Hace unos días hablábamos sobre la diferencia entre los inicios de sesión y los usuarios en SQL Server y Azure SQL y pudimos ver cómo teníamos a nuestro alcance varios métodos de autenticación para iniciar sesión. Como vimos los logins podían ser usuarios nativos de SQL Server o heredados del dominio de Windows o de Azure (lo que se conoce como Entra ID y antes como Azure Active Directory). Esta autenticación es un aspecto crítico para los sistemas de datos, la seguridad de nuestros datos depende en gran medida de cómo controlamos el acceso a ellos.
En este artículo, vamos a explorar en profundidad los distintos modos de autenticación disponibles en SQL Server y Azure SQL. Por un lado, tendremos los métodos tradicionales como la autenticación de SQL Server y Windows, y por otro lado, la integración con Azure Entra ID (anteriormente conocido como Azure Active Directory). También quiero entrar en los protocolos subyacentes, Kerberos y NTLM, sobre los que se basan estos métodos de autenticación.
Modos de Autenticación en SQL Server y Azure SQL
SQL Server y Azure SQL ofrecen varias opciones para autenticar usuarios. Cada una de estas opciones está diseñada para escenarios específicos, y la elección de un método sobre otro puede tener implicaciones significativas en la seguridad y la facilidad de administración.
Autenticación de SQL Server
La autenticación de SQL Server es probablemente el método más tradicional. Se basa en un sistema interno de gestión de inicios de sesión y contraseñas dentro de SQL Server. Este método no depende del sistema operativo ni de ningún servicio externo para validar las credenciales, lo que significa que los usuarios y las contraseñas se gestionan directamente en el propio motor de bases de datos. Este tipo de autenticación es ideal en escenarios donde necesitamos un control granular sobre el acceso de usuarios que no están en nuestro dominio de Windows o cuando estamos trabajando en entornos mixtos.
Autenticación de Windows
La autenticación de Windows permite a los usuarios autenticarse usando sus credenciales de dominio de Windows. Este método es mi preferido en entornos donde se utiliza Active Directory para gestionar usuarios y grupos. La principal ventaja de la autenticación de Windows es que podemos integrar sin problemas SQL Server en un entorno de seguridad ya establecido. Además nos permite hacer uso de los grupos de Directorio Activo, lo que nos puede simplificar enormemente la tarea y aumentar la seguridad. Por último, otra ventaja es que no solo simplifica la gestión de credenciales, sino que también permite aprovechar protocolos de seguridad avanzados como Kerberos, lo que añade una capa adicional de protección como veremos más adelante.
Autenticación con Azure Entra ID
Con la aparición de servicios en la nube, la autenticación a través de Azure Entra ID se ha convertido en una opción cada vez más importante, especialmente para entornos de Azure SQL. Este método permite a los usuarios autenticarse mediante sus credenciales de Azure Entra ID, lo que facilita una integración más fluida con otros servicios de Azure. Además, permite implementar las características de seguridad avanzadas de Azure como la autenticación Multifactor (MFA) y las políticas de acceso condicional, que no son posibles con los métodos tradicionales de autenticación.
Protocolos de Autenticación: Kerberos y NTLM
Al hablar de autenticación en entornos Windows, es fundamental entender los protocolos que operan en segundo plano. Kerberos y NTLM son los dos principales protocolos de autenticación utilizados, cada uno con características y aplicaciones distintas. A pesar de que ambos sirven para el mismo propósito, sus diferencias son significativas, especialmente en términos de seguridad y rendimiento. Para tomar decisiones informadas sobre cuál utilizar, es esencial comprender cómo funcionan y en qué se distinguen.
NTLM
NTLM (NT Lan Manager) es un protocolo de autenticación desarrollado por Microsoft que ha estado en uso desde la era de Windows NT. A pesar de su antigüedad y las limitaciones de seguridad que presenta, NTLM sigue siendo utilizado en escenarios donde Kerberos no está disponible o no puede ser implementado, como en redes que no están unidas a un dominio.
El proceso de autenticación con NTLM es relativamente sencillo pero menos seguro que Kerberos. NTLM se basa en un desafío-respuesta (challenge-response), donde el cliente primero establece una conexión con el servidor y envía el nombre de usuario. El servidor genera un valor de desafío (un número aleatorio) que se envía al cliente. El cliente, a su vez, cifra este desafío utilizando un hash de la contraseña del usuario y lo envía de vuelta al servidor. El servidor compara este resultado con lo que esperaba y, si coinciden, se concede el acceso.
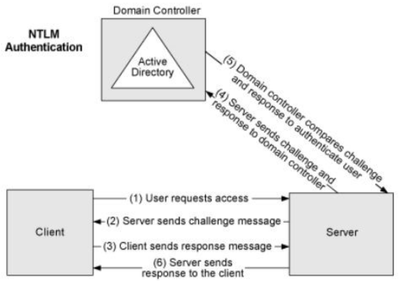
Una de las principales limitaciones de NTLM es la falta de autenticación mutua. Es decir, mientras que el servidor autentica al cliente, el cliente no autentica al servidor, lo que deja abierta la posibilidad de ataques como el «man-in-the-middle». Además, NTLM es vulnerable al ataque de «pass-the-hash», donde un atacante puede reutilizar el hash de la contraseña para acceder a recursos sin conocer la contraseña original.
Autenticación NTLM en SQL Server
En SQL Server, NTLM se utiliza principalmente cuando Kerberos no está configurado correctamente o cuando la conexión se realiza en un entorno de trabajo que no soporta Kerberos, como un grupo de trabajo (WORKGROUP) en lugar de un dominio. También, cuando accedamos desde el propio servidor local y no por la red, SIEMPRE se va a usar NTLM. Por último, es común ver NTLM en escenarios legacy, donde las aplicaciones antiguas no son compatibles con Kerberos.
Kerberos
Kerberos es un protocolo de autenticación mucho más avanzado que NTLM, introducido en Windows 2000. Basado en un sistema de «tickets», Kerberos no solo ofrece mayor seguridad, sino también un rendimiento mejorado en comparación con NTLM.
Kerberos opera utilizando un tercero de confianza, conocido como el Key Distribution Center (KDC), que emite tickets de autenticación. El proceso comienza cuando un usuario solicita acceso a un servicio. El cliente primero se autentica ante el KDC, que le proporciona un Ticket Granting Ticket (TGT). Este TGT permite al usuario solicitar tickets de servicio (Service Tickets) para acceder a diferentes recursos en la red. Cada ticket de servicio se presenta al servidor para establecer la autenticación, y dado que estos tickets están cifrados, Kerberos ofrece una mayor protección contra ataques.
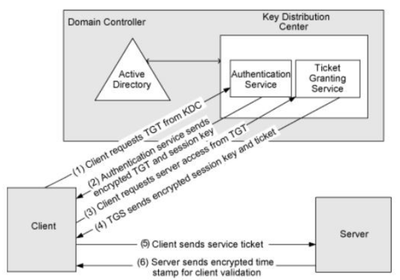
Una de las características más importantes de Kerberos es la autenticación mutua, donde tanto el cliente como el servidor validan las identidades del otro, reduciendo significativamente el riesgo de ataques de suplantación de identidad. Además, Kerberos es más eficiente en términos de red y recursos, ya que no requiere múltiples rondas de comunicación para completar la autenticación como en NTLM.
Autenticación Kerberos en SQL Server
En SQL Server, Kerberos es el protocolo que se usa preferentemente siempre y cuando esté disponible, es decir, configurado correctamente en un entorno de dominio de Active Directory. Esto no solo mejora la seguridad, sino que también nos permite el uso de características avanzadas como la delegación de autenticación, que es esencial para aplicaciones que requieren pasar las credenciales de usuario a través de múltiples capas de servicios. Sin esta delegación de autenticación, por ejemplo, es imposible “saltar” desde tu ordenador local a un servidor vinculado configurado en tu servidor SQL con el inicio de sesión de Active Directory.
Comparación: NTLM vs Kerberos
Cuando comparamos NTLM y Kerberos en entornos SQL Server, es evidente que Kerberos ofrece numerosas ventajas, tanto en términos de seguridad como de eficiencia. Sin embargo, la elección entre uno y otro puede depender de varios factores, incluidos los requisitos del entorno y la compatibilidad de las aplicaciones.
Seguridad
Kerberos es claramente superior en términos de seguridad. La autenticación mutua y el uso de tickets cifrados hacen que Kerberos sea menos susceptible a los ataques de red comunes. Por el contrario, NTLM, con su enfoque de desafío-respuesta y su vulnerabilidad al ataque pass-the-hash, es menos seguro y, por lo tanto, menos adecuado para entornos donde la seguridad es una preocupación primordial.
Rendimiento
En términos de rendimiento, Kerberos también tiene la ventaja. Al usar tickets, Kerberos reduce la carga de comunicación y mejora la eficiencia de la autenticación, especialmente en redes grandes con muchos usuarios y servicios. NTLM, aunque funcional, puede generar una carga adicional en la red debido a la necesidad de múltiples rondas de autenticación.
Compatibilidad y Configuración
A pesar de sus ventajas, Kerberos requiere una configuración más compleja y solo funciona en entornos de dominio de Active Directory. NTLM, aunque menos seguro, es más sencillo de implementar y funciona en una gama más amplia de escenarios, incluidos aquellos que no están dentro de un dominio.También deberemos tener en cuenta la complejidad extra de configuración de un entorno compatible con Kerberos donde tendremos que registrar correctamente los SPN (Service Principal Names) cuando usemos una cuenta de servicio que no sea la por defecto en una instancia por defecto y siempre que usemos instancias con nombre.
Conclusión
La elección del modo de autenticación en SQL Server o Azure SQL no es trivial y debe basarse en las necesidades específicas de seguridad y administración de cada entorno. La autenticación de SQL Server proporciona flexibilidad en escenarios específicos, mientras que la autenticación de Windows y Azure Entra ID ofrecen ventajas significativas en términos de seguridad y facilidad de gestión. Además, el entendimiento de los protocolos subyacentes como Kerberos y NTLM nos permite tomar decisiones más informadas sobre cómo proteger nuestras bases de datos contra amenazas externas. Al final, lo más importante es elegir el método de autenticación que no solo se alinee con las políticas de seguridad de la organización, sino que también se adapte a las características y necesidades del entorno en el que operamos.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
No te vayas aun. Hemos creado una página donde estamos recopilando todos estos artículos que dan respuesta a estas preguntas frecuentes de SQL Server. Pásate por aquí a echar un vistazo.

