El pasado viernes andaba yo absorto en la masterclass de Salvador Ramos en Nasmasdata cuando, de repente, una diapositiva salvaje apareció. Salva nos hablaba de un cálculo de stock acumulado con su fórmula en DAX porque según ponía en SQL era un cálculo imposible. ¿IMPOSIBLE? Eso era un reto para mí, así que, raudo tomé una captura de pantalla y acepté ese reto. No hubo que esperar mucho, hoy sábado, de buena mañana me he sentado delante del ordenador, he creado una tabla con los datos necesarios para la prueba y me he puesto manos a la obra. No sin antes contactar a Salva e informarle de lo que estaba aconteciendo porque sí amigos, Salva sabe de la existencia de este artículo días antes que vosotros, para la próxima que el reto venga de vosotros y estaréis informados antes.

Entendiendo el reto en DAX
Lo primero que tenemos que entender es lo que nos propone el reto, la medida DAX que se ve en la imagen es esta:
Stock Acumulado =
CALCULATE(
[Stock Final],
FILTER(
ALL(Fecha),
Fecha[Fecha] <= MAX(Fecha[Fecha])
)
)Por un lado CALCULATE es una función que cambia una expresión en un contexto de filtro modificado. Como parámetros le hemos pasado [Stock Final] que es una medida o una calculada que nos sumariza los movimientos de stock. Para el segundo parámetro hemos pasado la función FILTER con dos parámetros más, el resultado es que filtra la tabla Fecha para incluir solo las filas donde la fecha es menor o igual a la fecha máxima en el contexto actual.
Convirtiendo el DAX a T-SQL
Ahora que ya sabemos lo que tenemos que obtener vamos a ver como debemos hacerlo en SQL Server, a ver si realmente era imposible o no. He de deciros que mi tabla solo tiene dos columnas fecha y stock. Podriamos haber complicado el escenario añadiendo artículos pero para la demo nos vale sin eso, supongamos que tenemos solo uno. Como luego vamos a llevarnos estas tablas a Power BI tal como están en SQL no hay problema, en DAX vamos a jugar en las mismas condiciones.
Para empezar vamos a tener que totalizar por dias para saber cuantos movimientos hemos tenido ese día. Luego tenemos que hacer una suma de los valores desde la primera fecha hasta la fecha actual. Eso lo podremos lograr con una función de ventana. Esta sería la consulta imposible:
SELECT
Fecha,
SUM(Stock_Final) OVER (ORDER BY Fecha ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as Stock_Acumulado
FROM
( SELECT Fecha, sum(Stock_Final) as Stock_Final FROM stock_demo GROUP BY fecha ) f
WHERE
Fecha <= (SELECT MAX(Fecha) FROM stock_demo)
ORDER BY
FechaVamos a verla paso a paso. En lo primero que nos tenemos que fijar es en la subconsulta del FROM. Es justo lo que comentábamos antes, la suma de los movimientos de stock agrupados por día. Luego, en la consulta principal, estamos utilizando una función de ventana para calcular el Stock_Acumulado. Esta función de ventana SUM() OVER (ORDER BY Fecha ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) suma los valores de Stock_Final en todas las filas desde el inicio de la tabla (UNBOUNDED PRECEDING) hasta la fila actual (CURRENT ROW), ordenadas por Fecha. Esto da como resultado un total acumulativo de Stock_Final hasta la fecha actual.
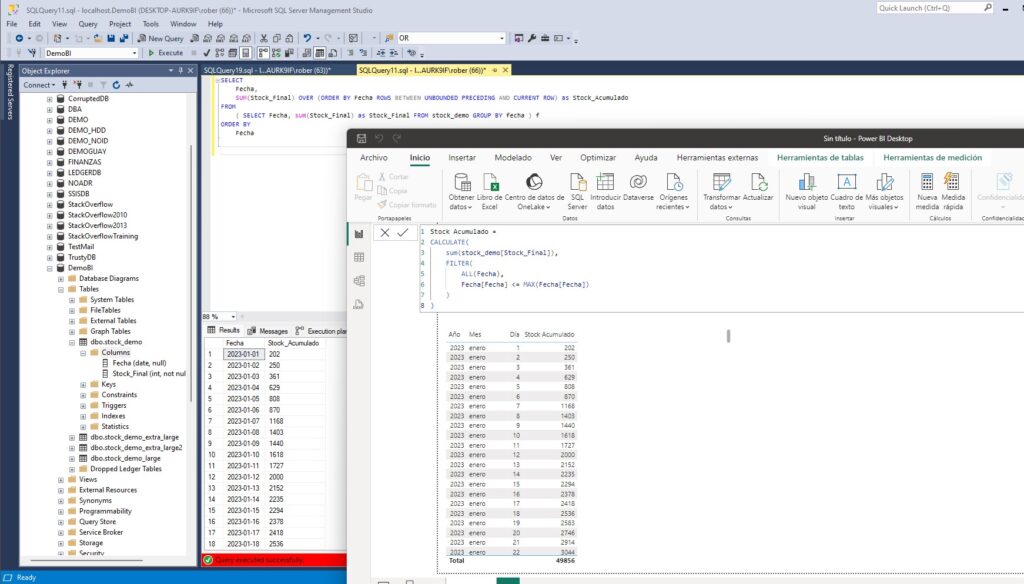
Ya lo tenemos, no era imposible. Sin embargo, a lo que Salva se refería era los inconvenientes de realizar los cálculos en SQL por tiempos. Y realmente este es un pensamiento muy extendido en el sector. DAX es más rápido realizando cálculos que SQL Server. Pero, ¿realmente es cierto? Vamos a verlo.
Comparativas de rendimiento DAX vs SQL
Para que los resultados puedan ser representativos, vamos a hacer las pruebas sobre una tabla con algo más de 1 millón de registros, algo normal en una empresa pequeña. Vamos a analizar dos años de datos de movimientos de stock. Para medir los tiempos de la consulta DAX he sacado la consulta de la tabla y la he llevado a DAX Studio. En SQL vamos a usar las estadísticas de tiempo que podemos sacar con SET STATISTICS TIME ON.
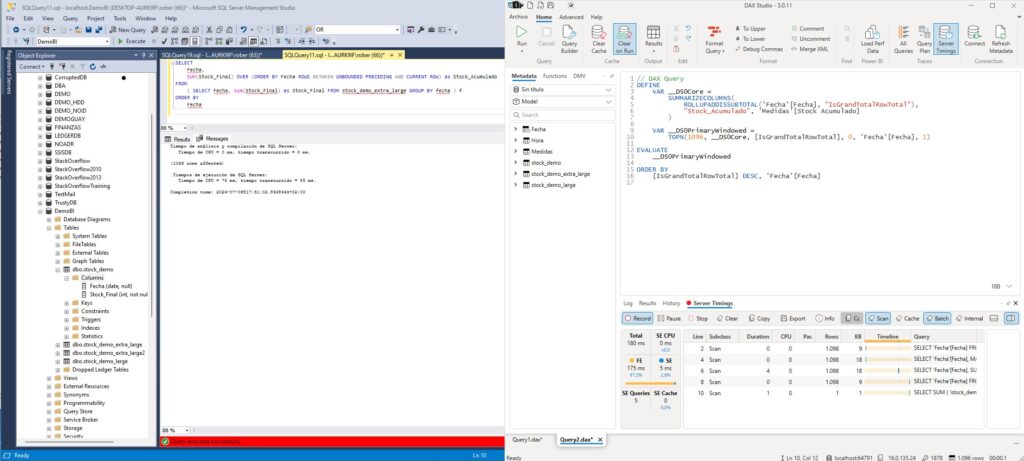
Como vemos los resultados son demoledores y para nada lo esperado. Analizando 1.010.000 registros repartidos en 1096 fechas distintas SQL Server se ha demorado 85 milisegundos de los cuales 78 ms han sido CPU. En DAX Studio podemos ver que la fórmula DAX para la tabla ha tardado 180 milisegundos, repartidos entre 175 ms del motor de fórmulas (FE) y 5 ms del motor de almacenamiento (SE).
Complicando el escenario
Vamos a pasar de 1 millón a 15 millones de registros a ver si los resultados son distintos. Todos sabemos que el fuerte de Power BI reside en su motor Vertipaq y su gran capacidad de trabajar con grandes cantidades de datos.
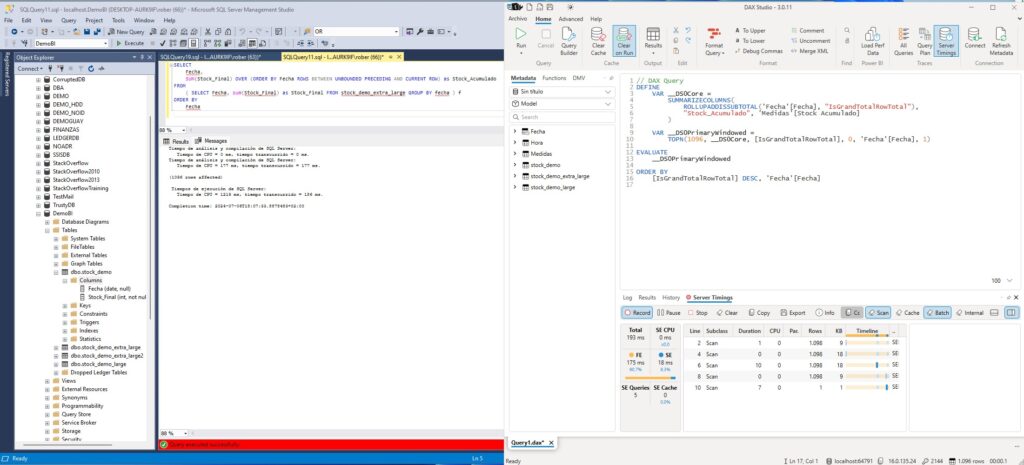
Ahora sí que vemos la gran diferencia de tiempos de la que todo el mundo habla en DAX y Power BI. Con 15 millones de registros los tiempos en SQL Server se han disparado a 1219 milisegundos de CPU aunque paralelizando la consulta se ha resulto en 186 ms. En DAX tenemos un tiempo total de 193 milisegundos repartidos en 175 ms del motor de fórmulas (FE) y 18 ms del motor de almacenamiento (SE). Aunque los tiempos de DAX son mayores a los de SQL no hay tanta diferencia y teniendo en cuenta el paralelismo de SQL podemos deducir un mayor consumo de recursos si ejecutamos los cálculos en origen.
Mejorando los tiempos de SQL
Ya sabemos el objetivo a batir en DAX 193 ms. Veamos qué podemos hacer en SQL. Para empezar vamos a probar con un índice columnar sobre la tabla, al fin y al cabo los índices columnares son la misma tecnología que el motor vertipaq de Power BI.
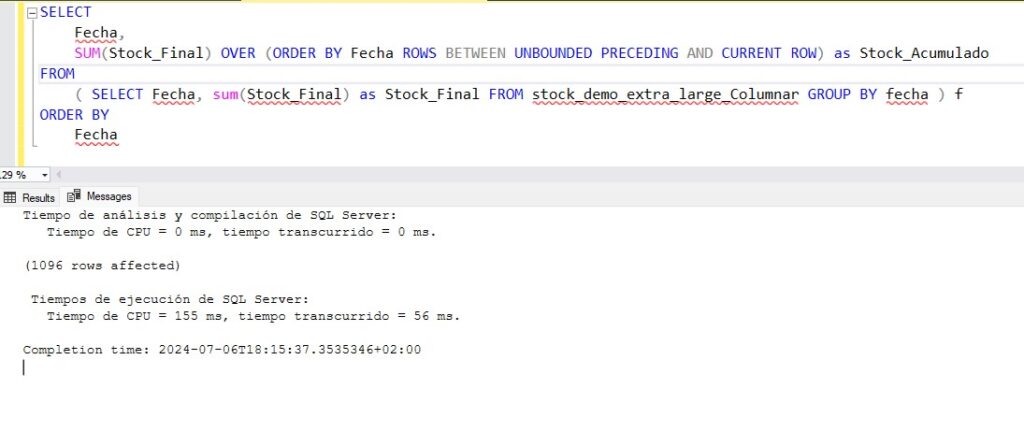
Ahí lo tenemos, ahora sí. Nuestra consulta sobre la tabla con índices columnares ha tardado 155 milisegundos de CPU y solo 56 ms totales al paralelizar. Aun así esto todavía se puede mejorar, ¿recordáis las vistas indexadas? Vamos a probarlo.
CREATE VIEW Stock_Final_View
WITH SCHEMABINDING
AS
SELECT
Fecha,
COUNT_BIG(*) as row_count,
SUM(ISNULL(Stock_Final, 0)) as Stock_Final
FROM
dbo.stock_demo_extra_large_Columnar
GROUP BY
fecha;
GO
CREATE UNIQUE CLUSTERED INDEX IDX_Stock_Final_View
ON Stock_Final_View (Fecha);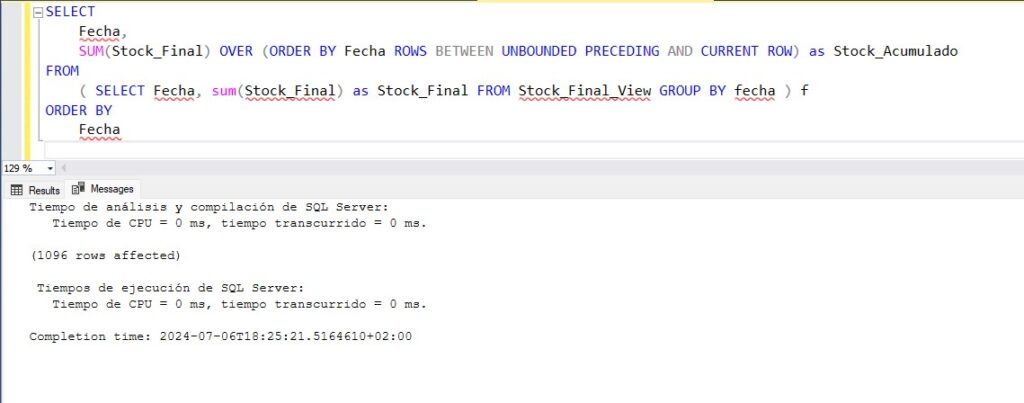
¿Qué os parece el resultado? ¿Os lo esperabais? Con la combinación de índice columnar más vista indexada hemos podido ejecutar la consulta pesada sobre 15 millones de registros en menos de un milisegundo. A mi me ha sorprendido la verdad. No esperaba tanta mejoría.
Es importante destacar que esto es una prueba de concepto en un entorno de laboratorio sin carga de trabajo donde puedo hacer todos los cambios que quiero sobre el SQL sin afectar a ningún otro proceso. Esto es un escenario muy simplificado para la DEMO sin ningún parecido con una base de datos de un ERP de producción. Como siempre digo, primero válida en tus servidores de pruebas y luego, si ves que va bien y no da problemas, piensa en aplicarlo en producción.
Conclusión
SQL sigue más vivo que nunca. Es verdad que DAX es muy potente y seguro que tiene un montón más de optimizaciones de las que yo he sido capaz de aplicar. Os diré que para las pruebas estaba la inteligencia de tiempos desactivada y como dimensión de tiempos estaba usando la plantilla que Salva proporciona gratuitamente en su web que entiendo que es la que usa él.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
PD.: Salva, no me importa el resultado de estas pruebas, tu sigues siendo un referente para mi 🙂.