¿Sabes qué son y cuándo usar cada tipo de JOIN? Esta es la base de cualquier consulta SQL que empieza a volverse compleja. Seguro que a ninguno os sorprende que os diga que, hoy en día, el conocimiento de SQL es una de las habilidades más demandadas en el mercado laboral. Cualquiera que trabaje con datos, a casi cualquier nivel, va a necesitar en algún momento consultar información y en este aspecto el lenguaje SQL es clave. No solo lo usan todas las bases de datos relacionales, sino que hasta las bases de datos NoSQL o descentralizadas han terminado admitiendo este lenguaje de consultas. O, al menos, un lenguaje “SQL Like” para la consulta de sus datos no estructurados o semiestructurados.
Por todo esto, se hace muy importante para los profesionales de datos tener la capacidad de escribir consultas complejas con cláusulas JOIN que nos permitan unir la información de varias tablas.
Joins en SQL
Los joins en SQL son la base de cualquier consulta compleja. Como su propio nombre indica, nos permiten combinar filas de dos o más tablas basándonos en una columna relacionada entre ellas. Suele ser una Foreing Key pero realmente no es necesario que exista esa restricción entre las tablas para hacer la consulta con un join.
Tipos de Join
Como hemos podido ver, los joins son una de las cláusulas más importantes que podemos usar en nuestra consulta de SQL. Además existen varios tipos de joins y cada uno de ellos tiene una función y un uso específico.
INNER JOIN
El INNER JOIN es la operación más básica. Algunos SGBD como SQL Server o Azure SQL admiten la sintaxis JOIN a secas sin especificar el INNER. Con este join seleccionaremos registros que tienen valores coincidentes en ambas tablas. Es el más común de los joins y se utiliza con frecuencia para combinar filas de dos o más tablas.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
LEFT (OUTER) JOIN
El LEFT JOIN nos devuelve todos los registros de la tabla izquierda y los registros coincidentes de la tabla derecha. Si no hay una coincidencia, el resultado es NULL en el lado derecho.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
LEFT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
RIGHT (OUTER) JOIN
El RIGHT JOIN nos va a devolver todos los registros de la tabla derecha y los registros coincidentes de la tabla izquierda. Si no hay una coincidencia, el resultado es NULL en el lado izquierdo.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
FULL (OUTER) JOIN
El FULL JOIN devuelve todos los registros cuando hay una coincidencia en cualquiera de las tablas izquierda o derecha. Si no hay una coincidencia, el resultado es NULL en ambos lados.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
FULL JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
Usos avanzados de JOINS
Además de los usos básicos de JOIN que ya hemos visto, podemos combinarlos con el uso del filtro IS NULL para obtener otro tipo de datos. Por ejemplo combinando LEFT JOIN
con un filtro ISNULL cuando la clave de la tabla derecha es nulo podremos sacar solo los registros de una tabla que no tienen relaciones con otra. Igual pero al revés podemos hacerlo con RIGHT JOIN. Combinando un FULL JOIN con un filtro que nos garantice que las claves por las que enlazamos son nulas podremos sacar los registros de ambas tablas que no tienen relación con la otra.
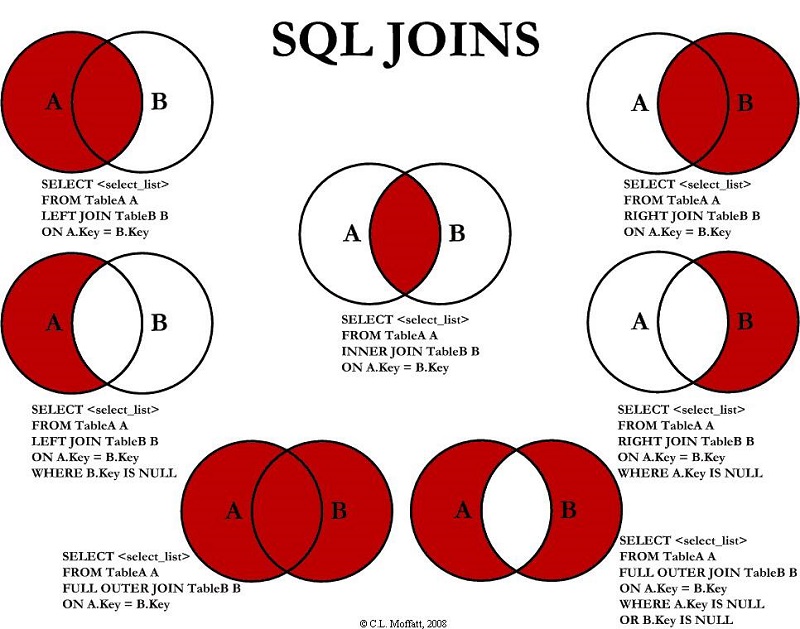
Se que todo esto os puede parecer un poco lioso así contado pero seguro que con esta infografía lo vais a ver más claro. Ya sabéis, una imagen vale más que mil palabras (600 a estas alturas del artículo 🤣 ).
Escrituras con JOINS
Esto no sería la guía definitiva de los joins si no mencionamos también la sintaxis de las operaciones de escritura. Obviamente no tiene sentido unir varias tablas en una consulta de inserción ya que los insert son en una sola tabla pero sí que podremos querer actualizar o borrar datos de una tabla cruzando con otras para asignar un valor presente en otra tabla o para alguna validación extra.
Update con JOIN
Es un escenario bastante común, en ocasiones queremos actualizar un valor de una tabla tal como lo tenemos en otra. Para eso podemos hacer un update con join tal como vemos aquí.
UPDATE O SET CustomerID = OB.CustomerID
FROM Orders O
INNER JOIN Orders_Backup OB
ON O.OrderID = OB.OrderID
Como veis en este caso, tenemos una tabla de backup y queremos restaurar el valor de CustomerID desde el backup. Este es uno de los usos más comunes de este tipo de sintaxis.
Delete con JOIN
Existen varios escenarios en los que vamos a necesitar un join en una clausula delete. El más sencillo será borrar los registros de una tabla que tengan coincidencia en otra tabla. Sin embargo también podemos, por ejemplo, querer borrar solo los registros que no existen en la segunda tabla. Vamos a ver estos y otro ejemplo extra
Ejemplo sencillo de borrado de registros de una tabla origen que tengan coincidencia en una tabla filtro. En este caso vamos a borrar todos los pedidos de clientes con una nacionalidad en concreto:
DELETE origen
FROM Orders origen
INNER JOIN Customers filtro
ON origen.CustomerID = filtro.CustomerID
WHERE filtro.nacionalidad = ‘Wakanda’
Otro ejemplo muy común como ya hemos visto es el de borrar datos de una tabla que no tengan relaciones con otras. Por ejemplo, queremos borrar todas las líneas de una factura que no tengan cabecera.
DELETE lineas
FROM LineasFactura lineas
LEFT JOIN CabecerasFactura facturas
ON lineas.factID = facturas.factID
WHERE facturas.factID IS NULL
Por último, para cerrar ya esta guía vamos a ver un ejemplo especial que no todos los sistemas de bases de datos admiten que es el uso de join para borrados en cascada. Esta sintaxis, no la vais a poder usar en SQL Server o Azure SQL pero si, por ejemplo, en MySQL.
DELETE Orders, Customers
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID = Customers.CustomerID
WHERE Customers.nacionalidad = ‘Wakanda’
Conclusión
Los joins son una herramienta esencial en SQL que nos permite combinar datos de diferentes tablas de manera eficiente. Aunque puede parecer complicado al principio, con práctica y experiencia, se convertirán en una parte integral de tus consultas SQL. No en vano son imprescindibles para todo DBA o trabajador de datos. Recuerda, la mejor manera de aprender es practicando, usa tus datos de demo para hacer pruebas e interiorizar los conceptos. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!