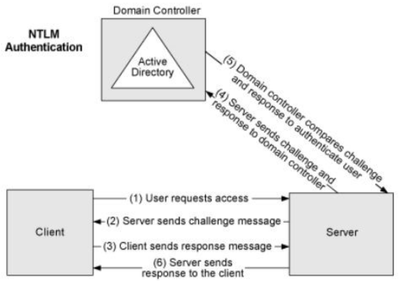
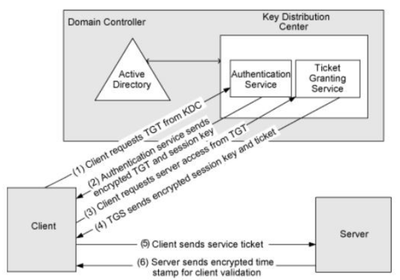
En el pasado artículo os hablé de la autenticación en SQL Server y profundizamos en los protocolos NTLM y Kerberos que se usan para la autenticación con usuarios de Directorio Activo. Cuando hablamos de Kerberos, os comenté que pese a ser un sistema más rápido y seguro que NTLM necesita de más configuraciones. En concreto comentamos los Service Principal Names (SPN) que es en lo que vamos a profundizar hoy. Un SPN mal configurado puede desencadenar una serie de problemas, desde forzar el uso de NTLM hasta errores de autenticación. Por ello, comprender en detalle cómo funciona Kerberos en combinación con SQL Server, y más específicamente, cómo configurar adecuadamente los SPN, es fundamental para cualquier DBA.
¿Qué es un SPN y por qué es importante en SQL Server?
Los Service Principal Names, son identificadores únicos que permiten a los ordenadores localizar un servicio específico dentro de una red. Si llevamos esto a SQL Server, el SPN actúa como un enlace entre una instancia de SQL Server y su identidad en la red, permitiendo a los clientes autenticarse correctamente mediante Kerberos. En escenarios de autenticación Kerberos, el SPN se registra en el Active Directory y se asocia a la cuenta de servicio que ejecuta SQL Server. Esta configuración asegura que Kerberos pueda autenticar correctamente a los usuarios que intentan conectarse a la base de datos. De lo contrario, los usuarios podrían enfrentar errores de autenticación que, en el mejor de los casos, causan inconvenientes, y en el peor, generan brechas de seguridad. Si el SPN no está configurado correctamente, el proceso de autenticación podría revertir al protocolo NTLM, que es menos seguro y menos eficiente que Kerberos.
Configuración de SPN
Configurar correctamente los Service Principal Names es esencial para garantizar la autenticación Kerberos en SQL Server. En primer lugar, es necesario identificar bajo qué cuenta se ejecuta el servicio SQL Server, ya que el SPN debe registrarse en el Active Directory bajo esa cuenta específica.
Un detalle muy importante que no podemos pasar por alto es que un SPN debe ser único en todo el dominio. Si dos servicios diferentes compartieran el mismo SPN, tendríamos fallos en la autenticación que además, por experiencia propia os lo digo, son muy difíciles de diagnosticar y solucionar. Para evitar estos conflictos, se recomienda utilizar el comando setspn -L para listar los SPN actuales y verificar la ausencia de duplicados antes de crear un nuevo SPN.
Configurar SPN para SQL Server
Cuando vamos a registrar un servidor SQL Server es crucial que el SPN se registre tanto para el nombre del servidor como para su FQDN (Fully Qualified Domain Name). Esto asegura que, independientemente de cómo se conecten los clientes al servidor (mediante el nombre corto o el FQDN), la autenticación Kerberos se realice sin problemas. La sintaxis básica para registrar un SPN para SQL Server es la siguiente y nos servirá tanto para la instancia por defecto del servidor:
setspn -S MSSQLSvc/servidor:puerto dominio\cuentaServicio
setspn -S MSSQLSvc/servidor.dominio.com:puerto dominio\cuentaServicioPodríamos usar el parámetro -A para crear los Service Principal Names pero yo personalmente prefiero usar -S en el comando setspn ya que verifica automáticamente si el SPN ya existe, previniendo registros duplicados.
Creación de SPN en Instancias Nombradas de SQL Server
Cuando trabajamos con instancias con nombre de SQL Server, la creación de SPN requiere un enfoque ligeramente diferente al de las instancias predeterminadas. Las instancias nombradas utilizan un puerto dinámico por defecto, lo que puede complicar la configuración del SPN. Para facilitar la gestión y evitar problemas de autenticación, deberemos asignar un puerto fijo a la instancia nombrada. Una vez hecho esto, para la configuración del SPN seguiremos un procedimiento similar al de una instancia predeterminada pero, registrando también los Service Principal Names con el nombre de la instancia.
Supongamos que tenemos una instancia con nombre de SQL Server llamada «SQLInstancia» que se ejecuta en el servidor «servidorSQL» con el puerto fijo 1436. El SPN se configuraría de la siguiente manera:
setspn -S MSSQLSvc/servidorSQL:1436 dominio\cuentaServicio
setspn -S MSSQLSvc/servidorSQL.dominio.com:1436 dominio\cuentaServicio
setspn -S MSSQLSvc/servidorSQL:SQLInstancia dominio\cuentaServicio
setspn -S MSSQLSvc/servidorSQL.dominio.com:SQLInstancia dominio\cuentaServicioRealmente podríamos dejar el puerto dinámico por defecto y registrar el SPN solo por el nombre pero, no soy partidario de ello. Este método que os acabo de enseñar nos asegura que la autenticación Kerberos funciona correctamente independientemente de si la conexión se realiza por nombre de la instancia o por el puerto.
Eliminación de SPN
Eliminar un SPN incorrecto o redundante es una operación delicada, pero a veces necesaria para resolver conflictos o corregir configuraciones. Si detectamos que un SPN fue registrado incorrectamente, o si estamos migrando un servicio y necesitamos limpiar los registros antiguos, podemos utilizar el comando setspn -D para borrar los registros de SPN.
Por ejemplo, si necesitamos eliminar un SPN registrado para una instancia predeterminada en el servidor «servidorSQL», el comando sería:
setspn -D MSSQLSvc/servidorSQL:1433 dominio\cuentaServicioO bien, para eliminar un SPN de una instancia con nombre:
setspn -D MSSQLSvc/servidorSQL\SQLInstancia dominio\cuentaServicioEs importante tener precaución al usar el comando setspn -D, ya que eliminar un SPN incorrectamente puede llevar a problemas de autenticación, especialmente en entornos de producción. Antes de realizar la eliminación, es recomendable listar todos los Service Principal Names registrados con setspn -L cuentaServicio para confirmar que estamos eliminando el SPN correcto.
Además, cuando eliminemos un SPN debemos gestionarlo cuidadosamente, asegurándonos de que el servicio no se quede sin SPN registrado, lo que podría causar fallos en la autenticación de los usuarios y, por tanto, afectar a la disponibilidad del servicio.
SPN para Otros Servicios de SQL Server
Además de las instancias del motor de base de datos de SQL Server, otros servicios de SQL Server, como SQL Server Reporting Services (SSRS), SQL Server Analysis Services (SSAS) y SQL Server Integration Services (SSIS), también requieren la configuración de SPN para soportar la autenticación Kerberos. Aunque su uso está disminuyendo en favor de Power BI y otras herramientas nuevas en la nube como Fabric aún es común encontrarse con instalaciones locales de estos servicios que tendremos que administrar. Cada uno de estos servicios tiene sus propios requisitos y consideraciones para la correcta configuración de SPN. Vamos a ver cómo configurar los Service Principal Names para cada uno de estos servicios.
SQL Server Reporting Services (SSRS) y Power BI Report Server (PBIRS)
SQL Server Reporting Services (SSRS) es un servicio que se utiliza para generar, administrar y entregar informes a través de una interfaz web. De la misma manera y sobre esa base existe un servicio local de Power BI Server para publicar informes llamado Power BI Report Server (PBIRS). Para asegurar que las conexiones a SSRS y PBIRS se autentiquen correctamente mediante Kerberos, debemos registrar un SPN para el servicio HTTP que utilizan.
Supongamos que un SSRS o PBIRS está configurado en un servidor llamado «servidorSQL» con el nombre de instancia «Reportes» y está accesible a través de HTTP. Los Service Principal Names se configuran de la siguiente manera:
setspn -S HTTP/servidorSQL dominio\cuentaServicio
setspn -S HTTP/servidorSQL.dominio.com dominio\cuentaServicioIMPORTANTE: Además del registro de Kerberos en SSRS deberemos habilitar esta conexión en el fichero de configuración «RsReportServer.config». Para ello nos aseguraremos de añadir (o que esté añadida) la palabra clave «<RSWindowsNegotiate>» como primera entrada en el apartado «<AuthenticationTypes>«.
Consideraciones Adicionales para HTTPS
Si SSRS o PBIRS están configurados para utilizar HTTPS, la configuración del SPN no cambia en cuanto a la necesidad de registrar los Service Principal Names para el servicio HTTP. Sin embargo, es crucial que el certificado SSL esté correctamente configurado y que el nombre del certificado coincida con el nombre de host utilizado para acceder al servidor. Esto asegura que la autenticación Kerberos funcione sin problemas en un entorno seguro.
Configuración para Entornos con Nombres de Alias o CNAME
En algunos escenarios, es posible que PBIRS esté configurado para acceder a través de un nombre de alias o un CNAME, lo cual es común en configuraciones de alta disponibilidad o cuando se utiliza un balanceador de carga. En estos casos, también debemos registrar un SPN para el alias o CNAME, de manera que las autenticaciones se gestionen correctamente:
setspn -S HTTP/aliasPBIRS dominio\cuentaServicio
setspn -S HTTP/aliasPBIRS.dominio.com dominio\cuentaServicioEsto asegura que cualquier solicitud de autenticación Kerberos que se realice a través del alias sea manejada adecuadamente, previniendo errores de autenticación que podrían derivar en problemas de acceso a los informes.
SQL Server Analysis Services (SSAS)
SQL Server Analysis Services (SSAS) es un servicio que proporciona herramientas de bases de datos tabulares y de cubos para análisis y minería de datos. Para SSAS, el SPN debe registrarse para el servicio «MSOLAPSvc.3». Si, por ejemplo, tenemos una instancia de SSAS llamada «Analisis» en el servidor «servidorSQL», los Service Principal Names se configurarán de la siguiente manera:
setspn -S MSOLAPSvc.3/servidorSQL:puerto dominio\cuentaServicio
setspn -S MSOLAPSvc.3/servidorSQL.dominio.com:puerto dominio\cuentaServicioSi SSAS utiliza un puerto predeterminado o fijo, ese puerto debe incluirse en el SPN. Es importante verificar el puerto en uso antes de registrar el SPN para evitar errores en la configuración.
SQL Server Integration Services (SSIS)
SQL Server Integration Services (SSIS) no requiere típicamente la configuración de un SPN, ya que SSIS es más comúnmente utilizado en el contexto de ejecución local de paquetes. Sin embargo, si SSIS está configurado para ejecutar paquetes en un servidor remoto y queremos o necesitamos usar la autenticación Kerberos, necesitaremos registrar un SPN para el servicio de agente de SQL Server.
El SPN para SQL Server Agent, que es responsable de ejecutar trabajos que pueden incluir paquetes SSIS, se configuraría de la siguiente manera para una instancia predeterminada en «servidorSQL»:
setspn -S SQLServerAgent/servidorSQL dominio\cuentaServicio
setspn -S SQLServerAgent/servidorSQL.dominio.com dominio\cuentaServicioSQL Server Browser Service
SQL Server Browser Service es el servicio responsable de enrutar las solicitudes de conexión a la instancia correcta de SQL Server en servidores que ejecutan múltiples instancias. Aunque no es común, si necesitamos configurar Kerberos para este servicio, el SPN se registraría así:
setspn -S MSOLAPDisco\servidorSQL dominio\cuentaServicio
setspn -S MSOLAPDisco\servidorSQL.dominio.com dominio\cuentaServicioEste SPN permitiría que el SQL Server Browser Service maneje correctamente las conexiones basadas en Kerberos, asegurando la autenticación en entornos con múltiples instancias o nombres de alias.
Mantenimiento de SPN
El mantenimiento continuo de los Service Principal Names es tan importante como su configuración inicial. Debemos estar atentos a cualquier cambio en la infraestructura, como la migración de SQL Server a un nuevo servidor, el cambio de cuentas de servicio o la actualización del nombre del dominio, ya que estos eventos pueden requerir una actualización de los SPN correspondientes.
Es recomendable establecer procedimientos regulares de monitorización para asegurar que los SPN siguen registrados correctamente. Si detectamos un problema de autenticación que sugiere un fallo en Kerberos, el primer paso que debemos realizar es verificar el estado de los Service Principal Names.
Herramientas como klist o el ya mencionado comando setspn pueden ser útiles para diagnosticar problemas de tickets Kerberos. Del mismo modo, el visor de eventos de Windows puede proporcionarnos detalles adicionales sobre fallos de autenticación que nos ayudarán a diagnosticar los problemas.
En caso de encontrarnos con un SPN duplicado o incorrecto, la solución pasa por eliminar el registro incorrecto utilizando el comando setspn -D, como ya hemos visto, y, acto seguido, registrar de nuevo el o los SPN correctos. Esta intervención debe realizarse con cuidado, ya que eliminar un SPN sin registrar el nuevo puede resultar en una pérdida de conectividad con el servicio SQL Server.
SPN y Always On
En entornos de alta disponibilidad, como los clusters de failover de SQL Server o las configuraciones Always On, la gestión de los Service Principal Names se vuelve aún más compleja. En estos escenarios, los SPN deben configurarse no sólo para la instancia de SQL Server, sino también para el nombre del recurso del clúster o el listener de Always On.
Por ejemplo, en un entorno Always On, los SPN deben registrarse tanto para cada réplica como para el listener. Esto garantiza que, en caso de failover, los clientes puedan seguir conectándose al servicio SQL Server utilizando Kerberos, sin experimentar interrupciones. El manejo incorrecto de los Service Principal Names en estos entornos puede provocar fallos en la autenticación y en la conmutación por error, por lo que es esencial prestar mucha atención en estos casos.
Conclusión
Los SPN de Kerberos son un componente crítico en la infraestructura de autenticación de SQL Server. Su correcta configuración y mantenimiento nos aseguran que los entornos de base de datos funcionan de manera segura y eficiente. A medida que la complejidad de nuestras infraestructuras crezca, es fundamental que prestemos atención a los detalles de configuración de SPN, especialmente en entornos de alta disponibilidad.
Un SPN mal configurado no solo puede comprometer la seguridad, sino que también puede afectar negativamente el rendimiento y la disponibilidad de nuestros servicios. Por lo tanto, debemos abordar la gestión de SPN con el mismo rigor y precisión que aplicamos a otros aspectos de la administración de bases de datos. Al hacerlo, garantizaremos que SQL Server siga siendo un pilar confiable en nuestras infraestructuras críticas.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
No te vayas aun. Hemos creado una página donde estamos recopilando todos estos artículos que dan respuesta a estas preguntas frecuentes de SQL Server. Pásate por aquí a echar un vistazo.