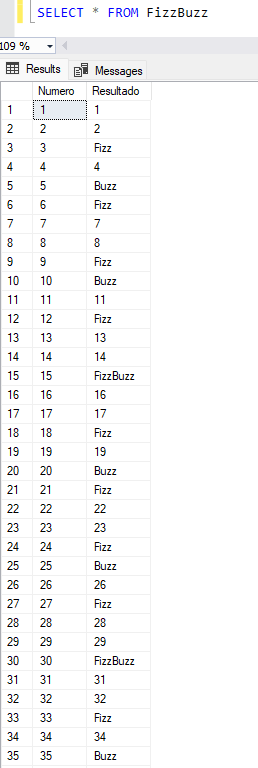
Paso 4: Mostrar los resultados
Ya hemos hecho lo difícil, ahora solo nos queda mostrar los resultados de nuestro trabajo.
Código de FizzBuzz
Ahora que ya hemos resuelto el desafío te dejo el código completo que he utilizado para que lo puedas copiar, editar e investigar tu mismo otras variaciones.
DROP TABLE IF EXISTS FizzBuzz
CREATE TABLE FizzBuzz (Numero tinyint, Resultado varchar(8))
INSERT INTO FizzBuzz (Numero)
SELECT * FROM GENERATE_SERIES(1, 100)
UPDATE FizzBuzz SET Resultado = CASE
WHEN (Numero % 3 = 0) AND (Numero % 5 = 0) THEN 'FizzBuzz'
WHEN Numero % 3 = 0 THEN 'Fizz'
WHEN Numero % 5 = 0 THEN 'Buzz'
ELSE CONVERT(varchar(8),Numero)
END
SELECT * FROM FizzBuzzConclusión
Así, de una manera sencilla y eficiente hemos resuelto el reto FizzBuzz en T-SQL, espero que te haya servido para aprender aunque sea alguna sintaxis que no conocías. ¿Se te ocurre otra solución posible? ¿Te apetece que hagamos más desafíos de este tipo? Pónmelo en comentarios y lo tendré muy en cuenta.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!