Durante los anteriores post hemos comentado las recomendaciones de instalación de SQL para SharePoint y sus configuraciones recomendadas, como ha tenido muy buena acogida vamos a continuar con esta línea esta vez hablando de las buenas prácticas de SQL Server para BizTalk.
Existen varios factores que tenemos que tener en cuenta en nuestro SQL Server para BizTalk. En este artículo vamos a intentar ver los más importantes no solo para configurar nuestro SQL sino para mantenerlo y solucionar los problemas que nos puedan surgir.
¿Qué es BizTalk?
Empecemos por el principio, BizTalk es un producto de Microsoft que facilita la comunicación entre sistemas heterogéneos, tanto dentro como fuera de la organización. BizTalk permite crear flujos de trabajo (orquestaciones) que definen la lógica y las reglas de negocio para procesar los mensajes que se intercambian entre los sistemas. Además, también ofrece herramientas para transformar, enrutar, monitorizar y auditar los mensajes, así como para gestionar las excepciones y errores que puedan ocurrir.
BizTalk se basa en una arquitectura distribuida que consta de varios componentes, entre los que se encuentra SQL Server. SQL Server es el encargado de almacenar la información relativa a las configuraciones, las instancias, las suscripciones, el seguimiento y el archivado de los mensajes. Por tanto, el rendimiento y la disponibilidad de SQL Server son fundamentales para el correcto funcionamiento de BizTalk.
Bases de datos de BizTalk
BizTalk usa varias bases de datos y es importante que las conozcamos pues no todas van a requerir las mismas medidas por nuestra parte. Las principales bases de datos que debemos conocer son: BizTalkMgmtDb (base de datos de administración), BizTalkMsgBoxDb (base de datos del buzón), BizTalkDTADb (base de datos del seguimiento), SSO (base de datos del servicio de configuración) y BAM (base de datos del análisis de negocio).
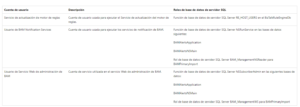
Usuarios de BizTalk
Además de las bases de datos BizTalk creará una serie de inicios de sesión y roles en nuestro SQL Server. Podemos verlo en la siguiente tabla que proporciona Microsoft (haz click sobre la imagen para ampliar).
Configuraciones de SQL Server ideales para BizTalk
Con estos conocimientos previos en mente ya podemos entrar en materia sobre la configuración de SQL Server específica para BizTalk. Vais a ver que algunas son similares a las que vimos para SharePoint.
Configuraciones de SQL Server
Es importante que establezcamos el nivel de paralelismo a 1, ya que BizTalk genera muchas (muchísimas) consultas aunque muy ligeras. Con esto nos aseguraremos de poder dar salida a las máximas consultas posibles de manera simultánea.
En cuanto al Fill Factor, la documentación oficial no hace mención a un valor concreto sin embargo sí que nos habla de que la mayoría de los índices son clustered y con identificadores únicos basados en GUID por lo que no es recomendable poner un Fill Factor del 100%. Mi consejo es dejar el parámetro por defecto ya que no se especifica otra cosa. Más adelante volveremos al tema de los índices porque va a ser un dolor de cabeza.
Configuración de TempDB
Aunque este es un consejo general para todos los SQL Server, en el caso de BizTalk tiene mucha importancia porque ejecuta cantidades impensables de transacciones. Dividiremos nuestra base de datos en tantos ficheros como núcleos tenga nuestra CPU (hasta un máximo de 8) a fin de que varios hilos puedan acceder al recurso sin bloqueos de páginas. Todos los ficheros tendrán el mismo tamaño inicial y si usamos un SQL inferior a 2016 habilitaremos la traza -T1117 en el arranque para que todos los ficheros crezcan simultáneamente. Sin embargo, debemos anticipar el tamaño de la TempDB y dimensionarla previamente para evitar el extra de tiempo del crecimiento de los archivos.
Tamaños de las bases de datos de BizTalk
Al igual que con la TempDB es importante que establezcamos un tamaño inicial y un crecimiento a los ficheros de las bases de datos de la aplicación para optimizar el rendimiento. En entornos pequeños y medianos podemos usar el siguiente script:
EXEC dbo.sp_helpdb BizTalkMsgBoxDb ALTER DATABASE BizTalkMsgBoxDb MODIFY FILE (NAME = BizTalkMsgBoxDb , FILENAME = '\BizTalkMsgBoxDb.mdf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_2 , FILENAME = '\BizTalkMsgBoxDb_2.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_3 , FILENAME = '\BizTalkMsgBoxDb_3.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_4 , FILENAME = '\BizTalkMsgBoxDb_4.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_5 , FILENAME = '\BizTalkMsgBoxDb_5.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_6 , FILENAME = '\BizTalkMsgBoxDb_6.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_7 , FILENAME = '\BizTalkMsgBoxDb_7.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) ALTER DATABASE BizTalkMsgBoxDb ADD FILE (NAME = BizTalkMsgBoxDb_8 , FILENAME = '\BizTalkMsgBoxDb_8.ndf' , SIZE = 2GB , FILEGROWTH = 100MB) GO ALTER DATABASE BizTalkMsgBoxDb MODIFY FILE (NAME = BizTalkMsgBoxDb_log , FILENAME = '\BizTalkMsgBoxDb_log.LDF', SIZE = 20GB , FILEGROWTH = 100MB) GO
Utilizaremos estos parámetros para entornos standalone y pequeños. En un entorno BizTalk de alto rendimiento, deberemos considerar dividir la BizTalkMsgBoxDb en 8 archivos de datos, cada uno con un tamaño de archivo de 2 GB con 100 MB de crecimiento y un archivo de registro de 20 GB con 100 MB de crecimiento. Debido a que las bases de datos BizTalk MessageBox son las más activas, colocaremos los archivos de datos y los archivos de log de transacciones en unidades dedicadas para reducir la probabilidad de problemas de E/S de disco, como vamos a ver ahora.
Configuración de discos duros de SQL Server para BizTalk
Entramos, sin duda, en el apartado más importante para el futuro rendimiento de nuestras aplicaciones BizTalk, de esto va a depender que nuestra aplicación siga funcionando como al principio cuando empiece a tener un tamaño considerable. Por eso es el apartado en el que más nos vamos a extender hoy.
Por defecto, BizTalk coloca la base de datos MessageBox en un único archivo en el grupo de archivos predeterminado. Y por defecto, los datos y logs de transacciones para todas las bases de datos también se colocan en la misma unidad y ruta. Esto se hace para poder funcionar en sistemas con un único disco. Sin embargo, esta configuración de un único archivo, grupo de archivos y disco no es óptima en un entorno de producción. Para un rendimiento óptimo, los archivos de datos y los archivos de log deben colocarse en discos separados.
Otra cosa que debemos tener en cuenta, especialmente para entornos de alto volumen, y de nuevo, porque las bases de datos MessageBox y Tracking son las más activas, es colocar los archivos de datos y los logs de transacciones de estas dos bases de datos en unidades dedicadas para reducir la probabilidad de problemas de E/S de disco.
Por tanto para un rendimiento óptimo nuestro SQL Server deberá tener por lo menos 7 discos duros de datos:
- Archivo(s) de datos MessageBox
- Archivo(s) de log de transacciones de MessageBox
- Archivo(s) de datos de BizTalk Tracking (DTA)
- Archivo(s) de log de transacciones de BizTalk Tracking (DTA)
- Otros archivos de datos de bases de datos BizTalk
- Otros archivos de registro de transacciones de bases de datos BizTalk
- TEMPDB
Buscando la perfección en el reparto de discos
Esta técnica descrita anteriormente será familiar para cualquiera que haya creado una instalación grande y multiservidor de BizTalk Server. Además, es preferible que la base de datos de seguimiento (DTA) se sitúe en un servidor separado (o clúster en un entorno de alta disponibilidad) del buzón de mensajes.
Otra de las mejores optimizaciones de rendimiento que podemos hacer es repartir las tablas de las bases de datos de BizTalk entre varios grupos de archivos. Cada grupo de archivos añade un hilo de E/S que, junto con el archivo de datos en un LUN separado, mejorará enormemente el rendimiento (con ganancias del 100-1000%, dependiendo de las características de carga del sistema). No sólo moveremos los datos de la tabla a grupos de archivos separados, sino también los datos LOB y los índices no agrupados. Esto maximiza el paralelismo entre consultas y otras operaciones de base de datos. Haremos esto si nuestra base de datos MessageBox es cercana o mayor a 15 GB.
En entornos pequeños o medianos sin una gran cantidad de mensajes, no es necesario tener tanta separación en discos. Sin embargo, es muy recomendable que al menos tengamos unidades dedicadas para los archivos de datos y de logs (para permitir que la actividad de E/S se produzca al mismo tiempo para los archivos de datos y de log) y una unidad dedicada para TEMPDB.
Índices y estadísticas en las bases de datos de BizTalk
BizTalk hace su propia gestión de los índices y estadísticas de las bases de datos por lo que tendremos que asegurarnos de que todas las bases de datos de la aplicación tengan tanto la creación como la actualización automática de estadísticas deshabilitadas.
El tema de los índices es más delicado, ya que un mal mantenimiento nos llevará a un escenario insostenible de continuos bloqueos que harán perder la paciencia a los usuarios. Para complicarnos aún más las cosas BizTalk no admite un mantenimiento estándar de índices, es decir no podremos programar nuestros habituales planes de mantenimiento nativos o de Ola Hallengren, o bloquearemos por completo la aplicación.
El único método admitido para mantenimiento de índices en la base de datos BizTalkMsgBoxDb es ejecutar el procedimiento almacenado bts_RebuildIndexes. En BizTalk Server 2006 y versiones posteriores, tenemos también el procedimiento almacenado dtasp_RebuildIndexes para en la base de datos BizTalkDTADb. Por si te parece poco, estos procedimientos solo se pueden ejecutar cuando la aplicación no tiene carga, es decir cuando no está procesando mensajes por lo que es vital acordar con el administrador de la aplicación una ventana de mantenimiento para ejecutarlo. Para poder ejecutar el mantenimiento de índices todas las instancias de BizTalk y el Agente de SQL deben estar detenidos.
Niveles de aislamiento
El valor predeterminado de Transaction Isolation Level es Serializable para el adaptador de BizTalk WCF-SQL tanto para las operaciones entrantes y salientes. Esto provoca gran cantidad de bloqueos, que aunque no deberían ser un problema en entornos pequeños y con poca carga de trabajo puede que nos de problemas en cuanto el volumen de peticiones se incremente. Por suerte el administrador de BizTalk podrá cambiar esta configuración. Revisa nuestro articulo de niveles de aislamiento para entender mejor este tema.
Agente de SQL Server
Por último, pero no menos importante, como se suele decir, tenemos que prestar atención a los jobs de SQL Server que genera BizTalk. Dependiendo de la versión de BizTalk se generarán 12 o 13 jobs, la mayoría realizan procesos internos de la aplicación que, como DBAs, no hace falta conocer. Sin embargo es muy importante que si atendamos a dos de ellos que se llaman «Backup BizTalk Server» y «DTA Purge and Archive». Estos dos jobs son críticos y por defecto nos vienen programados por lo que tendremos que hacerlo nosotros. El primero de ellos, como habréis adivinado por el nombre, se encarga de las copias de seguridad de las bases de datos siguiendo las buenas prácticas de Microsoft para ello. El segundo, es el encargado de purgar y archivar la información de la base de datos de seguimiento y, eso es lo principal para no tener degradaciones del rendimiento.
Conclusión
En este artículo he compartido con vosotros algunas buenas prácticas de configuración de SQL Server para BizTalk, que os pueden ayudar a mejorar el rendimiento, la escalabilidad y la seguridad de vuestra plataforma de integración. Espero que os hayan resultado útiles y que las pongáis en práctica. Si tenéis alguna duda o comentario, podéis dejarlo abajo, en mi Twitter o por mail.
PD: Si esto os ha parecido poco podéis ampliar toda esta información el la guía de documentación de Microsoft aquí.