Hacer un estudio de mercado sobre tecnologías de bases de datos es una de esas tareas que a primera vista suena a powerpoint corporativo, pero que en manos de técnicos con cicatrices se convierte en una radiografía útil del presente y futuro del sector. Así que vamos a destripar el Top-20 de DB‑Engines de agosto de 2025 sin frases motivadoras ni colorines innecesarios.
TDLR: lo relacional sigue mandando, lo NoSQL crece y lo demás se mueve al ritmo del hype y la nube.
¿Qué es DB‑Engines y por qué lo usamos como termómetro?
DB‑Engines es una iniciativa creada y mantenida por Red-Gate, una empresa especializada en tecnología de bases de datos. No es una asociación, ni un organismo oficial, ni un spin-off académico. Es una plataforma privada e independiente que publica un ranking mensual de sistemas de bases de datos en función de su popularidad.
¿Y qué mide exactamente?
Al contrario de lo que pudiera parecer no mide rendimiento, ni instalaciones reales, ni cuota de mercado. Mide señales públicas de atención y actividad técnica: menciones en foros, frecuencia de búsqueda en Google, apariciones en LinkedIn, preguntas en Stack Overflow, ofertas de trabajo y artículos técnicos publicados. Es decir, mide qué motores generan conversación, formación, interés profesional y visibilidad.
DB‑Engines también publica comparativas entre motores, artículos explicativos y datos históricos. Pero su producto estrella es el ranking mensual, seguido por empresas, arquitectos y responsables técnicos como referencia de tendencia, no como oráculo infalible. Si una tecnología sube, es porque hay más gente hablando de ella. Si baja, puede que siga en producción, pero ya no ocupa tantas portadas ni conferencias.
¿Refleja esto la realidad de los entornos críticos? No siempre. ¿Sirve para entender hacia dónde se mueve la conversación y, por tanto, la demanda de conocimiento? Sin duda. Lo usamos no porque sea perfecto, sino porque es el mejor termómetro disponible para medir la temperatura del mercado.
Relacional manda: sí, todavía
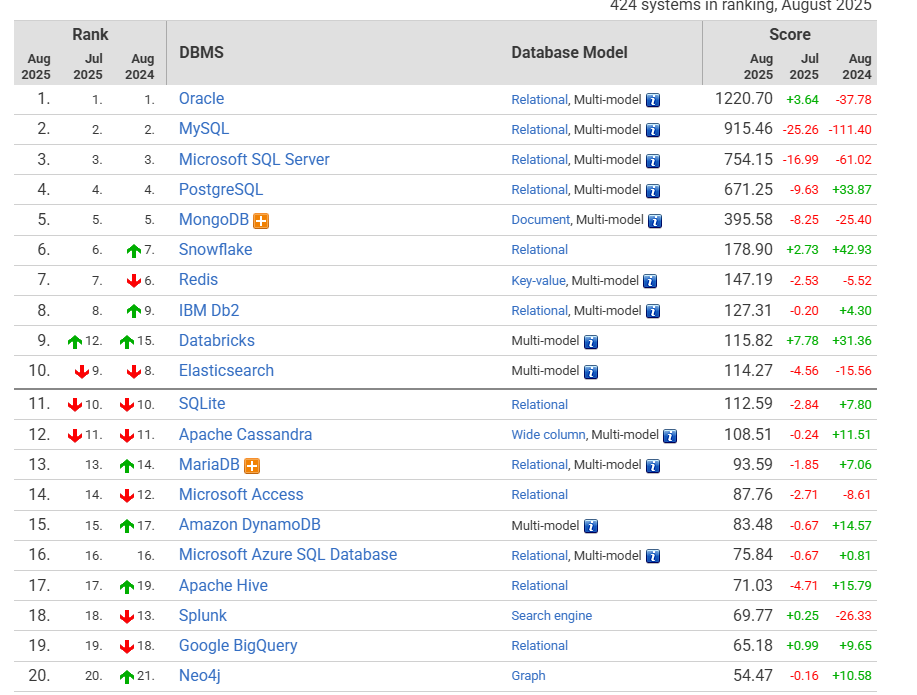
Del TOP 20 del ranking de motores de bases de datos, doce son relacionales puros o “multi-modelo con ADN relacional”. No hablamos solo de Oracle, MySQL, SQL Server y PostgreSQL; también están Snowflake, Db2, SQLite, MariaDB, Microsoft Access (sí, todavía), Azure SQL Database, Hive y BigQuery.
Traducción técnica: si tu carga es OLTP, OLAP o una mezcla de ambas, sigues teniendo un core relacional como referencia. Todo lo demás (documentales, grafos, clave-valor, búsqueda) se consolida como satélite especializado. No es que el NoSQL haya muerto. Es que no ha conquistado el núcleo.
PostgreSQL: el ganador moral
PostgreSQL sube más de 33 puntos en el año. No es casualidad. La comunidad lo adora, los hyperscalers lo ofrecen como servicio gestionado, y se adapta con extensiones que lo vuelven polivalente: pgvector para IA, Timescale para series temporales, FDW para federación, Logical Replication para entornos distribuidos.
¿La clave? Es open source de verdad, no con asterisco. Y satisface a arquitectos que quieren potencia sin vender un riñón por licencia. Es, en muchos proyectos nuevos, la elección por defecto. No por moda, sino por eficacia.
Oracle, MySQL y SQL Server: viejos reyes, nuevos entornos
Oracle sigue el primero, como lleva años. No porque haya ganado popularidad, sino porque sigue incrustado en el ADN de la empresa clásica: banca, seguros, administración pública. Sí, cuesta, pero funciona. Y nadie quiere reescribir 200 procedimientos PL/SQL con dependencias cruzadas.
MySQL pierde más de 110 puntos en un año. Lo usan millones, pero ya no es el chico cool de la fiesta. El stack web se ha fragmentado, y muchos han migrado a PostgreSQL o soluciones más específicas.
SQL Server, por su parte, mantiene el tercer puesto, pero ha perdido más de 60 puntos interanualmente. No es que haya desaparecido, pero la conversación pública se ha desplazado a otras plataformas. SQL Server sigue siendo caballo de batalla en empresas medianas y grandes, especialmente en entornos on-prem y Azure híbrido, donde la integración con Active Directory, SSIS, SSRS y otros clásicos de la casa siguen marcando la pauta.
Eso sí, atención a lo que viene, SQL Server 2025 está ya en preview y apunta maneras. Entre las novedades: mejoras notables en rendimiento, seguridad y compatibilidad híbrida con Azure Arc. También hay nuevos mecanismos de optimización automática, mejoras para entornos con alto volumen de transacciones y más integración con servicios de inteligencia artificial. Aún es pronto para saber si estas mejoras se traducirán en una remontada en el ranking, pero no sería raro que en 2026 viésemos un repunte de visibilidad técnica si la preview convence y la migración se acelera.
MongoDB: menos moda, más estabilidad
MongoDB cae en puntuación, pero sigue como NoSQL más alto. ¿Qué ha pasado? Básicamente, ha dejado de ser “la novedad”. Se ha convertido en una opción seria y estable, y eso le resta ruido en redes. Además, la competencia le viene desde dos frentes: PostgreSQL con JSONB y servicios documentales específicos en cloud (tipo Cosmos DB o DocumentDB).
¿Se sigue usando? Mucho. Pero ya no está en el centro de las conversaciones de arquitectos. Eso sí, en microservicios y aplicaciones event-driven, sigue encajando como un guante.
El ascenso silencioso: Snowflake, Databricks y BigQuery
Aquí es donde empieza el capítulo “analítica en cloud”. Snowflake sube casi 43 puntos en el año. Databricks, más de 31. BigQuery, casi 10. El patrón es claro: DWH y lakehouse se están moviendo a plataformas gestionadas con elasticidad real, integración con IA y modelos de costes más modernos (aunque no siempre más bajos, según el uso).
¿Lo mejor? Que estos motores no están pensados para sustituir tu base OLTP. Vienen a resolver el otro gran problema: consolidar, transformar y explotar datos a gran escala sin montar un zoo de clusters on-prem.
Redis, Cassandra y DynamoDB: NoSQL donde toca
Redis baja levemente, pero sigue siendo imprescindible. Si no lo usas para caché o colas, es probable que tengas un cuello de botella innecesario en tu arquitectura.
Cassandra sube 11 puntos. Sigue sin estar de moda, pero es uno de los pocos motores que realmente escala linealmente sin pedir milagros al throughput del disco.
DynamoDB sube más de 14 puntos. Beneficiado por el lock-in positivo de AWS: si ya estás allí, y quieres serverless con rendimiento decente y costes predecibles, Dynamo es un candidato serio. El patrón es el mismo: NoSQL para lo que NoSQL hace bien.
El nicho útil: Neo4j y los grafos
Neo4j entra en el Top-20 y sube más de 10 puntos. No porque todo el mundo esté modelando grafos, sino porque hay más fraude que nunca, más recomendaciones que nunca y más necesidad de trazabilidad que nunca.
Eso sí, sigue siendo un nicho. No vas a modelar una tienda online en grafo. Pero cuando lo necesitas, no hay sustituto.
Embebido: SQLite
SQLite sube 7 puntos y se mantiene como el motor más invisible y más desplegado del planeta. Está en móviles, navegadores, apps de escritorio… y nadie habla de él. Pero sin él, medio mundo digital colapsaría.
Esto es importante, SQLite es, con diferencia, la base de datos más desplegada del planeta: está en cada móvil Android o iOS, en navegadores, en aplicaciones de escritorio, en coches, en televisores… Es omnipresente y nadie la instala conscientemente. Justo por eso, no aparece en tantos foros, ofertas de trabajo o notas de prensa, y DB-Engines se alimenta de esas señales.
Como SQLite es un motor embebido que funciona en segundo plano y rara vez se administra “como producto”, no genera ruido mediático. Nadie abre un hilo en Stack Overflow con “ayuda, tengo problemas de clúster con SQLite” porque… no hay clúster. Tampoco ves ofertas de trabajo “Buscamos experto senior en SQLite”. Y eso, para DB-Engines, cuenta como “menos popularidad”.
El gran olvidado: Access
Microsoft Access cae (otra vez), pero sigue en el ranking. Y con razón. No diremos nombres, pero todos conocemos una pyme, una universidad o incluso una gran empresa que tiene un .mdb dando soporte a algo que “no se puede tocar hasta que Juan vuelva de vacaciones”. Lo gracioso (o lo trágico, según el día) es que ese Access suele seguir funcionando. Sin actualizaciones automáticas, sin tests, sin pipeline CI/CD… pero ahí está, cumpliendo su papel.
Access tiene una base fiel que lo sigue defendiendo con uñas, dientes y formularios incrustados. Y aunque en muchos casos sería razonable migrar a soluciones más modernas, también hay que reconocer que para cierto tipo de aplicaciones de backoffice, gestión interna o pequeños procesos departamentales, Access fue (y sigue siendo) una navaja suiza. Desactualizada, sí. Limitada, también. Pero a veces suficiente, y eso es más de lo que pueden decir muchos proyectos en la nube con dashboards que fallan cada martes.
Así que sí, sigue cayendo en popularidad… pero no desaparecerá del todo. Y mientras existan ficheros compartidos en una unidad de red llamada \\SERVIDOR-CONTABILIDAD, Access seguirá teniendo un rincón en el ecosistema.
Elasticsearch y Splunk: ¿fin del hype?
Elasticsearch pierde 15 puntos, Splunk 26. El mensaje es claro: la observabilidad está cambiando de cara. Los costes y la complejidad de estas plataformas están siendo desafiados por soluciones cloud nativas, integración con Prometheus, OpenTelemetry, e incluso por modelos de pago más flexibles. Nadie discute su valor técnico, pero ya no son los únicos en la mesa.
¿Qué se puede inferir del informe?
Lo más claro es lo que ya hemos comentado, lo relacional sigue siendo el corazón de la arquitectura de datos. Incluso en entornos modernos, la consistencia, las transacciones y el SQL siguen siendo el pegamento. NoSQL no ha sustituido a nada, simplemente se ha acoplado a lo que le toca.
El desarrollo cloud y la analítica moderna están redefiniendo qué es “popular”, pero los fundamentos no han cambiado. Quien sepa SQL, entienda particiones, y sepa modelar bien, sigue siendo indispensable.
PostgreSQL es la opción sensata si no quieres venderle tu alma a ningún proveedor, y Snowflake, BigQuery o Databricks son opciones serias para analítica avanzada si el Excel se te queda corto (o si necesitas procesar terabytes en vez de fórmulas con SI(CONJUNTO)).
¿Y en España?
No hay datos locales de DB‑Engines, pero los que trabajamos aquí lo sabemos: mucho Oracle y SQL Server en el tejido empresarial clásico, bastante MySQL en web, y cada vez más PostgreSQL en nuevas implantaciones. Y sí, cuando hay presupuesto, Snowflake o BigQuery asoman la cabeza en los RFP de analítica.
Las startups se mueven con PostgreSQL + Redis + alguna solución cloud para IA o analítica. Las grandes, con Oracle + DWH en cloud y Access escondido en una carpeta llamada “no tocar”.
Conclusión
Puedes mirar el ranking todas las semanas, pero si no entiendes qué papel juega cada tecnología en tu stack, no sirve de nada. Las modas cambian, pero las bases siguen siendo las mismas: consistencia, rendimiento, escalabilidad y coste. Y sí, elegir mal la base de datos sigue siendo una forma rápida de complicarte la vida durante años.
Así que, como siempre, elige con criterio técnico, no con pulsaciones de Twitter. Y si estás pensando en migrar algo solo porque “PostgreSQL lo está petando”, más vale que tengas buenos motivos, y no solo un gráfico bonito. Porque lo único más peligroso que una mala arquitectura… es una moda mal entendida.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!