Cuando desarrollamos aplicaciones que interactúan con bases de datos SQL Server o Azure SQL, una de las decisiones más relevantes es si utilizar un Object-Relational Mapper (ORM) o escribir directamente consultas SQL optimizadas. Desde el punto de vista de un DBA, esta elección tiene un impacto significativo en el rendimiento, la seguridad y la mantenibilidad del sistema. En este artículo, analizaremos las ventajas y riesgos de los ORM para que los desarrolladores puedan tomar decisiones informadas.
¿Qué es un ORM y cuáles son los más usados con SQL Server?
Un Object-Relational Mapper (ORM) es una herramienta que permite a los desarrolladores interactuar con bases de datos SQL Server o Azure SQL a través de objetos y clases en su lenguaje de programación, evitando la necesidad de escribir consultas SQL manualmente. Esto facilita el desarrollo y mejora la productividad, pero también introduce riesgos en términos de rendimiento y optimización.
Entre los ORM más utilizados con SQL Server destacan Entity Framework, que ofrece una integración profunda con .NET y permite trabajar con consultas LINQ, Dapper, un micro ORM más ligero y eficiente que requiere consultas SQL explícitas, y NHibernate, una opción más flexible con características avanzadas de optimización.
Si bien los ORM pueden acelerar el desarrollo, es fundamental conocer sus ventajas y riesgos para evitar problemas de rendimiento y escalabilidad en entornos de producción. A continuación, analizaremos estos aspectos desde la perspectiva de un DBA.
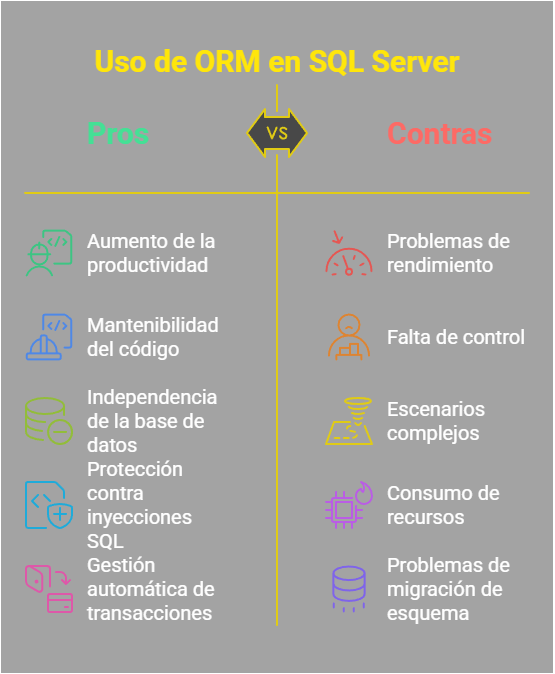
Ventajas de usar un ORM en SQL Server o Azure SQL
Los ORM se están imponiendo en el mercado por sus ventajas a la hora de trabajar con base de datos. Vamos a ver cuales son estas principales ventajas.
Aumento de la productividad
Uno de los principales atractivos de los ORM es su capacidad para abstraer la base de datos mediante modelos de objetos en el lenguaje de programación utilizado (C#, Python, Java, etc.). Esto permite a los desarrolladores escribir código sin preocuparse por los detalles específicos del SQL, lo que acelera el desarrollo.
Por ejemplo, en Entity Framework, la creación de un nuevo registro puede ser tan sencilla como:
var usuario = new Usuario { Nombre = "Juan", Email = "juan@example.com" };
context.Usuarios.Add(usuario);
context.SaveChanges();Esto elimina la necesidad de escribir INSERT INTO manualmente, reduciendo el código repetitivo y mejorando la legibilidad.
Mantenimiento y escalabilidad del código
Los ORM promueven una arquitectura más limpia y estructurada. Dado que el acceso a datos se encapsula dentro de modelos y repositorios, es más fácil modificar o extender la funcionalidad sin afectar directamente la base de datos. Además, el uso de ORM facilita el mantenimiento en equipos grandes, donde distintos desarrolladores trabajan sobre la misma base de código.
Independencia del motor de Base de Datos
Muchos ORM permiten cambiar de motor de base de datos sin necesidad de modificar grandes secciones del código. Esto puede ser útil en escenarios donde la aplicación necesita soportar tanto SQL Server como PostgreSQL, o cuando una empresa decide migrar de on-premises a Azure SQL.
Protección contra inyecciones SQL (SQLi)
Los ORM utilizan parámetros en sus consultas, lo que minimiza el riesgo de ataques de inyección SQL. Por ejemplo:
var usuario = context.Usuarios.FirstOrDefault(u => u.Email == email);Aquí, Entity Framework convierte internamente la consulta en una con parámetros, evitando el uso de concatenación de strings peligrosa como:
SELECT * FROM Usuarios WHERE Email = 'email@inseguro.com';Este beneficio mejora la seguridad de la aplicación sin requerir validaciones manuales en cada consulta.
Gestión automática de transacciones
Los ORM suelen manejar transacciones de forma automática, asegurando la integridad de los datos sin necesidad de que los desarrolladores escriban explícitamente BEGIN TRANSACTION, COMMIT o ROLLBACK. Esto reduce errores en operaciones que afectan múltiples tablas.
Riesgos de usar un ORM en SQL Server o Azure SQL
Todas estas ventajas tienen una serie de contraprestaciones, unos problemas o, más bien, riesgos que tenemos que tratar adecuadamente o tendremos problemas más pronto que tarde. Voy a tratar de resumir ahora estos principales problemas para que vosotros no tengáis estos problemas.
Problemas de rendimiento (Consultas ineficientes)
Uno de los mayores problemas de los ORM es la generación de consultas ineficientes. A menudo, una consulta simple en SQL se convierte en múltiples llamadas a la base de datos debido a malas prácticas como el «N+1 problem«:
var usuarios = context.Usuarios.ToList();
foreach (var usuario in usuarios)
{
var pedidos = usuario.Pedidos.ToList();
}Aquí, en lugar de ejecutar una sola consulta JOIN, el ORM ejecutará una consulta por cada usuario, afectando gravemente el rendimiento. En bases de datos grandes, esto puede generar miles de consultas innecesarias.
Solución: Es recomendable utilizar carga diferida (lazy loading) de manera controlada o Include() para optimizar la carga de datos:
var usuarios = context.Usuarios.Include(u => u.Pedidos).ToList();Falta de control sobre las consultas generadas
Los ORM generan consultas automáticamente, lo que a veces resulta en consultas innecesariamente complejas o con condiciones redundantes. Aunque los ORM permiten escribir consultas en SQL nativo (context.Database.ExecuteSqlRaw() en Entity Framework), muchos desarrolladores confían demasiado en la capa de abstracción y no analizan las consultas generadas.
Para mitigar este problema, se recomienda habilitar la inspección de consultas y monitorizar el rendimiento mediante herramientas como SQL Server Profiler u otras similares.
Entity Framework Logging (context.Database.Log)Dificultades en escenarios complejos
Cuando una aplicación requiere procedimientos almacenados (Stored Procedures), funciones (Functions) o consultas altamente optimizadas, los ORM pueden ser un obstáculo. Aunque algunos ORM permiten ejecutar procedimientos almacenados, su integración no siempre es natural.
En SQL Server, algunas operaciones críticas como manejo de particiones, índices columnstore o consultas optimizadas para OLAP son difíciles de realizar correctamente con un ORM, lo que puede afectar el rendimiento en cargas de trabajo intensivas.
Consumo de recursos y sobrecarga en la Base de Datos
Los ORM suelen manejar el tracking de cambios en los objetos, lo que genera una sobrecarga de memoria en aplicaciones con gran volumen de datos. En Entity Framework, esto se mitiga con .AsNoTracking():
var usuarios = context.Usuarios.AsNoTracking().ToList();Sin embargo, si los desarrolladores no son conscientes de esta necesidad, las aplicaciones pueden volverse más lentas a medida que el contexto de datos crece innecesariamente.
Problemas con la migración de esquema en producción
Herramientas de ORM como Entity Framework Migrations permiten gestionar cambios en el esquema de la base de datos de forma programática. Sin embargo, si no se manejan correctamente, pueden introducir cortes en producción, por ejemplo, si una tabla es renombrada o si se eliminan columnas en uso.
En bases de datos críticas, es preferible utilizar scripts de migración controlados manualmente en lugar de depender exclusivamente de herramientas automatizadas.
Un ORM mal configurado puede tratar todos los datos como texto
Un problema frecuente cuando se usa algunos ORM es la mala configuración de los tipos de datos. Si no se mapean correctamente las columnas a los tipos adecuados, el ORM puede convertir todos los datos a texto (nvarchar o varchar), lo que genera problemas de rendimiento y errores de modelado.
Por ejemplo, si un campo de fecha no se mapea correctamente:
public string FechaNacimiento { get; set; } // ERROR: debería ser DateTimeEsto puede provocar conversiones implícitas y afectar el uso de índices en SQL Server, ya que las comparaciones se vuelven menos eficientes:
SELECT * FROM Usuarios WHERE FechaNacimiento = '1985-06-15'Solución: Verificar siempre la configuración de los tipos de datos y usar HasColumnType() en Entity Framework:
modelBuilder.Entity<Usuario>()
.Property(u => u.FechaNacimiento)
.HasColumnType("datetime");No aprovechar las optimización de los Procedimientos Almacenados
Uno de los puntos más críticos es que los ORM no aprovechan las capacidades de optimización de SQL Server, como la caché de planes de ejecución. Los procedimientos almacenados permiten a SQL Server reutilizar planes de ejecución optimizados, mientras que los ORM pueden generar consultas dinámicas que no se benefician de esta reutilización.
Por otro lado, en las últimas versiones de SQL se han introducido los Joins dinámicos en los planes de ejecución de procedimiento almacenados, cosa de lo que no aprovechan las consultas generadas por el ORM. Además, un procedimiento almacenado puede incluir hints, como por ejemplo OPTION (RECOMPILE), para ajustar la optimización a cada ejecución, algo difícil de lograr con consultas generadas por ORM.
Por último, en un procedimiento almacenado, podemos definir parámetros con los tipos exactos, evitando conversiones innecesarias que afectan el rendimiento.
En conclusión ,el uso de procedimientos almacenados garantiza un mejor aprovechamiento de la infraestructura de SQL Server.
¿Cuándo usar un ORM en SQL Server o Azure SQL?
Como vemos, estas herramientas pueden ser un arma de doble filo y lo que parecía una ventaja para los desarrolladores termina siendo un problema de rendimiento y dolores de cabeza continuos para el equipo. Tenemos que tener muy claro en qué casos usarlo y en qué casos no. Esto sería un pequeño resumen, a modo general, aunque siempre hay excepciones.
Casos en los que un ORM es adecuado:
- Aplicaciones pequeñas o medianas donde la velocidad de desarrollo es clave.
- Proyectos con equipos de desarrollo que no tienen conocimientos avanzados en SQL.
- Aplicaciones que no requieren consultas SQL altamente optimizadas.
- Proyectos en los que la independencia del motor de base de datos es un factor importante.
Casos en los que un ORM NO es la mejor opción:
- Aplicaciones con alto tráfico y consultas complejas donde el rendimiento es crítico.
- Sistemas que dependen de procedimientos almacenados, índices columnstore o consultas OLAP.
- Aplicaciones con grandes volúmenes de datos que requieren optimización a nivel de base de datos.
- Proyectos donde la sobrecarga del ORM afecta significativamente los tiempos de respuesta.
Conclusión
Los ORM son herramientas útiles que pueden mejorar la productividad y la seguridad en el desarrollo de aplicaciones. Sin embargo, como administradores de bases de datos, debemos asegurarnos de que su uso no impacte negativamente el rendimiento o la escalabilidad del sistema.
En conclusión, los ORM no son una solución mágica. Usarlos correctamente requiere comprender tanto sus ventajas como sus limitaciones, asegurándonos siempre de que no comprometan la eficiencia del sistema. Como DBA, nuestra labor es garantizar que las aplicaciones sean escalables y seguras, y para ello, una estrategia equilibrada entre ORM y SQL optimizado es la mejor opción.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
