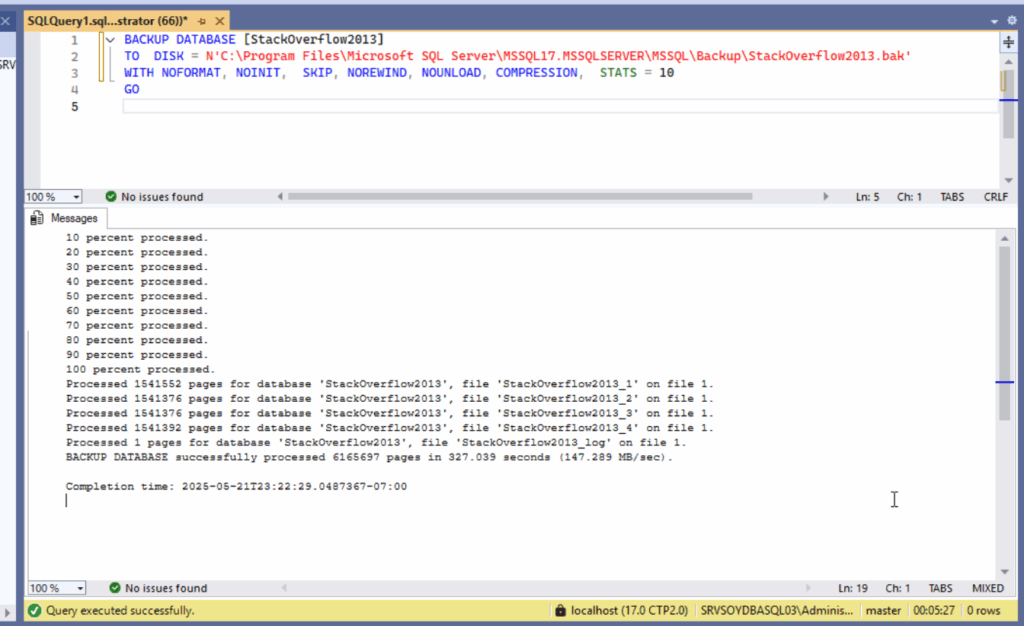
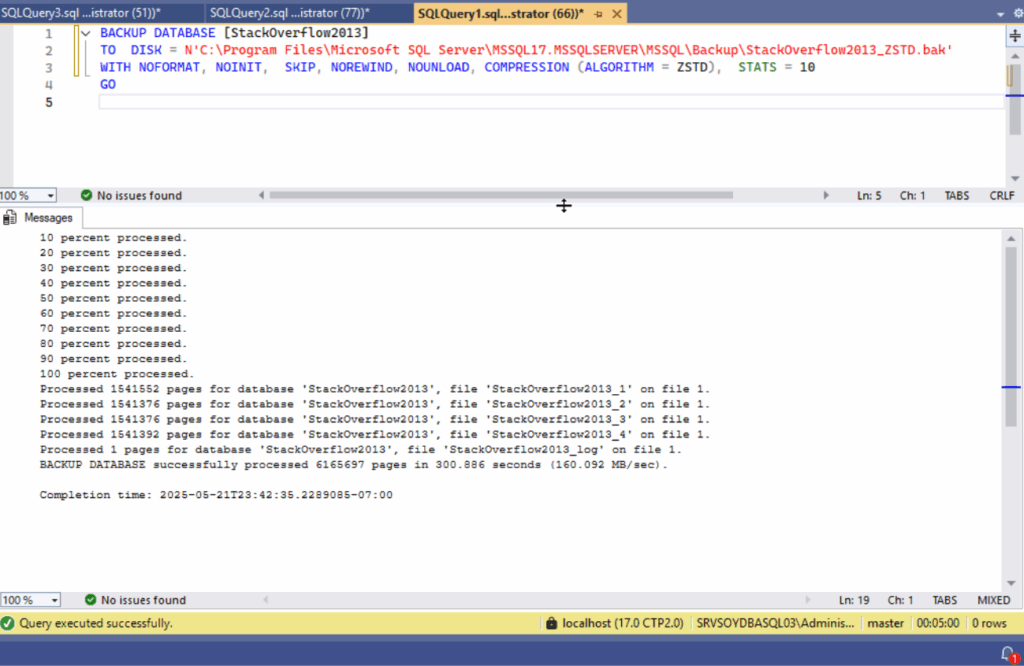
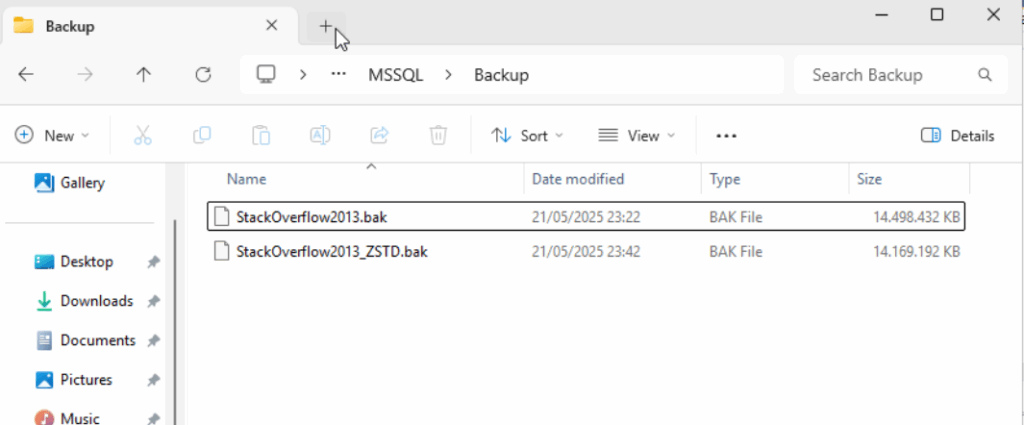
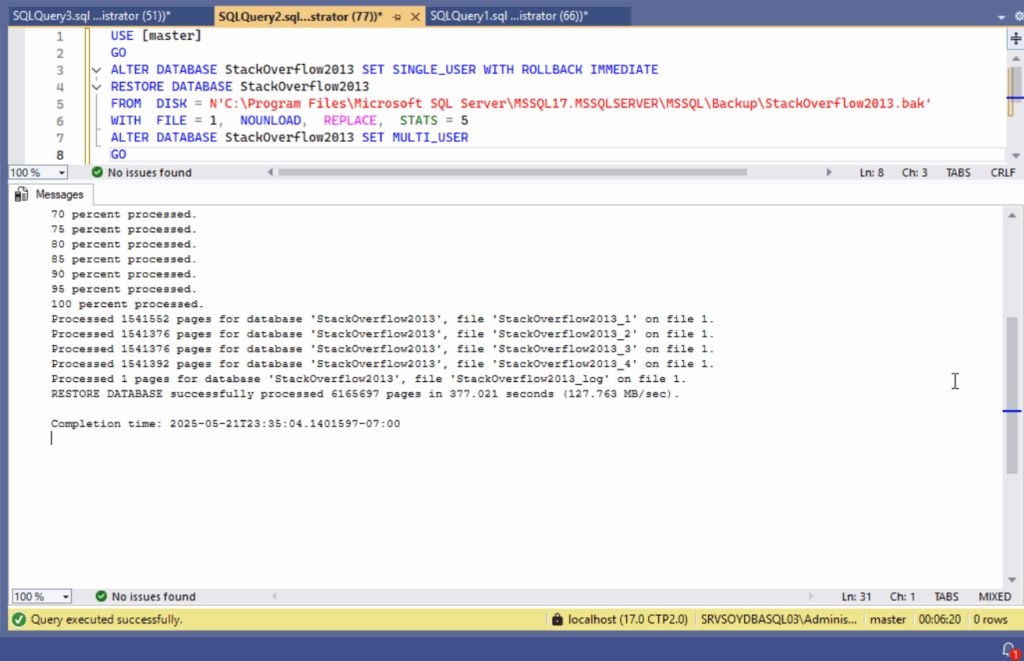
Hace poco, Brent Ozar publicó un artículo comentando una conversación en Reddit que planteaba una pregunta tan ingenua como recurrente: ¿de verdad hay DBAs cobrando un pastizal por trabajar 15 horas a la semana mientras el resto del tiempo ven vídeos o están “de guardia”?
Spoiler: sí, pero no es lo habitual, ni llega de la nada, ni cualquiera puede aspirar a eso. El artículo analiza muy bien los matices detrás de ese escenario, y ya que yo llevo más de una década trabajando con SQL Server, quiero aportar mi perspectiva sobre cómo se vive esto aquí. Porque el contexto importa, y mucho.
DBA de Infraestructura vs DBA de optimización
En el mercado español, y esto lo digo por experiencia directa, los perfiles DBA suelen dividirse claramente entre los que se encargan de la infraestructura y los que nos centramos en la optimización. Los primeros están más cerca del mundo sysadmin: alta disponibilidad, backups, parches, clústeres, automatización de tareas rutinarias. Los segundos vivimos más pegados al código: tuning de queries, revisión de planes de ejecución, diseño de índices y control del rendimiento.
Ahora bien, los que realmente marcamos la diferencia somos los que hemos aprendido a movernos en ambos mundos. Ese es el perfil que he desarrollado con los años y al que creo que todos deberíamos aspirar. No tiene sentido saber montar un AG perfecto si luego no detectas un SELECT * a pelo en una tabla de 300 millones de filas. Y viceversa.
El entorno lo define todo: DBA interno vs. DBA externalizado
Otra diferencia clave, y que marca el tipo de trabajo que hacemos, es si estamos dentro de un cliente final o trabajamos en una consultora o equipo de soporte multicliente.
Yo he pasado por ambos mundos, y la diferencia es abismal. Cuando estás en cliente final, con un parque de servidores limitado (pongamos menos de 20), tienes margen para hacer las cosas bien. Puedes auditar el entorno, meter procesos de automatización, eliminar errores históricos y acabar interviniendo en decisiones de diseño. Incluso te conviertes en un filtro obligado antes de subir cambios a producción.
Después de ese primer año o dos de “puesta a punto”, el trabajo se estabiliza. Las incidencias bajan, los entornos están controlados y puedes dedicar tiempo a tareas de más valor. A veces, incluso, te conviertes en esa figura que aparece poco… pero cuando aparece, es por algo serio.
En cambio, cuando estás en un cliente grande o en una consultora gestionando cientos o miles de servidores, el enfoque cambia. Hay que actuar por patrones, automatizar a escala y asumir que no vas a conocer cada entorno al detalle. Te pasas más tiempo apagando fuegos que optimizando consultas. Lo urgente gana a lo importante, y profundizar se convierte en un lujo.
¿Y los desarrolladores que ejercen de DBA?
Aquí conviene puntualizar. Existen desarrolladores SQL que asumen funciones de DBA y lo hacen bien. He trabajado con varios y sé que hay perfiles muy sólidos que entienden el motor, cuidan el rendimiento, diseñan esquemas con criterio y se preocupan por el coste real de sus consultas.
Este artículo también va por ellos. Porque son, en esencia, parte del mismo ecosistema. Saben lo que hacen, aunque su tarjeta no ponga “DBA”.
Ahora bien, también todos hemos visto el otro extremo, equipos donde nadie tiene perfil de base de datos y se asume que “el que más sabe de SQL” llevará los servidores. En esos casos, se sobrevive como se puede. Backups por defecto (con suerte), configuraciones sin revisar y scripts de producción lanzados con los dedos cruzados.
No es raro ver scripts de mantenimiento programados en el Post-it Engine, versión papel pegado al monitor. Y la documentación vive, cómo no, en la bandeja de entrada de alguien que ya no está en la empresa.
No es raro, pero no es lo que nos interesa hoy. Aquí estamos hablando de roles expertos. De gente que sabe lo que es un latch y por qué TEMPDB puede ser un cuello de botella aunque no tenga muchos datos.
¿Trabajar 15 horas o menos a la semana como DBA? Sí, pero no como te imaginas
Lo que cuenta Brent sobre ese DBA que trabaja 15 horas a la semana o menos y el resto del tiempo está en “modo guardia” es perfectamente posible. Pero no es un privilegio aleatorio, ni una herencia. Es el resultado de años de trabajo bien hecho.
Yo he estado en esa posición. He tenido entornos donde, después de automatizar, revisar, auditar y consolidar, apenas había incidencias. Y cuando las había, las resolvía rápido. No porque tuviera suerte, sino porque conocía el entorno al detalle.
En esos escenarios, no estás “siempre productivo”. De hecho, a veces ni siquiera un 10% del tiempo. Pero cuando hay un problema, tu intervención marca la diferencia. No puedes dudar, no puedes consultar la documentación. Tienes que actuar con precisión y rapidez. Porque si tardas 30 minutos más de la cuenta, el sistema de ventas se cae, el almacén se para o la factura al cliente se multiplica por dos.
No estás al 100%. Ni falta que hace. Estás como los extintores: colgado en la pared, sin moverse, hasta que alguien grita y hay que actuar. Solo que tú sabes más de índices que de espuma.
Este tipo de puesto no es para cualquiera. Y desde luego, no es un trabajo cómodo. Es un rol de alta responsabilidad y alta exigencia, aunque no lo parezca desde fuera.
¿El rol del DBA está en peligro?
Llevamos años oyendo que el DBA está muerto. Que si la nube automatiza todo, que si los desarrolladores se bastan solos, que si la IA lo va a arreglar todo con cuatro sugerencias inteligentes.
La realidad es que el rol está cambiando, no desapareciendo. Los DBAs de infraestructura han tenido que evolucionar hacia entornos híbridos, servicios PaaS, IaC, automatización. Pero los problemas siguen existiendo, solo que tienen otro nombre.
Y los DBAs de optimización somos ahora más importantes que nunca. Especialmente en entornos cloud, donde cada milisegundo extra tiene un precio literal. Cuando un SELECT mal optimizado empieza a generar 30 euros por hora de DTUs, todo el mundo mira al DBA. No al desarrollador, no al arquitecto, no al jefe de proyecto. A nosotros.
Las herramientas (de IA o no) que prometen optimizarlo todo aún están lejos de ser útiles, al menos sin intervención. Usamos Copilot, sí. Pero lo que da miedo no es lo que sugiere, sino que alguien lo acepte sin parpadear.
Copilot a veces acierta… como un reloj parado. Dos veces al día, da una respuesta aceptable. El problema es todo lo que sugiere entre medias.
Saber distinguir el buen consejo del disparate es, y seguirá siendo, trabajo nuestro.
Conclusión: menos horas, más impacto
Trabajar 15 horas a la semana o menos no significa trabajar poco. Significa haber llegado a un punto donde aportamos valor real justo cuando hace falta.
No estamos todo el día productivos. Pero cuando algo revienta, actuamos con decisión. Y eso solo se consigue con años de experiencia, conocimiento técnico profundo y sangre fría. Porque cada minuto cuenta cuando la producción está caída.
El puesto de DBA no está en peligro. Lo que está en peligro es seguir pensando que esto va de hacer backups y mirar gráficas. El futuro es de los que afinan, automatizan y cuando hay que actuar… no preguntan, resuelven. Y sí, puede parecer que no hacemos mucho. Pero cuando hacemos, salvamos el día, la semana y la cuenta de resultados de la empresa. Y eso vale más que cualquier KPI de los Project Manager.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!