Como adelantamos ayer en la introducción sobre las distintas soluciones de alta disponibilidad que ofrece SQL Server vamos a profundizar una a una en cada una de ellas. Hoy en concreto vamos a hablar de la joya de SQL Server en este sentido, los grupos de disponibilidad Always On. Los Always On de SQL Server son una solución de alta disponibilidad y recuperación ante desastres que permite tener varias réplicas de una base de datos en diferentes servidores o ubicaciones. En este artículo, vamos a explicar cómo funcionan, qué ventajas ofrecen y cómo configurarlos paso a paso.
¿Qué son los grupos de disponibilidad Always On?
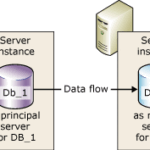
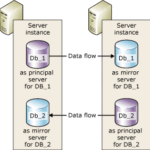
Los grupos de disponibilidad Always On son una característica introducida en SQL Server 2012 que nos permite tener hasta ocho réplicas secundarias de una base de datos primaria. Las réplicas secundarias se sincronizan automáticamente con la primaria de manera síncrona o asíncrona. Cada réplica secundaria puede tener un rol diferente, según el nivel de compromiso con la primaria y el tipo de operaciones que se permiten realizar sobre ella.
Los Always On permiten que las réplicas secundarias pueden estar en el mismo servidor o en servidores distintos, e incluso en diferentes regiones geográficas o la nube. Esto nos ofrece una gran flexibilidad y escalabilidad para adaptarlos a las necesidades de cada escenario.
Nivel de compromiso de las réplicas secundarias
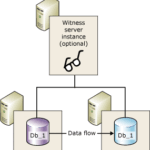
Como hemos dicho, la replicación puede ser síncrona o asíncrona, esto es un factor clave a la hora de diseñar nuestra solución de alta disponibilidad y afectará a todo lo demás.
Replicación síncrona
Las réplicas secundarias se comprometen a aplicar los cambios recibidos de la primaria antes de confirmar la transacción al cliente. Esto quiere decir que sin tener confirmación de todas las réplicas síncronas la transacción no se va a confirmar. Esto nos garantiza que las réplicas están siempre en el mismo estado, evitando la pérdida de datos, pero afectando al rendimiento de las escrituras. Las réplicas síncronas pueden tomar el rol de primaria en caso de fallo, mediante un proceso de conmutación por error automático o manual. Usaremos este tipo de réplicas como solución de alta disponibilidad siempre que la latencia de red no sea un problema. En este sentido, es recomendable usar una red dedicada para la replicación del Always On independiente a la red de servicio a los usuarios.
Replicación asíncrona
Las réplicas no se comprometen a aplicar los cambios recibidos de la primaria inmediatamente, sino que lo hacen cuando les sea posible. Esto mejora el rendimiento de las operaciones de escritura, pero puede provocar que la secundaria tenga un cierto retraso respecto a la primaria. Las réplicas asíncronas pueden tener pérdidas de datos por lo que requieren una intervención manual para forzar la conmutación por error.
Acceso a los grupos de disponibilidad Always On
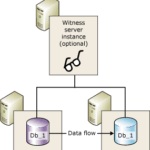
Para facilitar el acceso a las bases de datos del Always On, se utiliza el listener, que es un nombre virtual que representa al grupo de disponibilidad y que se resuelve en la dirección IP de la réplica primaria o de una réplica secundaria legible, según el criterio de enrutamiento que se defina. El listener permite a las aplicaciones conectarse al grupo de disponibilidad sin tener que conocer el nombre o la dirección IP de cada réplica. Cuando conectamos al listener este nos redirigirá siempre a la réplica primaria a no ser que le especifiquemos lo contrario mediante el parámetro ApplicationIntent=ReadOnly que nos llevará a una réplica secundaria de solo lectura.
Para configurar el listener, se debe especificar un nombre, un puerto y una dirección IP para cada subred en la que se encuentren las réplicas. Además, se debe crear un registro DNS con el nombre del listener y las direcciones IP asignadas.
Nivel de acceso a las réplicas secundarias
Hemos estado comentando que podemos acceder a las réplicas secundarias en modo de lectura. Realmente, pueden tener diferentes modos de acceso, según el tipo de consultas que se puedan ejecutar sobre ellas, vamos a verlo:
Modo solo lectura
Permite ejecutar consultas de solo lectura sobre la réplica secundaria, lo que puede servir para balancear la carga de trabajo o para realizar operaciones de mantenimiento o copia de seguridad sin afectar a la primaria. Para habilitar este modo, es necesario que la réplica secundaria esté sincronizada con la primaria y que tenga habilitada la opción READ_ONLY_ROUTING_URL, que indica la dirección a la que deben dirigirse las conexiones de solo lectura.
Modo solo intención de lectura
Permite ejecutar consultas de solo lectura sobre la réplica secundaria, pero solo si la conexión especifica explícitamente esa intención mediante el parámetro ApplicationIntent=ReadOnly. Esto puede servir para separar las conexiones que requieren acceso a la primaria de las que pueden usar una secundaria, según el criterio de la aplicación cliente. Para habilitar este modo, se requieren las mismas condiciones que para el modo solo lectura.
Modo sin acceso
No permite ejecutar ninguna consulta sobre la réplica secundaria, solo se usa para mantener una copia sincronizada con la primaria. Este modo se usa cuando no se desea dar acceso a los datos de la secundaria o cuando la réplica está en proceso de sincronización o restauración. Si contamos con una licencia de SQL Server con Software Assurance es probable que optemos por este modo de réplica secundaria ya que no requiere de licencia adicional para la instancia secundaria.
¿Qué ventajas ofrecen los grupos de disponibilidad Always On?
Los grupos de disponibilidad Always On ofrecen varias ventajas como solución de alta disponibilidad y recuperación ante desastres:
– Permiten tener varias copias de una base de datos en diferentes servidores o ubicaciones, lo que aumenta la protección ante fallos o desastres.
– Pueden conmutar por error entre réplicas de forma automática o manual, lo que reduce el tiempo de inactividad y facilita la administración.
– Nos ayudan a balancear la carga de trabajo de nuestro servidor pudiendo delegar en las réplicas secundarias las consultas de solo lectura y las copias de seguridad.Para esto último,se debe configurar la opción «Backup priority» en las propiedades del grupo de disponibilidad.
– Permiten acceder a los datos de las réplicas secundarias para consultas de solo lectura o para operaciones de mantenimiento o copia de seguridad, lo que mejora el rendimiento y la escalabilidad.
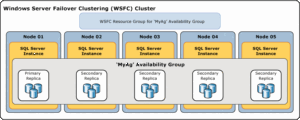
– Se integran con otras características de SQL Server, como el agrupamiento en clústeres Windows Server Failover Cluster (WSFC), el servicio Broker para controlar el flujo
de mensajes entre las réplicas o el Listener para facilitar el acceso a las bases
de datos mediante un nombre virtual.
¿Qué requisitos se necesitan para usar los grupos de disponibilidad Always On?
Para usar los grupos de disponibilidad Always On se necesitan cumplir los siguientes requisitos:
– Tener instalada la edición Enterprise de SQL Server 2012 o superior, ya que la edición Standard solo permite tener una réplica secundaria y no admite el modo solo lectura ni el enrutamiento de lectura. La edición Developer también admite los grupos de disponibilidad Always On, pero solo para fines de desarrollo y pruebas.
– Tener configurado un clúster WSFC con al menos dos nodos, que serán los servidores donde se alojarán las réplicas primaria y secundaria. El clúster WSFC se encarga de monitorizar el estado de las réplicas y de realizar la conmutación por error si es necesario.
– Tener las bases de datos que se quieren proteger en modo de recuperación completa, lo que implica hacer copias de seguridad periódicas del log de transacciones para evitar que crezca demasiado.
¿Cómo se configuran los grupos de disponibilidad Always On?
Para configurar los grupos de disponibilidad Always On se deben seguir los siguientes pasos:
– Crear un grupo de disponibilidad en el servidor que aloja la base de datos primaria, especificando el nombre del grupo, las bases de datos que se quieren proteger y las opciones de configuración, como el modo de conmutación por error o el modo de acceso a las réplicas secundarias.
– Añadir una o más réplicas secundarias al grupo de disponibilidad, especificando el servidor donde se alojan, el modo de compromiso y el modo de acceso. También se debe indicar si la réplica secundaria será una copia de seguridad preferente o si tendrá habilitado el enrutamiento de lectura.
– Inicializar las réplicas secundarias mediante una copia de seguridad y restauración de las bases de datos primarias o mediante una sincronización automática si se dispone de una conexión compartida entre los servidores.
– Verificar el estado y el funcionamiento del grupo de disponibilidad, comprobando que las réplicas están sincronizadas, que se pueden realizar consultas sobre ellas y que se puede conmutar por error entre ellas.
Conclusión
Los grupos de disponibilidad Always On son una solución avanzada y flexible para garantizar la alta disponibilidad y la recuperación ante desastres de las bases de datos SQL Server. Permiten tener varias réplicas sincronizadas de una base de datos primaria, que pueden asumir el rol de primaria en caso de fallo o servir para consultas de solo lectura o para operaciones de mantenimiento o copia de seguridad. Para usar esta característica se requiere tener la edición Enterprise de SQL Server 2012 o superior y configurar un clúster WSFC. En este artículo hemos explicado cómo funcionan los grupos de disponibilidad Always On, qué ventajas ofrecen y cómo configurarlos paso a paso. Si os ha quedado alguna duda o comentario ya sabeis que podeis ponerlo aquí en los comentarios, mandarme un mail o en twitter.