El Data Saturday Madrid 2024 ha terminado, pero yo aún estoy asimilando todo lo que pasó.
No quería estar nervioso, había trabajado mucho en mi sesión y lo tenía todo preparado. Así confiaba en poder asistir a las distintas sesiones que había marcado en la agenda como imperdibles (spoiler no fue así pero, ahora os cuento más 😅 )
Llegué temprano, a las 8:30am estaba allí, fui directo a la sala de speakers a dejar las cosas y saludar a los compañeros. Tras los abrazos pertinentes, antes de tener que ir al auditorio a la bienvenida y posterior Keynote dedico unos minutos a encender el portátil, probar la conexión wifi de la universidad y primera sorpresa, no consigo conectar con mi base de datos de Azure SQL Database con la que iba a hacer la demo. 😨 No hay tiempo para más, es hora de iniciar el evento en el auditorio, luego solucionaré esto y si no se puede recurriré al plan B (llevaba la demo grabada de casa).
Ya en el auditorio saludo a Héctor, Santiago y Yolanda y tomo asiento para empezar a disfrutar del evento. Ruben Pertusa nos da la bienvenida. No os voy a mentir, ver mi cara en la pantalla junto a todo el resto de speakers, hizo que por un momento me invadiese la emoción y olvidase que en ese momento, tras las pruebas de antes, estaba sin demo. Sin tiempo para levantarnos de nuestros asientos turno para la presentación de uno de los sponsor del evento, Aleson ITC que nos enseñan todas las cosas maravillosas que hacen por y para sus clientes. Todo seguido, a continuación la Keynote de David Hurtado Torán.
Tras esta primera parte mi idea inicial era haber ido a ver a Jose Manuel Jurado Diaz y Juan E. Moreno Romo pero no fue posible, tenía que volver a la sala de speakers a tratar de solucionar mi problema de conexión. Por suerte no fue dificil, era cosa de la conexión de la UPM y con la VPN a casa conectada todo funcionaba a las mil maravillas. Aprovecho el resto del tiempo hasta la siguiente sesión para repasar las notas de mi sesión y a por otra cosa.
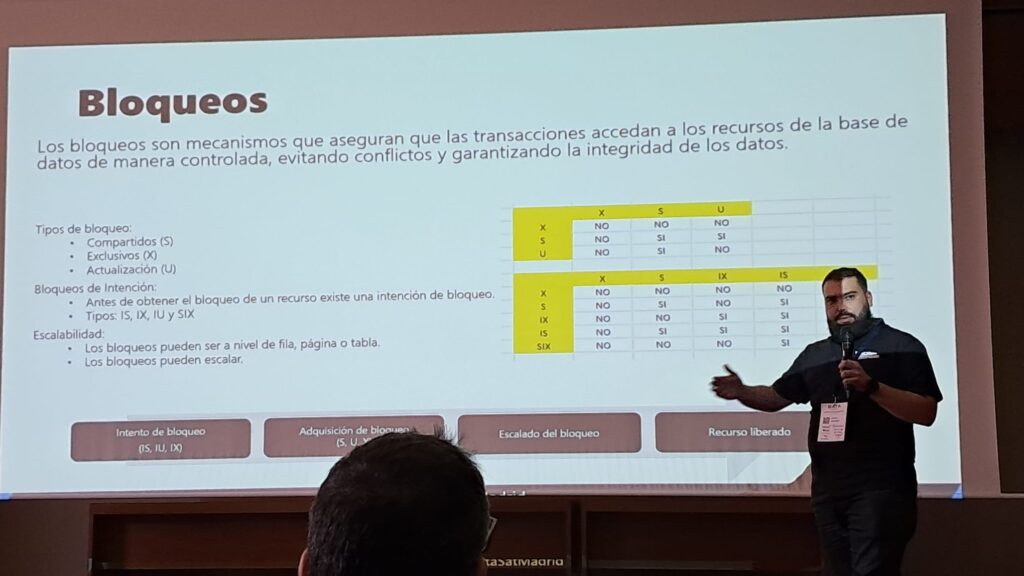
Llega el momento de la segunda charla, esta si que no me la pierdo. El gran Niko Neugebauer (Product Manager de Azure SQL MI) nos cuenta todos los secretos sobre la monitorización de Azure SQL Managed Instance en su charla «Azure SQL Observability». Muchas cosas que contar sobre esta charla pero esto requiere de un artículo dedicado en el blog, ya llegará.
En este punto toca el primer descanso, es hora de tomar un café y, junto con Niko, nos dirigimos a la cafetería. Con un vaso de café en la mano toca volver a la sala de speakers y ahora si preparar todo, soy el siguiente. En este punto no me preguntéis que pasó pero todo lo que había funcionado antes ya no va. El portátil no se volvió a conectar a la red de la UPM y ya no hay tiempo, toca compartir los datos del móvil.
Vuelve Niko a la sala de ponentes y comenzamos a charlar sobre mi sesión que va a empezar en apenas 10 minutos, le cuento un poco de lo que voy a hablar y, sorprendido, me pide un poco de tiempo para consultar su documentación sobre el tema, pero por desgracia tengo que irme a mi sesión que ya va a empezar, charlando nos habíamos comido todo el tiempo de la presentación de Four9s y me la he perdido 😖
Es mi momento, subo al escenario y busco caras conocidas entre el público, decenas de personas están ya sentadas esperando a que empiece a hablarles. Rápidamente localizo a Hector, Santi y Yolanda que están ahí apoyándome. Localizo otras caras conocidas más de algunos seguidores y eso me da tranquilidad, todo va a salir bien, estamos entre amigos. Aunque tener a Jose Manuel y a Juan de Microsoft en primera fila contrasta un poco con ese sentimiento, la verdad. Tenia mucha presión no os voy a engañar. Esperamos unos minutos, que me parecieron horas, a que termine de llegar la gente y empezamos.

La charla fue perfecta, todo salió bien y las demos funcionaron bien (aunque despacito, lo normal usando la suscripción gratis de Azure, no nos engañemos). Los asistentes estaban sorprendidos con lo que mostraba sobre el escenario y eso siempre gusta. Para terminar varias preguntas de los asistentes y un aplauso que me hizo sentirme una estrella.
A la salida de mi charla Niko estaba esperándome, se me acercó y me dijo «tengo respuestas». Mientras yo daba mi charla, él había contactado con los ingenieros de Azure MI y había consultado toda la documentación interna de Microsoft sobre los bloqueos optimizados para todas las futuras versiones que están por venir (Azure MI y SQL Server 2025). Lo que me contó también los contaré en otro artículo. Por ahora toca esperar. Lo que os puedo contar es que charlamos por más de media hora, prácticamente todo el tiempo de la sesión de Cristina Tarabini-Castellani Ciordia, otra que me perdí (lo siento Cris).
Momento de la comida, ya había pasado mi parte y era hora de disfrutar al 100% del evento sin preocupaciones por mi charla. Durante la comida pude compartir «mesa» y un rato agradable con el gran Javier Menendez Pallo, que, para los que no le conocéis, aparte de un tipo listísimo es muy, pero muy, gracioso. No tengo mucho más que destacar de este rato de la comida, solo agradeceros a todos los que os acercasteis a felicitarme por mi charla y a charlar un rato.
Saliendo de la comida, por los pasillos coincido con Jose Manuel y Juan, los ingenieros de soporte de Microsoft que estaban en mi charla en primera fila. Dediqué unos minutos a una charla maravillosa con ellos sobre lo que había expuesto en mi presentación y a comentar los resultados de las demos que tanto sorprendieron al público. Para mi sorpresa alguna cosilla hasta les sorprendió a ellos.
Del resto del día poco más que contar, dediqué las siguientes horas a charlar con amigos. Me llevo una charla maravillosa con Ricardo Rincón, Francisco Mullor Cabrera, Inés Pascual Iglesias y Rubén Pertusa y el volver a coincidir con Pablo Lozano que hacía años que no nos veíamos. Cerramos el evento con el espectáculo, digo la charla, de Pallo y pasamos al divertido cierre del evento con el quiz y los sorteos de los regalos. Tomamos unas cervezas charlando con unos y con otros y para finalizar el día nos fuimos a cenar. Un cierre a la altura de un día espectacular tomando cervezas con Adrián Alvarez Molina, Frank Geisler y Olivier Van Steenlandt.
Para terminar os dejo unas cuantas fotos del evento.