Hoy vamos a aprovechar que recientemente se ha liberado SQL 2022 – CU13 para hablar de un proceso a simple vista trivial, pero que requiere de planificación, como es la actualización de SQL Server en los nodos de un grupo de disponibilidad Always On. No es la primera vez que comentamos en el blog la importancia de mantener nuestros SQL Server siempre actualizados para evitar vulnerabilidades graves como la que vimos aquí. En este sentido, nuestros Always On (que además suelen contener la información más crítica) son especialmente delicados. Y es que cualquiera puede ejecutar un parche de actualización y darle a siguiente hasta que termine pero, hacerlo bien, sobre todo en infraestructuras complejas como los Always On, requiere un cariño extra.
¿Qué es un Always On?
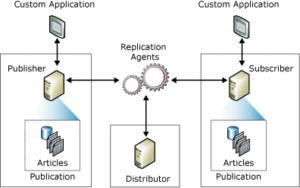
Si estás perdido en este punto no te preocupes, vamos a empezar por el principio, los grupos de disponibilidad Always On son una solución de alta disponibilidad que incorpora SQL Server en la que, por medio de un clúster de Windows (WSFC) varios servidores o nodos replican la información de nuestras bases de datos de manera síncrona o asíncrona. Esta es una breve pincelada (más bien un resumen a brocha gorda) de esta complejísima solución, si quieres saber más pásate por el artículo que le dedicamos a este tema.
El proceso de actualización
Cualquier proceso de actualización bien planeado debe constar de 3 fases principales, las pruebas previas (conocidas también como pre-checks), la actualización propiamente dicha y las pruebas finales o post-checks. Cuando hablamos de un Always On esto también va a ser así a grandes rasgos pero va a tener particularidades como pasos previos y posteriores específicos para cada uno de los nodos en función de su rol.
Pasos previos globales para la actualización
Antes de empezar a actualizar nuestros SQL Server del Always On, al igual que en cualquier proceso de actualización, deberemos revisar la documentación de la actualización en busca de errores conocidos o incompatibilidades que puedan hacer que abortemos el proceso antes de iniciarlo.
Una vez que sabemos que la actualización es teóricamente viable, vamos a verificar el entorno, en este punto verificaremos la salud de nuestro Always On (y su quórum) y comprobaremos que hay espacio suficiente en los discos para acometer con éxito el proceso de actualización.
Con todas las comprobaciones finalizadas llega el momento de preparar el entorno, idealmente estaremos en un momento sin ninguna carga de trabajo aunque, en caso de los entornos críticos que requieren de un Always On, esto suele ser inviable. Igualmente nosotros haremos una copia de seguridad de los datos y deshabilitaremos los jobs no críticos para evitar en la medida de lo posible cualquier interferencia en el proceso. En este sentido, también es recomendable deshabilitar el balanceo automático durante todo el proceso.
Actualización paso a paso
Llega el momento de empezar a actualizar, empezaremos siempre por las réplicas secundarias externas de nuestro Always On (en caso de tenerlas) o por las que tengan replicación asíncrona. Estas réplicas tienen la ventaja de no estar sincronizadas en tiempo real con la réplica principal por lo que si algo sale mal el impacto será menor. Empezaremos validando nuevamente el estado de la sincronización (idealmente verificaremos el failover) y deteniendo la replicación de datos para las bases de datos de la réplica a actualizar. Con la replicación detenida aplicaremos el parche de actualización.Una vez aplicado el parche podremos reanudar la sincronización y verificar que todo ha salido bien. Repetiremos estos pasos por todas las réplicas secundarias. Comprobaremos que todas las réplicas tienen los datos actualizados y están sincronizando al finalizar el proceso.
Con todas las réplicas secundarias actualizadas y verificado que no ha habido ningún problema llega el momento más crítico: actualizar el nodo primario. Empezaremos verificando la replicación para garantizar que no haya pérdida de datos y realizando un failover (balanceo) del rol a otro nodo. En este momento el rol principal ya será uno de los actualizados por lo que podremos proceder en este como en los anteriores. Detendremos la replicación, aplicaremos el parche, reanudaremos la sincronización y verificaremos que todo está correcto. En caso de que sea necesario realizaremos otro failover para devolver el rol al nodo principal inicial.
Pasos posteriores a la actualización
Una vez que ya tenemos todos los nodos actualizados es el momento de las comprobaciones finales. Comprobaremos la versión de SQL y que todos los nodos están sincronizando. MUY IMPORTANTE, volveremos a habilitar los jobs que hayamos deshabilitado al inicio y el balanceo automático . Con esto ya habría finalizado el proceso, recuerda que debes prestar especial atención a que las aplicaciones vuelvan a conectar correctamente y al rendimiento global tras la actualización.
¿Por qué detener la sincronización durante la actualización?
Hemos comentado que cuando aplicas un parche a una réplica, ya sea sincrónica o asincrónica, es recomendable parar la replicación de esa réplica durante el proceso de actualización. Os he dicho que antes de aplicar el proceso de actualización de cada nodo debíamos detener la sincronización para habilitarla de nuevo después, justo al terminar ese nodo y antes de empezar con los siguientes. Esto se debe a que la aplicación de un parche puede causar cambios en la base de datos que podrían interrumpir la replicación si ésta sigue activa. Al parar la replicación, te aseguras de que cualquier cambio realizado por el parche no afecte a las otras réplicas hasta que hayas verificado que el parche se ha aplicado correctamente y que la réplica actualizada está funcionando como se espera.
Esto también tiene un punto negativo, cuando detienes la replicación de una base de datos, el nodo principal sigue acumulando los cambios en sus ficheros de log de transacciones por lo que asegúrate de tener suficiente espacio y mantén vigilado en todo momento el crecimiento de los ficheros.
Conclusión
Aplicar un parche de actualización a nuestros servidores siempre es una tarea delicada pero, con una buena planificación y siguiendo los pasos correctos podremos hacerlo sin mayor problema. Recuerda que lo que hemos comentado en este post son una guia de recomendaciones para una actualización perfecta en un entorno ideal, la vida real no siempre es tan idílica y puede que tengamos que prescindir de alguno de los pasos. Sin embargo hay que conocerlos y entender bien el por qué están en esta guía para poder valorar el riesgo de no acometerlos. Y si tienes tus SQL en la nube como bases de datos o instancias administradas de Azure, enhorabuena, te has ahorrado para siempre todos estos pasos.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!