En estos últimos días hemos hablado del particionado de tablas como una de las medidas más eficaces para reducir la lectura de páginas de disco y reducir así el consumo de E/S, RAM y CPU. También vimos casos prácticos del particionado vertical de tablas y medimos su impacto en nuestras consultas. Hoy le toca el turno al particionado horizontal. El particionado horizontal consiste en dividir una tabla grande en varias partes más pequeñas, llamadas particiones, que se almacenan en diferentes grupos de archivos. De esta forma, podemos mejorar el rendimiento, la disponibilidad y la administración de los datos.
Elegir una buena columna de particionado horizontal
Lo primero que tenemos que decidir es por qué columna vamos a particionar. Esta será una columna por la que siempre se filtre y que no tenga o tenga muy poca variación. Lo más común es que sean columnas de fecha pero no es ninguna norma. Podremos crear particiones por cualquier columna que no sea de tipo timestamp o datos LOB (ntext, text, image, xml, varchar(max), nvarchar(max) y varbinary(max)). Lo que sí podemos usar son columnas calculadas siempre y cuando se creen con la condición PERSISTED. Esto nos es especialmente útil cuando queremos particionar por una concatenación de varias columnas.
Estas reglas se aplican tanto para particionar tablas como índices. Normalmente la partición de los índices Nonclustered será la misma que la de la tabla subyacente. Esto se llama índice alineado y permite al motor de base de datos cambiar las particiones de la tabla de forma rápida y eficaz al mismo tiempo que mantiene la estructura de la partición tanto en la tabla como en sus índices.
Elegir una buena función de particionado horizontal
La función de partición es clave para el éxito del particionado horizontal. Lo que hace este objeto es especificar cómo se van a repartir los datos en función de las particiones que hemos creado. Una buena función de partición debe cumplir dos requisitos:
- Debe distribuir los datos de forma equilibrada entre las particiones, evitando que haya particiones muy grandes o muy pequeñas.
- Debe facilitar el acceso a los datos según el patrón de uso, evitando que haya que consultar varias particiones para obtener la información deseada.
Para elegir una buena función de partición, debemos analizar las características de los datos y las consultas que se realizan sobre ellos. Algunos factores a tener en cuenta son:
- El tipo y el rango de valores de la columna de partición.
- La frecuencia y el volumen de inserción, modificación y eliminación de los datos.
- La frecuencia y el tipo de consultas que se realizan sobre la tabla.
- El nivel de detalle o agregación que se requiere en las consultas.
Aunque en otros motores de bases de datos existen dos tipos de funciones de partición: por rango y por hash. En SQL Server solo vamos a poder particionar por rango. Las funciones por rango asignan los datos a las particiones según un intervalo de valores definido para cada una. Las funciones por hash asignan los datos a las particiones según un algoritmo matemático que calcula un valor numérico para cada fila. Cada tipo tiene sus ventajas e inconvenientes, dependiendo del caso de uso.
Diseñar un buen esquema de particionado horizontal
El esquema de particionado define en qué grupo de archivos se almacena cada partición. Un grupo de archivos es una colección lógica de archivos físicos que contienen los datos y los índices de una base de datos. SQL Server permite crear varios grupos de archivos para una misma base de datos, y asignar cada uno a una unidad diferente. Un buen esquema de particionado debe aprovechar esta característica para mejorar el rendimiento y la disponibilidad de los datos. Algunas recomendaciones son:
- Crear un grupo de archivos por cada partición, y asignar cada grupo a una unidad diferente. De esta forma, se evita la contención de recursos y se aumenta el paralelismo en las operaciones de lectura y escritura. Esto no siempre podremos hacerlo, por ejemplo el particionado es una característica compatible con Azure Databases pero no los distintos grupos de archivos por lo que todos los archivos pertenecerán al mismo Filegroup.
- Crear un grupo de archivos adicional, llamado grupo de archivos primario, que contenga los metadatos de la base de datos y las tablas no particionadas. Este grupo debe estar en una unidad diferente a los demás grupos de archivos.
- Crear un grupo de archivos vacío, llamado grupo de archivos de reserva, que se pueda usar para añadir o mover particiones en caso de necesidad. Este grupo debe estar en una unidad con suficiente espacio libre.
Prueba de concepto
Para esta prueba vamos a usar la tabla [Sales].[SalesOrderHeaderSalesReason] de la base de datos AdventureWorks, esta tabla tiene aproximadamente 31.000 registros que van del año 2011 al 2014. Creando un particionado por la columna OrderDate para tener particiones por año y haciendo una consulta simple a la tabla podemos observar como la reducción en el número de páginas leídas es apreciable.
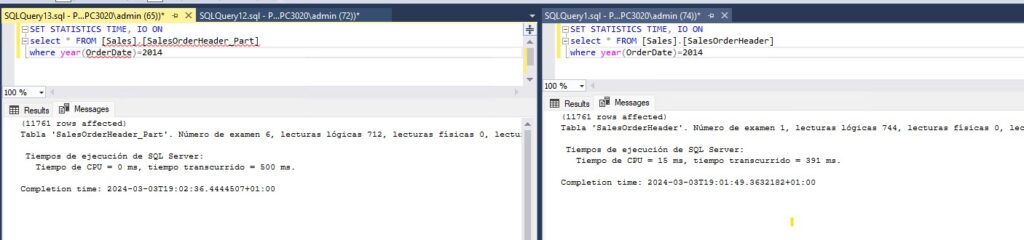
Os dejo el script que he usado para particionar esta tabla:
CREATE PARTITION FUNCTION [ParticionadoAnual_SalesOrderHeader](datetime) AS RANGE RIGHT FOR VALUES (N'2011-01-01T00:00:00', N'2012-01-01T00:00:00', N'2013-01-01T00:00:00', N'2014-01-01T00:00:00', N'2015-01-01T00:00:00')
CREATE PARTITION SCHEME [EsquemaAnual_SalesOrderHeader] AS PARTITION [ParticionadoAnual_SalesOrderHeader] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY])
CREATE CLUSTERED INDEX [ClusteredIndex_on_EsquemaAnual_SalesOrderHeader_638450888550526845] ON [Sales].[SalesOrderHeader]
([OrderDate]) WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [EsquemaAnual_SalesOrderHeader]([OrderDate])Conclusión
El particionado horizontal de tablas en SQL Server es una técnica muy poderosa para optimizar el manejo de grandes volúmenes de datos. Sin embargo, requiere un análisis previo y un diseño cuidadoso para obtener los mejores resultados.
Espero que este artículo te haya sido útil y que te ayude a optimizar el rendimiento de tus consultas en SQL Server. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn al que te puedes unir. ¡Hasta la próxima!