Una de las primeras cosas que hacemos, o por lo menos que deberíamos hacer, cuando estamos analizando el rendimiento de una consulta es mirar su plan de ejecución. En los planes de ejecución vemos paso a paso y gráficamente lo que hace nuestra consulta. Cada uno de estos pasos de los que hablamos está representado gráficamente por un operador y la mayoría son intuitivos y fáciles de comprender pero hay un tipo en concreto que parece que cuesta un poco más. Me refiero como no podía ser de otra manera a los operadores Spool. Estos componentes pueden marcar la diferencia en términos de eficiencia y tiempo de respuesta de las consultas. En este artículo, profundizaremos en los diferentes tipos de Spool, su propósito, cómo funcionan y cuándo deberíamos prestarles atención.
¿Qué es un operador Spool?
Antes de entrar en detalles, es importante entender qué es un operador Spool. Básicamente, son operadores que almacenan temporalmente un conjunto de filas durante la ejecución de una consulta. Este almacenamiento permite que SQL Server reutilice estos datos en lugar de volverlos a calcular o volver a leerlos desde el disco, lo que puede resultar en una mejora significativa del rendimiento en determinadas situaciones. Existen varios tipos de operadores spool en SQL Server y, aunque todos comparten la definición que hemos mencionado, cada uno tiene sus particularidades.
Table Spool
El «Table Spool» es el tipo de Spool más común en SQL Server. Su objetivo principal es almacenar el resultado de una subconsulta o una parte del plan de ejecución que es probable que se reutilice. Este tipo de operador suele aparecer cuando tenemos consultas que requieren repetir una operación costosa varias veces. Por ejemplo, si una subconsulta se ejecuta en múltiples ocasiones dentro de una misma consulta, SQL Server puede decidir almacenar temporalmente el resultado de esa subconsulta en un Table Spool para evitar esas múltiples ejecuciones.
Un detalle importante a considerar es que, aunque el Table Spool puede reducir el tiempo de ejecución en general, también consume memoria temporal para almacenar los datos, lo que podría impactar en la eficiencia si el tamaño del Spool es considerablemente grande.
Index Spool
El «Index Spool» se utiliza cuando SQL Server anticipa que necesitará un índice temporal para mejorar la búsqueda de datos en una consulta específica. Este operador crea un índice en memoria, que puede ser utilizado para acelerar operaciones como JOINs o búsquedas basadas en condiciones de filtrado. Aunque esta operación añade un paso adicional al plan de ejecución, la creación de un índice temporal puede resultar en un rendimiento significativamente mejorado, especialmente en consultas que trabajan con grandes volúmenes de datos.
La clave para entender el impacto de un Index Spool está en el balance entre el coste de crearlo y los beneficios que aporta en la fase de búsqueda. En escenarios donde se ejecutan varias búsquedas en un conjunto de datos sin un índice adecuado, este operador se convierte en una solución efectiva.
Row Count Spool
El «Row Count Spool» es un tipo de operador que se emplea principalmente para controlar el número de filas que se procesan en una operación. A diferencia de los Spool anteriores, este no almacena datos per se, sino que mantiene un conteo de las filas que pasan a través de él. Este operador suele aparecer en situaciones donde se requiere un número preciso de filas como resultado de una subconsulta, como cuando usamos la cláusula TOP o una condición de filtrado que limita las filas a procesar.
En resumen, este operador actúa como un portero de discoteca que asegura que solo pasen el número exacto de filas necesarias. Es especialmente útil en operaciones que pueden generar un gran número de filas intermedias, pero donde solo se necesita un subconjunto de ellas. Así, el Row Count Spool ayuda a evitar el procesamiento innecesario, optimizando el rendimiento de la consulta.
Window Spool
El «Window Spool» es menos común pero no menos importante. Este tipo de operador se emplea principalmente en consultas que utilizan funciones de ventana, como ROW_NUMBER(), RANK() o LEAD(). El propósito del Window Spool es soportar el cálculo de estas funciones, almacenando temporalmente el conjunto de datos sobre el cual se aplicarán las funciones de ventana.
Las funciones de ventana requieren acceso a un conjunto completo de datos para calcular correctamente sus resultados. El operador Window Spool permite que SQL Server mantenga un «almacén» de estas filas mientras las operaciones de ventana se ejecutan, garantizando así que el resultado sea el esperado. Aunque puede añadir cierta sobrecarga en términos de memoria, su beneficio en la correcta ejecución de funciones analíticas es crucial.
Optimización y uso
Entender cuándo y cómo aparecen los Spool en los planes de ejecución es vital para optimizar el rendimiento de nuestras consultas. Si bien estos operadores pueden mejorar la eficiencia en muchos casos, su uso inadecuado o innecesario puede tener el efecto contrario. Es fundamental analizar los planes de ejecución y evaluar si la presencia de un Spool está realmente justificada en base al coste adicional que implica su utilización.
En algunos casos, podríamos encontrar que la eliminación de un Spool innecesario, ya sea mediante la reescritura de la consulta o ajustando los índices, resulta en un rendimiento superior. También es importante recordar que estos operadores suelen consumir memoria temporal, por lo que su impacto en la carga general del sistema debe ser monitorizado de cerca.
Recursión
Las consultas recursivas son un ejemplo de la necesidad de operadores Spool. En una consulta recursiva típica, SQL Server tiende a utilizar dos tipos de Spool que resultan esenciales para su correcto funcionamiento y optimización: el Table Spool y el Index Spool.
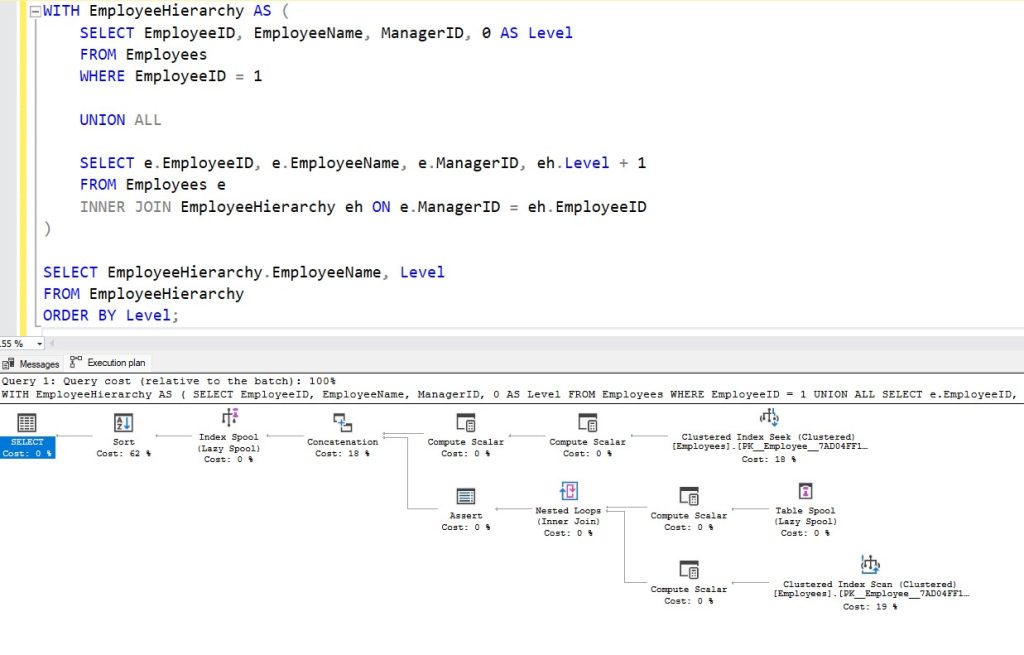
Table Spool en recursividad
Al principio de una consulta recursiva, SQL Server suele emplear un Table Spool. Este operador, como hemos visto, se utiliza para almacenar el conjunto inicial de filas que formarán la base de la recursión, conocido como la parte ancla en un CTE recursivo. La función principal de este operador es capturar estas filas iniciales para que puedan ser reutilizadas a lo largo de las iteraciones recursivas sin necesidad de recalcular o volver a leer los datos desde el origen.
Este Table Spool es especialmente útil en este contexto porque permite que el proceso recursivo se inicie de manera eficiente, asegurando que las filas base estén disponibles para las iteraciones subsiguientes sin añadir un coste significativo de I/O o de CPU. Este operador se convierte en un «almacén temporal» que facilita la generación de los resultados recursivos de manera escalable.
Index Spool en recursividad
En la fase final de la recursión, cuando se procesan y ordenan los resultados, SQL Server suele introducir un Index Spool. Este operador crea un índice temporal en memoria sobre el conjunto de datos generado durante la recursión. La finalidad de este índice es acelerar la búsqueda y ordenación de los datos, especialmente en consultas que requieren un orden específico o que deben cumplir con condiciones adicionales de filtrado.
El Index Spool optimiza la fase de finalización de la consulta recursiva, permitiendo que SQL Server gestione grandes volúmenes de datos generados por la recursión de manera más eficiente. La creación de este índice temporal puede ser costosa en términos de memoria y CPU, pero su impacto positivo en el rendimiento de la consulta suele justificar su utilización, especialmente en estructuras de datos jerárquicas complejas.
Conclusión
Los operadores Spool en SQL Server son herramientas poderosas que, cuando se utilizan correctamente, pueden mejorar significativamente el rendimiento de nuestras consultas. Desde el Table Spool, que almacena datos para evitar cálculos repetidos, hasta el Window Spool, que soporta funciones analíticas, cada tipo de Spool tiene un propósito específico y un impacto en la forma en que SQL Server procesa las consultas.
Para sacar el máximo provecho de los Spool, es esencial comprender cómo y cuándo aparecen en los planes de ejecución y evaluar su eficacia en cada caso. Aunque estos operadores pueden añadir complejidad al plan de ejecución, su correcta utilización puede ser la clave para lograr un rendimiento óptimo en SQL Server.
En definitiva, los Spool no son solo un detalle técnico, sino una pieza fundamental en la optimización avanzada de consultas. Con el conocimiento adecuado, podemos utilizarlos para transformar consultas lentas en operaciones altamente eficientes, maximizando el rendimiento de nuestras bases de datos.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!