
¿Alguna vez os han dicho que un índice que no se usa empeora el rendimiento de una consulta SELECT? Todos hemos oído que los índices penalizan la escritura y eso es cierto como que odio madrugar para trabajar pero, las lecturas no se ven afectadas, ¿verdad? ¿Estáis seguros? Recientemente recibí en mi bandeja de entrada el último boletín de la newsletter de SQLAuthority sobre un extraño comportamiento con los índices en SQL Server y me ha parecido tan interesante que he sentido la necesidad de compartirlo con vosotros. Aunque, como os digo, la idea detrás de este post no es mía y es plenamente de Pinal Dave me voy a tomar la libertad de traducirlo y compartirlo con vosotros.
Introducción
Este email que activó mi sentido arácnido:
Hi there,
Have you ever seen that Index which is not used for the query reduces the performance of the SELECT statement?
If yes, good, you can stop reading this email here.
If no, here is the video you MUST WATCH
That’s it! Have a good day.
~ Pinal from SQL Authority
Cuando lo he leído no me lo podía creer, ¿cómo un índice que no se usa puede empeorar el rendimiento de una consulta de lectura? Sabemos que los índices empeoran los procesos de escritura pero, es justamente porque se usan y se escribe en ellos además de en la tabla. Pero en las lecturas no, eso no es lo que dicen los libros de SQL. Sin embargo, de Pinal me fio completamente (ha demostrado sobradamente saber mucho de esto) así que he ido al video y en efecto, en él demuestra empíricamente lo que dice en el correo.
Tan atónito estaba al terminar los doce minutos de demo de Pinal que he ido raudo a comprobarlo en mi propio servidor de pruebas. En el video, Pinal usa la base de datos AdventureWorks2014 y en las respuestas a los comentarios dice haberlo probado tanto con modo de compatibilidad 2017 como 2019. En mi laboratorio de pruebas yo tengo un 2022 así que perfecto vamos a ver que pasa.
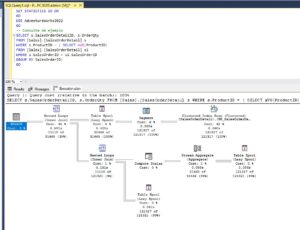
Consulta sin índice
Ejecutamos la consulta sobre la tabla, sin haber creado ningún índice vemos que hace un escaneo de la PK que supone el 42% de la consulta. En cuanto a lecturas, si miramos los mensajes de las estadísticas de E/S vemos que se está leyendo 1238 páginas de disco de 8 Kb, lo que son aproximadamente 10 Mb de datos. Sin embargo para leer esos 10Mb de datos, necesita una tabla auxiliar de la que lee 368.495 páginas o lo que es lo mismo 2,8 Gb de información.
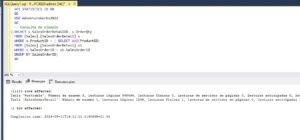
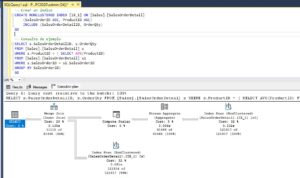
Creemos un índice
Obviamente este rendimiento no es el esperado, leer casi 3 Gb de información para devolver 10 Mb, no sé a vosotros, pero a mi no me parece correcto. Así que creemos un índice llamado IX_1 tal como aprendimos en este otro post y probemos. Vale, tenemos dos lecturas de la tabla y eso no es lo mejor, pero tampoco es un problema. Mirad las estadísticas, tenemos simplemente 610 páginas leídas o lo que es lo mismo, 5Mb de información.
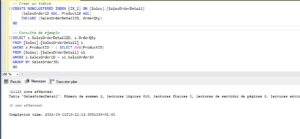
Creando otro índice
Un caso de uso normal sería ahora crear otro índice invirtiendo el orden de los campos clave para verificar si el rendimiento mejora o no. Sin embargo, al hacerlo, nos vamos a encontrar con la sorpresa que da título a este post. No solo la consulta sigue usando el primero de los índices sino que han vuelto los Table Spool y aunque las páginas leidas de la tabla han bajado a la mitad que antes, tenemos otra vez esos casi 3 Gb de lecturas de la tabla de trabajo.
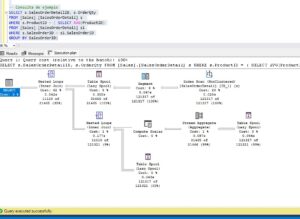
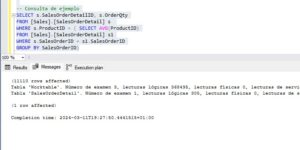
Otras pruebas
No os voy a aburrir con más capturas de pantalla, creo que ya lo habéis pillado. Deciros que lo he probado en todos los niveles de compatibilidad posibles de una base de datos desde SQL 2014 hasta 2022 y el resultado ha sido idéntico.
También he probado con actualizaciones de las estadísticas de la tabla, borrando la caché de planes de ejecución entre las pruebas, con el hint de index para forzarle el uso del índice en las dos ejecuciones y con un hint de RECOMPILE. Todo con el mismo resultado. Para terminar he cambiado la consulta y he usado un join en vez de la subquery pero nada, en todos los casos aparecían esas lecturas al tener el segundo índice creado aunque en el plan de ejecución no aparezca en uso por ningún lado y al borrarlo volvía a los dos escaneos sin lecturas de tablas auxiliares.
Os diré más, en este punto con ya el artículo escrito se me ha ocurrido una cosa, he borrado el índice 2, he ejecutado la consulta que se ha ejecutado con el plan correcto, he ido a Query Store y he forzado ese plan, luego he creado el índice y, ¿sabéis que? LO HA VUELTO A HACER MAL. Si amigos, incluso forzando en Query Store el plan correcto, SQL me ha sacado el dedo y ha hecho lo peor para él, como un hijo adolescente que no entiende que miras por su bien.
Conclusiones
¿Y ahora que digo yo? ¿Qué conclusión sacamos de esto? Que lo que pone en los libros no es correcto? Igual es que SQL Server hace cosas sin sentido o que visto esto debería pasarme a Oracle? Lo cierto es que no he conseguido encontrar una explicación a lo que está pasando pero ahí está. En su video, Pinal llega al mismo punto, no entiende lo que pasa y obviamente no tiene sentido. Parece un bug del motor de base de datos sin resolver desde hace un montón de tiempo. Por mi parte seguiré probando esto en cada nueva versión de SQL Server y si veo que se resuelve espero poder avisaros por aquí. De momento, no nos queda otra, revisemos los índices de nuestras bases de datos y borremos los que no estén en uso por si nos están penalizando.

Espero que este artículo te haya sido útil y que te ayude a optimizar el rendimiento de tus consultas en SQL Server. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
PD.: Si alguno queréis ir a la fuente original os dejo el vídeo por aquí.