SQL Server 2025 ya no mira los vectores desde la barrera. Tenemos tipo vector, búsqueda exacta con VECTOR_DISTANCE y búsqueda aproximada con CREATE VECTOR INDEX y VECTOR_SEARCH, todo ello sobre una implementación que Microsoft vincula de forma explícita con DiskANN. No es una curiosidad de laboratorio ni una feature ornamental para demos con palabras como “semántico” y “copilot” repetidas ocho veces por minuto. Es una apuesta técnica real, todavía con partes en preview, pero real.
Ahora bien, una cosa es que el motor ya hable vectores y otra muy distinta que haya dejado de ser SQL Server. Cuando mezclamos embeddings con filtros relacionales, claves, joins y diseño físico serio, aparecen las costuras. Y eso es precisamente lo interesante. Porque el problema no está en que exista DiskANN, sino en cómo aterriza dentro de un motor que no nació para resolver búsquedas de proximidad semántica sobre datos de negocio.
Antes de entrar en el índice, conviene situar el problema. No para repetir una introducción de manual sobre IA, sino para dejar claro por qué esta funcionalidad no se comporta como un índice relacional clásico con mejor prensa.
Vectores, embeddings y kNN: no buscamos igualdad, buscamos cercanía
Un vector es una secuencia ordenada de números. En SQL Server se almacena con el tipo vector, que internamente usa un formato binario optimizado, aunque se presente como array JSON por comodidad. Cada dimensión ocupa 4 bytes en float32 y SQL Server 2025 añade soporte preview para float16, lo que abre una vía interesante para reducir espacio cuando la precisión lo permita.
Un embedding es un caso particular de vector: una representación numérica que intenta capturar características relevantes de un texto, una imagen o cualquier otro objeto. La consecuencia práctica es que dejamos de preguntar “¿es igual?” o “¿está entre A y B?” y pasamos a preguntar “¿qué está cerca de esto?”. Ese cambio parece pequeño hasta que toca ejecutar consultas. Entonces deja de ser filosofía y pasa a ser coste.
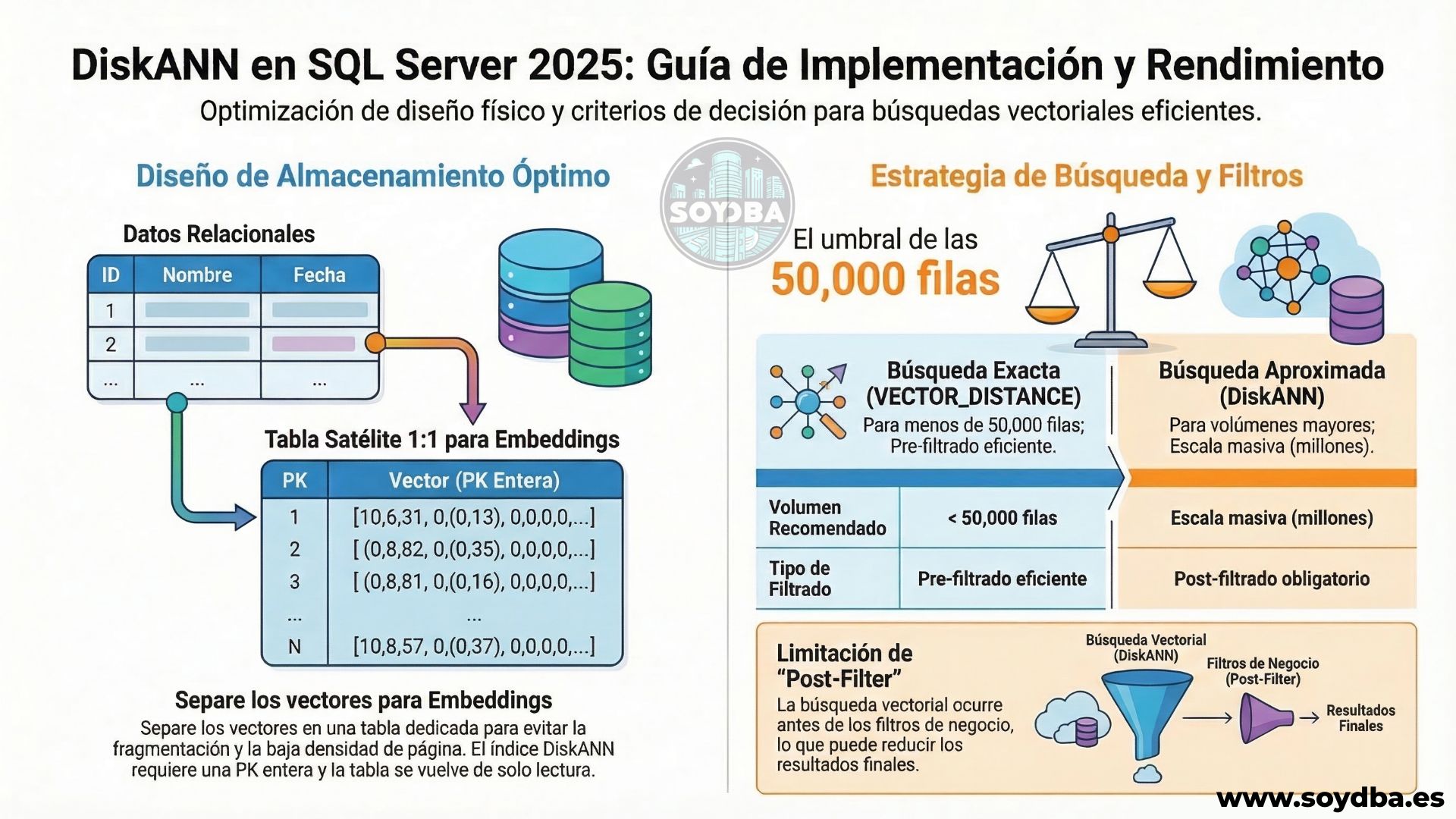
Cuando resolvemos el problema de forma exacta, hacemos un kNN exacto: calculamos distancia contra todos los candidatos y nos quedamos con los más próximos. Microsoft lo describe así en su documentación y, además, deja una recomendación bastante útil: la búsqueda exacta sigue teniendo sentido cuando el conjunto efectivo a revisar es pequeño, con una orientación general de unas 50.000 filas o menos después de aplicar predicados. Ese matiz importa mucho, porque evita uno de los errores más comunes: asumir que lo aproximado siempre es mejor solo porque tiene nombre moderno.
Hasta aquí el problema. La siguiente pregunta es evidente: cuando el volumen crece, ¿cómo evitamos que cada consulta termine pareciendo una inspección completa del universo conocido?
DiskANN: el “cómo” de Microsoft para escalar búsqueda vectorial
La respuesta de Microsoft para búsqueda aproximada es DiskANN. Conviene decirlo bien para no arrastrar una imagen mental equivocada: DiskANN no ordena vectores como si fuera un B-tree extraño. Es una familia de algoritmos de ANNS basada en grafos, pensada para combinar precisión razonable, baja latencia y uso eficiente de memoria y SSD. Microsoft Research describe Project Akupara precisamente como una línea de trabajo orientada a escalar ANNS para búsqueda y recomendación a gran escala, y la publicación original de 2019 presenta DiskANN como un sistema capaz de indexar y buscar mil millones de puntos en una sola máquina usando 64 GB de RAM y SSD.
La gracia de ese enfoque no es solo académica. Microsoft ha ido consolidando DiskANN como base tecnológica en su ecosistema, y SQL Server 2025 lo expone directamente en CREATE VECTOR INDEX con TYPE = ‘DISKANN’. En otras palabras, no estamos ante una abstracción vaporosa; el motor te deja tocarla. Y eso siempre es más útil que una promesa de roadmap adornada con iconos de nube.
Pero aquí aparece el primer matiz importante para cualquiera que haya peleado con diseño físico de tablas. Que SQL Server pueda almacenar vectores no significa que debamos meterlos sin pensar en la tabla principal, como si una fila de negocio de 100 bytes y un embedding de 1.536 dimensiones fuesen vecinos naturales. No lo son.
La decisión de modelado que más sentido tiene
Mi recomendación sigue siendo separar los embeddings en una tabla satélite 1:1 respecto a la tabla relacional principal. No por postureo arquitectónico, sino porque el coste físico de mezclar ambas cosas en la misma fila es demasiado alto para fingir que no existe. Microsoft lo explica con un ejemplo muy claro en su FAQ: una página de datos admite hasta 8.060 bytes (8 Kb) y un vector de 1.024 dimensiones en float32 ocupa 4.104 bytes contando cabecera, lo que ya limita a un solo vector por página. Si subimos dimensiones, el efecto no mejora precisamente.
Eso no significa solo “más fragmentación”, que es la forma rápida de contarlo. Significa también menos densidad de página, más I/O, peor aprovechamiento de caché y más penalización para accesos relacionales que no necesitan tocar el embedding. La guía de diseño de índices de SQL Server insiste en mantener los índices, en especial el clustered, lo más estrechos posible. Y aquí conviene recordar algo bastante básico, si la tabla principal sirve para OLTP o para consultas relacionales normales, meter una columna vectorial enorme ahí dentro porque “ya la usamos en algunas búsquedas” es una forma muy creativa de castigar todo lo demás.
Hay además un segundo argumento, todavía más relevante porque los índices vectoriales aproximados y VECTOR_SEARCH siguen en preview dentro de SQL Server 2025. La tabla que tiene un vector index debe tener una PK clustered entera de una sola columna y, mientras el índice exista, esa tabla queda de solo lectura. En SQL Server 2025 no está disponible ALLOW_STALE_VECTOR_INDEX, así que si cambian los datos toca recrear el índice. Separar embeddings en una tabla 1:1 aísla esa rigidez donde corresponde y evita congelar la tabla relacional principal.
De hecho, el propio material de Microsoft ya deja entrever ese patrón. En los ejemplos de VECTOR_SEARCH aparece una tabla llamada wikipedia_articles_embeddings, lo que sugiere un diseño separado para los vectores frente al contenido relacional o documental. No es una norma escrita en piedra, pero tampoco parece casualidad.
Una vez aceptado ese modelo, la consulta cambia. Y ahí es donde aparece la parte realmente delicada: el JOIN mejora el diseño físico, pero no convierte mágicamente la búsqueda vectorial en algo filter-aware.
¿Qué cambia en la consulta cuando el embedding vive fuera?
Con un diseño 1:1, lo lógico es que VECTOR_SEARCH se ejecute sobre la tabla de embeddings y luego se haga JOIN con la tabla relacional para recuperar atributos de negocio y aplicar filtros. Ese patrón encaja perfectamente con el estado actual del producto, porque VECTOR_SEARCH solo admite tablas base; no puede apuntar a una vista ni a una tabla temporal intermedia ya filtrada. Además, si encuentra un índice ANN compatible en esa columna y con la misma métrica, lo usa; si no, vuelve a kNN.
CREATE TABLE dbo.Documents
(
DocumentId int NOT NULL PRIMARY KEY,
TenantId int NOT NULL,
IsActive bit NOT NULL,
Title nvarchar(200) NOT NULL
);
CREATE TABLE dbo.DocumentEmbeddings
(
DocumentId int NOT NULL PRIMARY KEY CLUSTERED,
Embedding vector(1536) NOT NULL,
CONSTRAINT FK_DocumentEmbeddings_Documents
FOREIGN KEY (DocumentId) REFERENCES dbo.Documents(DocumentId)
);
CREATE VECTOR INDEX IX_DocumentEmbeddings_Embedding
ON dbo.DocumentEmbeddings (Embedding)
WITH (METRIC = 'COSINE', TYPE = 'DISKANN');La consulta natural sería algo así:
DECLARE @qv vector(1536) = ...;
SELECT d.DocumentId,
d.Title,
s.distance
FROM VECTOR_SEARCH(
TABLE = dbo.DocumentEmbeddings AS e,
COLUMN = Embedding,
SIMILAR_TO = @qv,
METRIC = 'cosine',
TOP_N = 50
) AS s
JOIN dbo.Documents AS d
ON d.DocumentId = s.DocumentId
WHERE d.TenantId = 42
AND d.IsActive = 1
ORDER BY s.distance;Esto está bien desde el punto de vista del modelo físico. La tabla principal sigue estrecha, el índice vectorial vive donde debe y el JOIN 1:1, sobre una clave entera, normalmente será barato. Lo que no cambia es el orden lógico de la operación ANN respecto a los predicados de negocio. Y ahí vuelve a entrar el jarro de agua fría.
El JOIN no arregla el post-filter: solo mueve la frontera
La documentación de VECTOR_SEARCH es bastante clara, la búsqueda vectorial ocurre antes de aplicar cualquier predicado, y los filtros adicionales se evalúan después de devolver los vecinos más similares. Microsoft lo llama post-filter only. Si pides TOP_N = 10 y luego filtras por TenantId o IsActive, puedes acabar con menos de 10 filas o incluso con ninguna. Eso vale igual si el filtro cae sobre la misma tabla que contiene el embedding o si llega desde una tabla relacionada mediante JOIN. El JOIN no cambia esa semántica.
Eso significa que separar embeddings sí mejora el diseño físico, pero no resuelve la principal limitación actual del ANN en SQL Server 2025. El trabajo más caro sigue siendo la navegación del índice DiskANN sobre el conjunto indexado. Si después un filtro de negocio es muy selectivo, la forma de compensarlo suele ser sobremuestrear, subiendo TOP_N para tener suficientes candidatos válidos tras el JOIN y el WHERE. Y cuanto más selectivo sea el filtro, más se erosiona la ventaja del índice aproximado.
Aquí conviene evitar una confusión habitual. El problema no es que el JOIN sea especialmente caro. En una relación 1:1 bien indexada, no suele serlo. El problema es que el filtro relacional llega tarde para ayudar a la fase ANN. Y eso no lo arregla un buen modelo lógico, porque es una consecuencia de cómo está implementado el acceso vectorial hoy en el motor.
La pregunta entonces ya no es si separar la tabla, que para mí sí, sino cuándo conviene dejar de insistir con ANN y volver, sin complejos, a la búsqueda exacta.
¿Por qué no puedes filtrar antes sin romper algo?
La base técnica está bien documentada en la investigación de Microsoft sobre Filtered-DiskANN. El problema de los filtros en ANNS no se resuelve bien tocando solo la fase de búsqueda. El paper critica precisamente el enfoque de postprocesado, porque para filtros de baja especificidad puede obligar a recuperar muchísimos candidatos antes de encontrar uno que cumpla el predicado. Pero también deja claro que la solución trivial de “un índice por filtro” no escala.
La razón de fondo es que un índice tipo DiskANN es un grafo global construido sobre todos los vectores. Durante la búsqueda, algunos nodos no son resultados finales interesantes, pero sí son cruciales como puentes para navegar hacia la zona correcta del espacio vectorial. Si yo aplico un filtro arbitrario antes de buscar y elimino parte de esos nodos, puedo romper la navegabilidad efectiva del grafo. Dicho de otra manera, el subconjunto filtrado no conserva necesariamente las propiedades del índice original. Y eso afecta al recall, al coste o a ambas cosas.
Por eso filtered ANN de verdad no consiste en “empujar el WHERE hacia abajo” y quedarse tan ancho. Requiere índices diseñados con consciencia de filtro, estrategias de construcción distintas o, al menos, estructuras auxiliares que permitan no destrozar el recorrido. Ahí es donde la investigación va por delante de la implementación actual del motor. Y sinceramente, mejor admitirlo que fingir que un predicado sobre TenantId va a integrarse solo por buena voluntad. También podríamos confiar en MERGE en producción, pero cada uno gestiona sus traumas como puede.
A partir de aquí, la pregunta útil deja de ser “siempre ANN o siempre exacto” y pasa a ser mucho más adulta: “¿cuándo me compensa cada enfoque en SQL Server 2025?”.
¿Cuándo DiskANN tiene sentido y cuándo es mejor volver a VECTOR_DISTANCE?
Si el corpus es grande y los filtros relacionales son débiles, VECTOR_SEARCH con DiskANN es la opción natural. Para eso existe, para reducir latencia y coste frente a un barrido completo. Pero si el patrón real de consulta siempre filtra fuerte por cliente, estado, región o cualquier dimensión de negocio que reduzca mucho el conjunto efectivo, entonces la recomendación oficial de Microsoft cobra todo el sentido del mundo: cuando acabas buscando sobre 50.000 vectores o menos, la búsqueda exacta con VECTOR_DISTANCE vuelve a ser una alternativa muy seria.
Y aquí, precisamente, la separación 1:1 juega a favor. Puedes filtrar primero en la tabla relacional, quedarte con el subconjunto de negocio que realmente importa, hacer el JOIN hacia la tabla de embeddings y calcular distancias solo sobre esos candidatos. Es una estrategia mucho más alineada con el optimizador relacional clásico y, además, evita pedirle a un índice ANN global que resuelva con elegancia algo para lo que no ha sido diseñado. Sí, podemos pedirle heroicidades a cualquier índice. También podemos confiar en que un SELECT * no acabará mal. Pero a cierta altura de la película conviene distinguir entre esperanza y diseño.
Conclusión
SQL Server 2025 ha dado un paso importante con búsqueda vectorial nativa y DiskANN como base técnica para ANN. Eso merece atención, pruebas serias y bastante menos folklore del habitual. Pero también conviene poner cada pieza en su sitio. El mejor diseño, en la práctica, pasa por separar embeddings en una tabla 1:1, mantener la tabla relacional principal estrecha y aislar ahí las restricciones operativas del vector index. Eso es buena ingeniería de datos, no una preferencia estética.
Ahora bien, ese diseño no convierte VECTOR_SEARCH en filtered ANN. Hoy seguimos teniendo ANN global más post-filter relacional, aunque el filtro llegue por JOIN. Esa diferencia condiciona rendimiento, recall y criterio de uso. Entenderla no es un detalle menor. Es la diferencia entre usar la novedad con cabeza o descubrir, demasiado tarde, que el motor no estaba haciendo exactamente lo que tú dabas por supuesto. Y en bases de datos, como sabemos todos, dar cosas por supuestas suele salir carísimo.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!