Hoy tenemos un artículo completamente práctico poniendo en práctica y comparando las distintas soluciones de particionado vertical de tablas en SQL Server que vimos ayer en la teoría. ¿Será la mejora de rendimiento tal como la pintan? ¿Merece la pena el esfuerzo? Espero que al concluir la lectura de este artículo puedas sacar tus propias conclusiones y estés capacitado para hacer tus propias pruebas en tu entorno de test para decidir si te interesa o no.
Particionado vertical con vistas
Vamos a empezar con el escalado vertical con vistas indexadas. Para ello tenemos una tabla Personas que es una copia de la tabla Person.Person de AdventureWorks a la que le he añadido una columna varchar(max). He cargado la tabla con 15 veces los registros de la tabla Persons y para la columna varchar(max) he replicado un texto relativamente largo 100 veces por cada registro.
CREATE TABLE [Person].[Personas](
[BusinessEntityID] [int] NOT NULL IDENTITY (1,1),
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
[Description] [VARCHAR] (MAX),
CONSTRAINT [PK_Personas_BusinessEntityID] PRIMARY KEY CLUSTERED
([BusinessEntityID] ASC)
)INSERT INTO [Person].PERSONAS (PersonType,NameStyle,Title,FirstName,MiddleName,LastName,Suffix,EmailPromotion,AdditionalContactInfo,Demographics,rowguid,ModifiedDate,[Description])
SELECT PersonType,NameStyle,Title,FirstName,MiddleName,LastName,Suffix,EmailPromotion,AdditionalContactInfo,Demographics,rowguid,ModifiedDate,REPLICATE ('Humano Supuestamente Inteligente',100) FROM [Person].[Person]
GO 15Esta es una lectura sobre la tabla:
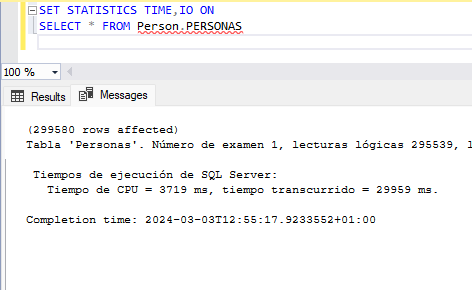
Para nuestra prueba de lectura vamos a renunciar a la lectura del campo Description que es el varchar(max), sin embargo el número de páginas de disco leídas sigue siendo el mismo. Probemos a crear una vista indexada sin ese campo y otra solo con ese campo y el ID.
CREATE VIEW VPERSONAS
WITH SCHEMABINDING AS
SELECT BusinessEntityID,PersonType,NameStyle,Title,FirstName,MiddleName,LastName,Suffix,
EmailPromotion,AdditionalContactInfo,Demographics,rowguid,ModifiedDate
FROM Person.PERSONAS
GO
CREATE UNIQUE CLUSTERED INDEX CI_Personas ON VPERSONAS ( BusinessEntityID,PersonType,NameStyle,Title,FirstName,MiddleName,LastName,Suffix,
EmailPromotion,rowguid,ModifiedDate);
GO
CREATE VIEW VPERSONAS_Descipcion
WITH SCHEMABINDING AS
SELECT BusinessEntityID,Description
FROM Person.PERSONAS
GO
CREATE UNIQUE CLUSTERED INDEX CI_Personas_Descripcion ON VPERSONAS_Descipcion ( BusinessEntityID);Y ahora leamos la primera vista:
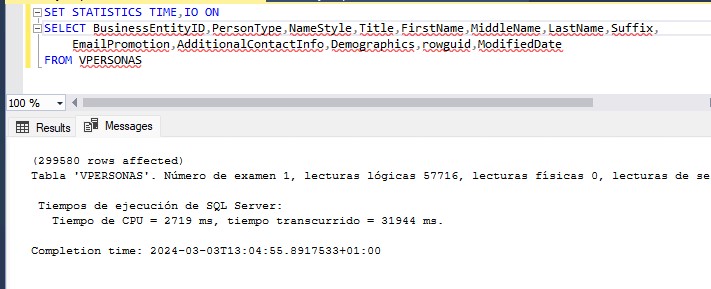
Conclusiones:
Como veis, hemos conseguido reducir el número de lecturas para la misma consulta de 295.539 páginas a 57.716, parece que el resultado es bueno. Pero no solo eso, cuando hablamos de las vistas indexadas, comentamos que en las versiones Enterprise de SQL Server, el motor de base de datos era capaz de usar el índice de la vista aunque lo que estamos consultando fuera la tabla así que el resultado para una lectura sobre la tabla será el mismo si tenemos esta edición de SQL Server.
Particionado vertical con tablas
Para este ejemplo vamos a crear una tabla que contenga el ID y Description de la tabla Personas. Luego borraremos Description de la tabla personas y veremos el resultado:
CREATE TABLE [Person].[PersonasDes](
[BusinessEntityID] [int] NOT NULL ,
[Description] [VARCHAR] (MAX),
CONSTRAINT [PK_PersonasDes_BusinessEntityID] PRIMARY KEY CLUSTERED
([BusinessEntityID] ASC)
)
GO
INSERT INTO [Person].[PersonasDes]
SELECT [BusinessEntityID], [Description] FROM Person.Personas
GO
ALTER TABLE Person.Personas DROP COLUMN [Description] Hagamos ahora una lectura de la tabla personas:
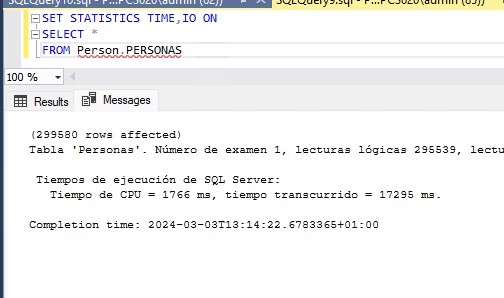
¿Qué ha pasado? El número de páginas no se ha reducido. Esto tiene una explicación, el texto de la columna Description no era tan grande como para estar en páginas LOB por lo que al borrarlos simplemente hemos dejado libre el espacio en las páginas de datos pero los datos que permanecen siguen distribuidos de la misma manera. Tenemos una fragmentación muy alta de los datos que solucionaremos con un mantenimiento del índice clustered.
ALTER INDEX PK_Personas_BusinessEntityID ON Person.PERSONAS REBUILDY ahora sí una lectura nos mostrará una cantidad muy inferior de páginas leídas:
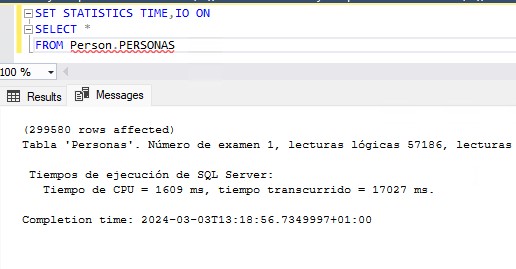
Conclusiones
En esta ocasión el resultado es incluso mejor que en la opción anterior de particionado vertical con vistas. Esto se debe a que los campos XML de la tabla personas no podemos añadirlos al índice de la vista indexada por lo que SQL tenía que hacer un Key Lookup sobre las páginas de datos de la tabla para recuperar esa información. Además, los datos no están almacenados por duplicado (en el índice clustered de la tabla y en el de la vista). Tiene el inconveniente de que tendremos que modificar el código de las consultas de la aplicación al haber cambiado el modelo de datos pero, si podemos afrontar eso, a cambio ganamos en menor consumo de recursos.
Conclusión final
El particionado vertical es una gran solución para paliar problemas de cuello de botella de E/S de disco así como de RAM y CPU. La opción de particionar con vistas es sencilla de implementar si no tenemos problemas de capacidad de almacenamiento y obtendremos resultados de una manera transparente para los usuarios de la base de datos si tenemos una edición Enterprise. El particionado vertical con tablas es más completo y nos da un mejor rendimiento en caso de tipos de datos que no se admiten en índices pero, por contra, requiere una modificación en el código de nuestras consultas. Nos ha quedado por ver el particionamiento horizontal del que también hablamos en el pasado artículo. Este tipo de particionamiento tiene más cosas que valorar y requiere de un artículo específico. Permanece atento al blog que el próximo día hablaremos de particionado horizontal.
Espero que este artículo te haya sido útil y que te ayude a optimizar el rendimiento de tus consultas en SQL Server. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn al que te puedes unir. ¡Hasta la próxima!