El artículo de hoy va para mis amigos analistas de datos, desarrolladores de BI y DBAs centrados en entornos datawarehouse aunque espero que sea también interesante para todos los demás. Hoy vamos a hablar del modelado en Power BI, existen muchas maneras de hacerlo pero al final, si el modelo va a tomar cierta envergadura, todo lo que no sea un modelo puro de estrella va a terminar dando mal rendimiento.
¿Qué es Power BI?
Empecemos por el principio, seguramente si eres analista de datos o desarrollador BI si sabes de lo que estoy hablando pero, permíteme un paréntesis, para que toda esa gente que está leyendo esto y no sabe muy bien de lo que hablamos parta desde el mismo punto. Al fin y al cabo este es un blog de DBAs.
Power BI es un software de Microsoft para inteligencia de negocio (de ahí su nombre) capaz de convertir datos de casi cualquier fuente en informes interactivos muy atractivos visualmente. Esta información que puede venir de cualquier fuente puede ser desde un fichero de texto plano separado hasta una potente base de datos relacional como SQL Server o las bases de datos SQL de Azure.

El flujo de trabajo de Power BI
A grandes rasgos, para empezar a trabajar en Power BI, debemos usar Power BI Desktop para conectar la información de las fuentes, modelarla en la propia aplicación y después, preparar los informes visuales.
Una vez generado el informe se puede almacenar en un archivo pbix para consumir con la aplicación Power BI Desktop en el equipo local o publicarla en Power BI Service que no es más que un SQL Server Reporting Service adaptado. Si habéis administrado este servicio anteriormente vais a ver que es prácticamente igual, solo cambia el origen de los reportes.
¿Qué es un modelo de estrella?
No es la primera vez que hablamos en el blog sobre los modelos de estrella, ya le dedicamos este artículo completo hace unos meses. Para refrescar las ideas, el modelo de estrella es una forma de organizar nuestros datos en base a una tabla central de hechos relacionada con varias tablas de dimensiones. Tener toda la información relevante en una misma tabla central lo convierte en un modelo optimizado para consultas de agrupaciones, justo lo que buscamos cuando elaboramos informes de BI. En este sentido, no es raro encontrarnos con tablas desnormalizadas, primando el rendimiento máximo de este tipo de lecturas sobre el ahorro de espacio y el rendimiento de escrituras.
Por qué usar un modelo de estrella en Power BI
Como ya hemos dicho, la mejor manera de modelar los datos en Power BI es con un modelo de estrella. Esto es así porque todos y cada uno de los objetos visuales que van a terminar componiendo los reportes van a realizar consultas contra el modelo de datos almacenado en la aplicación. Esas consultas además no tienen nada que ver con las consultas de selección de información a las que estamos acostumbrados a ver en una base de datos relacional, son consultas mucho más pesadas de filtrado, agregación, resumen y ordenación de los datos del modelo. Gracias a usar un modelo en estrella, las tablas de dimensiones admitirán el filtrado y la agregación mientras que sobre la tabla de hechos recaerá el resumen.
Es importante destacar que la tabla de hechos y las de dimensiones no se establecen como tal por ninguna propiedad que asigne el modelador de datos, simplemente son tablas normales que al aplicar las relaciones correctas terminan componiendo este modelo. Si seguimos a rajatabla los cánones y buenas prácticas, todas las relaciones serán de uno a muchos, siendo siempre uno en la tabla de dimensión y muchos en la de hechos.
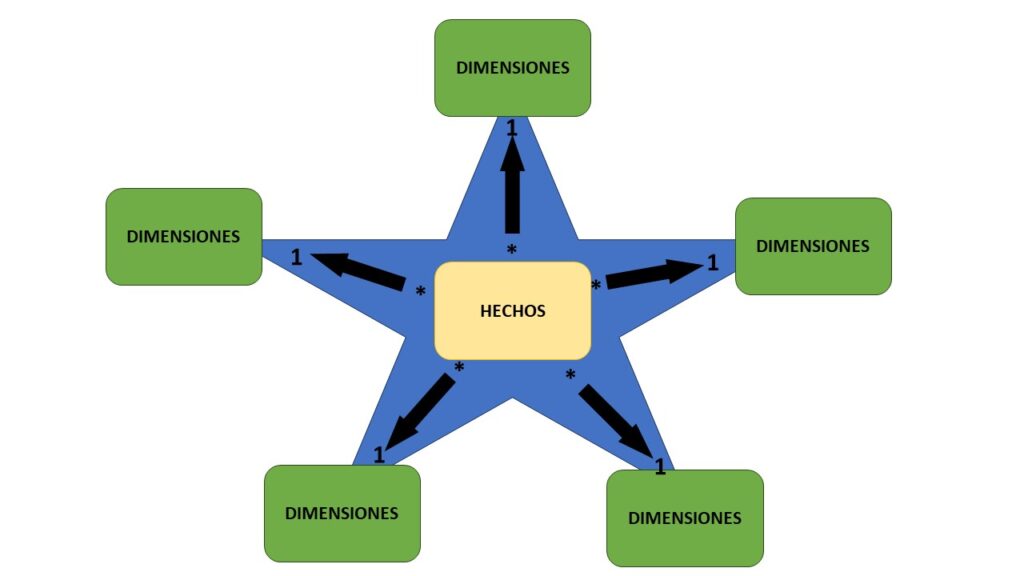
Un diseño bien modelado tendrá este aspecto que vemos en la imagen, con una tabla central de hechos relacionada con tantas tablas de dimensiones como sean necesarias y sin mezclar en una misma tabla dimensiones con hechos (Si estás perdido en este punto y no sabes la diferencia entre una tabla de hechos y una tabla de relaciones pásate por nuestro artículo sobre el modelo de estrella para descubrirlo).
Conceptos clave del modelo de estrella en Power BI
Ahora que ya conocemos la estructura ideal del modelo de estrella en Power BI vamos a tratar de entender los conceptos clave necesarios para una correcta implementación del mismo.
Medidas
Normalmente, cuando hablamos de un modelo de estrella, una medida es la columna de la tabla de hechos que almacena información que se va a resumir. Cuando llevamos esta implementación del modelo de estrella a Power BI, esta medida va a ser una fórmula escrita en DAX que permita resumir la información. Lo más normal será encontrarnos con fórmulas MAX, MIN o AVG para generar un valor que consumir. Estos valores nunca se almacenan en el modelo. En Power BI, existen además una serie de medidas automáticas llamadas medidas implícitas para consumirse en el informe visual llamadas medidas implícitas.
Claves suplentes
Son el identificador único de las tablas de dimensiones, lo que en base de datos conocemos como clave primaria. Estas claves en Power BI tienen la particularidad de no poder ser compuestas, tienen que ser una única columna. Es común tener que generar una columna con los datos de otras concatenados para que actúe como clave suplente aunque la mejor idea es agregar un identificador único a la tabla ya que de esa manera las relaciones con la tabla de hechos serán más fluidas.
Tablas de hechos sin hechos
En ocasiones es posible encontrarnos con la necesidad de crear una tabla de hechos que realmente no almacene ningún hecho. Por ejemplo una tabla de log de logins donde almacenamos una fecha de inicio de sesión donde el hecho realmente será el conteo de filas correspondiente a los inicios de sesión de los usuarios. Otra opción para utilizar este tipo de tabla es la típica tabla que almacena relaciones con las claves de otras dos tablas, tabla que es necesaria muchas veces para tener el modelo normalizado.
Dimensiones especiales en Power BI
Ya vimos en nuestro artículo sobre el modelo de estrella lo que eran las dimensiones, también llevamos todas estas líneas hablando sobre ellas. Sin embargo, en el mundo del análisis de datos y en concreto en Power BI existen unos tipos especiales de dimensiones que debemos conocer.
Dimensiones de copo de nieve
Las dimensiones de copo de nieve son conjuntos de tablas normalizadas que representan una única entidad de negocio o propiedad de un objeto. Por ejemplo, en la mayoría de ERP y software de gestión de almacén y ventas es común encontrar las propiedades categoría y subcategoría para los artículos. Esta idea, trasladada a un modelo normalizado, nos mostrará tres tablas, la de categorías, la de subcategorías y la de productos o artículos.
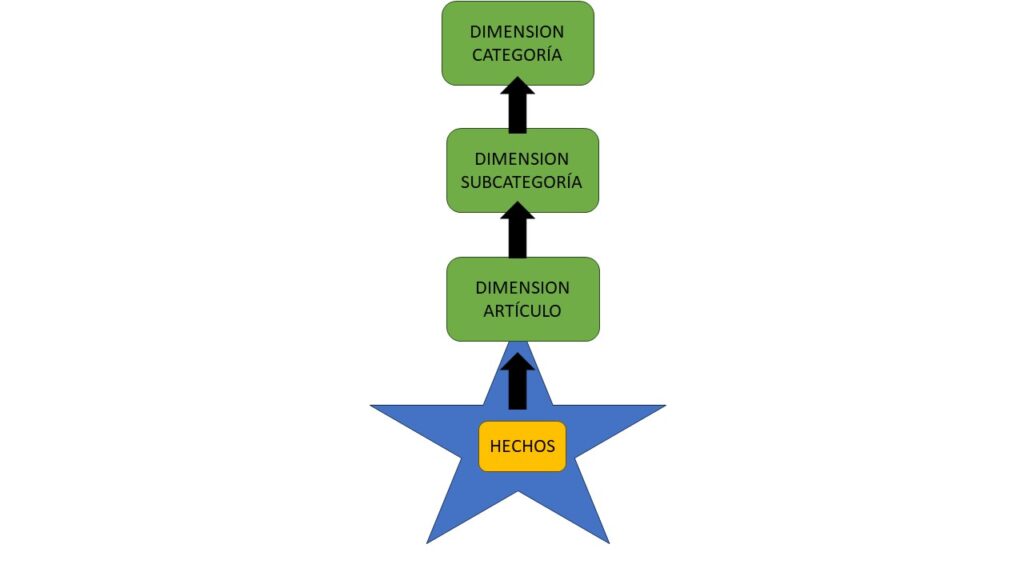
Si optamos por imitar el modelo de origen en Power BI en vez de desnormalizar el modelo y almacenar una única tabla de dimensiones no será lo más óptimo ya que deberemos cargar más tablas y más columnas clave. Además las fórmulas para definir las relaciones serán más largas y complejas complicando la propagación de filtros entre las tablas. Esto se traduce en un mayor número de campos en el panel para diseñar el informe visual, lo que también puede complicar la experiencia. Aunque parezca una buena idea a fin de tener el modelo normalizado y ahorrar espacio, a la larga, nos va a generar problemas debido a la limitación de Power BI de crear una jerarquía que abarque todas las tablas.
Dimensiones de variación lenta
Las dimensiones de variación lenta o dimensiones lentamente cambiantes (SCD por sus siglas en inglés) son aquellas que administran correctamente el cambio a lo largo del tiempo. Las SCD pueden admitir cambios de tipo 1, de tipo 2 o ambos a la vez.
El cambio tipo 1 es aquel que al producirse modifica todo el historial pasado, no nos interesa el histórico y solo queremos saber el valor actual. Sin embargo un cambio tipo 2 se almacena en un nuevo registro, sin sustituir el anterior. Por ejemplo, imaginad que tenemos una tienda de pulseras y nuestro principal cliente son hombres casados que compran regalos a sus esposas. Nuestra tabla de clientes es una dimensión, en esta tabla tenemos datos como el correo electrónico o el teléfono para enviarles promociones. Si estos datos cambian, no nos interesa almacenar el historial, con tener el dato actualizado es suficiente. Esto es un cambio tipo 1.
Sin embargo, hay otro campo de la dimensión clientes que es el estado civil y, en ese, si que necesitamos un historial. Saber cuántas veces pasan nuestros clientes de soltero a casado o casado a soltero y cuánto tiempo pasa de media entre cada etapa puede ser de gran ayuda para nuestros analistas de datos y sus modelos de predicción de ventas.
Podríamos tener otro tipo de dimensión cambiante como el precio de nuestros artículos de venta pero, si estos cambian rápidamente, lo mejor será almacenar esa información en la tabla de hechos.
Dimensiones realizadoras de roles
Existen dimensiones que, por sus características, pueden filtrar los hechos de maneras diferentes. Por ejemplo, imagina nuestro ejemplo anterior donde teníamos una tienda de pulseras, la dimensión fecha es capaz de realizar filtros por fecha de pedido, fecha de envío, fecha de cobro o incluso por fecha de alta de un cliente.
En Power BI podríamos definir varias relaciones entre nuestra dimensión fecha y la tabla con los hechos, sin embargo, solo una de las relaciones puede estar activa. Tener una única relación activa implicará la propagación de filtros sobre la dimensión a la tabla de hechos. Técnicamente es posible usar relaciones inactivas pero para ello el desarrollador del informe tendrá que usar la función DAX USERELATIONSHIP. Esto puede resultar complicado tanto por el uso de código extra como por la cantidad de campos generados en el panel de construcción de reportes.
Un enfoque común para superar estas limitaciones es, al modelar, crear varias tablas de dimensiones con la misma información duplicada de manera que cada una de ellas tenga una instancia realizadora de roles (filtrados). Es un precio menor a pagar ya que, por lo general ( y por definición), las tablas de dimensiones son relativamente pequeñas en comparación con los hechos.
Dimensiones no deseadas
Al trasladar datos de un modelo origen a nuestro modelo de Power BI es común encontrarnos con dimensiones no deseadas. Una dimensión no deseada puede ser útil cuando las dimensiones constan de pocos atributos y a su vez estos de pocos valores. En estos casos, puede ser una buena idea realizar un producto cartesiano de ambas dimensiones en una sola. Por ejemplo, volvamos a nuestra tienda, tenemos una dimensión que almacena un único atributo que es el estado de los pedidos y los valores que acepta son pedido recibido, pedido recibido y pedido completado. A su vez, tenemos otra dimensión con otro único atributo que es el estado de envío del pedido y admite los valores no enviado, enviado y entregado. En este caso, podríamos combinar ambas dimensiones del origen en una sola en nuestro modelo de estrella.
Dimensiones degeneradas
Una dimensión degenerada en el modelado de Power BI se refiere a un atributo de datos que funciona como una dimensión, pero que en realidad se almacena en la tabla de hechos, en lugar de en su propia tabla de dimensión separada. Es una excepción a la regla de oro que hemos comentado al principio de no mezclar hechos y dimensiones en una sola tabla. En otras palabras, es una clave de dimensión que se almacena en una tabla de hechos y no se une a una tabla de dimensiones correspondiente porque todos sus atributos ya se han colocado en otras dimensiones. Esto elimina la necesidad de unir otra tabla de dimensiones.
Conclusión
¿Aún sigues leyendo a estas alturas? ¿Después de casi 2000 palabras? Si es así y no has saltado directamente a este apartado gracias. Como habrás podido ver el modelado en power BI pasa por un modelo de estrella estricto para obtener un buen rendimiento. Sin embargo, esto de la ciencia de datos tiene mucho de arte también y son los analistas, científicos y arquitectos de datos los que van a modelar los datos a medida para el mejor rendimiento de sus informes. De la teoría a la práctica ya sabes que hay un mundo y eso solo te lo da la experiencia y haber hecho muchas pruebas. Como hemos visto en el artículo, sobre todo en esta última parte, hay excepciones incluso para el primer mandamiento del modelador de no mezclar hechos con dimensiones. Espero que hayas aprendido los fundamentos básicos de esta ciencia.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!