Continuamos con los artículos sobre Power BI Report Server, ya hemos visto tanto sus características principales como los consejos de implantación y mantenimiento y hoy, y para cerrar esta semana temática, vamos a hablar de buenas prácticas. Lo primero que tenemos que recordar es que Power BI Report Server (PBIRS) está construido sobre la base de SQL Server Reporting Service (SSRS), una herramienta de reporte de BI de Microsoft con más de 15 años en el mercado. Con esto quiero decir que la mayoría de las cosas que vamos a ver ahora os sonarán familiares si ya habéis administrado SSRS pero si no es así no os preocupéis que para eso lo vamos a ver.
Configuración avanzada de Report Server
Cuando instalamos PBIRS tendremos a nuestra disposición una herramienta de configuración calcada a la de SSRS donde podremos realizar las configuraciones más básicas de este servicio. Sin embargo, esto no es todo,habrá aspectos que configuraremos en el propio servicio web y otros, los más avanzados, para los que necesitaremos un SSMS. Y, en concreto, son tres de estas configuraciones de las que vamos a hablar en este apartado. Configuraciones que, para la mayoría de las empresas pueden funcionar pero, para otras igual no tanto.
Para acceder a estas configuraciones nos conectaremos a nuestro PBIRS desde nuestro Management Studio (SSMS) usando la opción de conexión a SQL Server Reporting Service (SSRS). Una vez conectados abriremos las propiedades de la instancia y accederemos a las propiedades avanzadas. Aquí, entre otras, podremos encontrar la siguientes configuraciones:
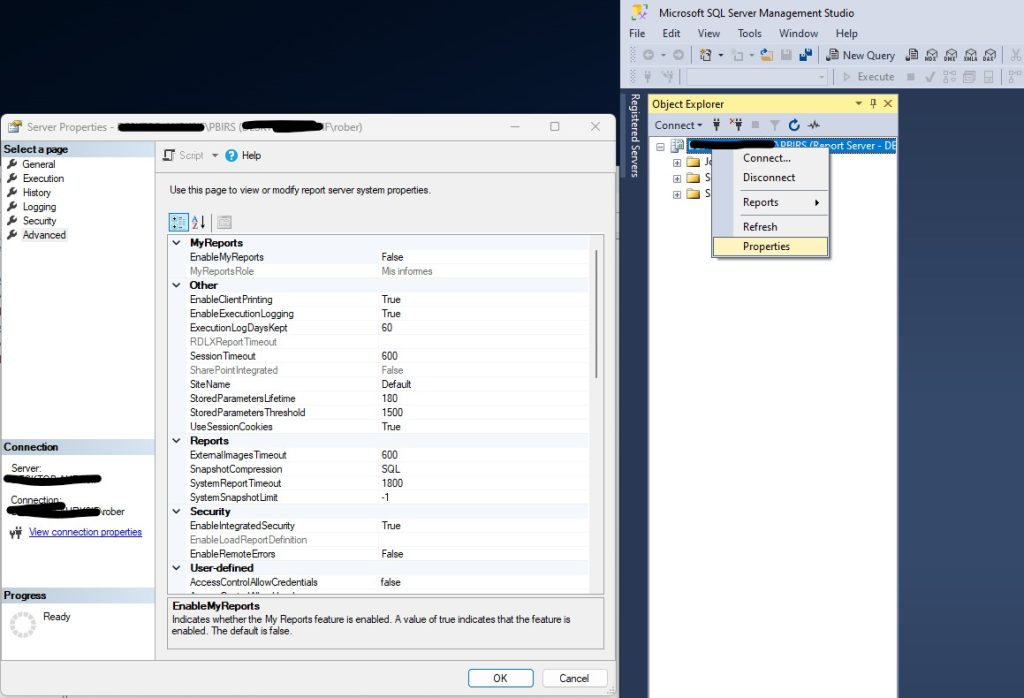
EnableMyReports
La configuración “Enable and disable My Reports» nos permite a los administradores activar o desactivar la funcionalidad de «Mis informes». Esta función, desactivada por defecto, ofrece a los usuarios la posibilidad de crear un espacio personal dentro del servidor donde pueden guardar y gestionar sus propios informes. Esto es similar al concepto Mi espacio de trabajo que tienen los usuarios dentro del servicio Power BI. Habilitar Mis informes es una excelente manera de fomentar la BI de autoservicio y puede ser beneficioso para fomentar la personalización y la autonomía de los usuarios, permitiéndoles trabajar de manera más eficiente sin sobrecargar los espacios compartidos del servidor. No obstante, dejarlo desactivado puede ser preferible en entornos donde la uniformidad y el control sobre los informes es una prioridad.
ExecutionLogDaysKept
ExecutionLogDaysKept es otra configuración importante que define cuántos días se conservan los registros de ejecución de informes en el servidor. Estos logs son fundamentales para el análisis de rendimiento y la solución de problemas, ya que contienen información detallada sobre cada ejecución de informes. Ajustar esta configuración nos permite a los administradores balancear entre la retención de información suficiente para análisis detallados y la gestión eficiente del espacio de almacenamiento. Por defecto esta propiedad está establecida en 60 días, un periodo de retención más largo puede ser útil para auditorías y análisis históricos, sobre todo si tienes informes que se ejecutan sólo una vez al mes o menos. Por otro lado, un periodo más corto puede ayudar a optimizar el rendimiento del servidor.
EnablePowerBIReportExportUnderlyingData
Por último, la configuración EnablePowerBIReportExportUnderlyingData controla si los usuarios tienen permiso para exportar los datos subyacentes de los informes de Power BI. Esta opción es crucial para mantener la seguridad y privacidad de los datos. Permitir la exportación puede ser necesario para usuarios que requieran analizar la información fuera de la plataforma, pero también puede suponer un riesgo si los datos son sensibles. Por ello, esta configuración debe ser ajustada con cuidado, asegurando que solo los usuarios adecuados tengan acceso a esta funcionalidad y que se cumplan las políticas de seguridad de la organización.
Si me preguntáis por mi opinión, yo soy totalmente partidario de deshabilitar esta opción. Además, un abuso de la descarga de información en horas de mucha actividad de usuarios puede suponernos un verdadero quebradero de cabeza.
Seguridad a nivel de carpetas en Report Server
Llegamos a una de las principales diferencias entre Power BI Report Server y el servicio en la nube de Power BI. Mientras en el cloud tenemos Workspaces que sirven como entornos aislados colaborativos para que los equipos desarrollen contenido de Power BI al unísono. Después creamos aplicaciones para facilitar la entrega del contenido a los usuarios. Estos conceptos no existen en Power BI Report Server. En PBIRS tendremos que usar carpetas.
Las carpetas dentro de Power BI Report Server (y SSRS) se comportan como carpetas dentro de un sistema de archivos. La seguridad a nivel de carpeta se puede aplicar para restringir el acceso a todo el contenido de la carpeta. Además, al igual que un sistema de archivos, se puede crear una jerarquía de carpetas. Esto es diferente a la naturaleza aplanada de App Workspaces dentro del servicio Power BI.
Gestión de los permisos
Estemos alojando informes en el servicio o en PBIRS, debemos realizar una planificación cuidadosa desde el principio para proteger adecuadamente su contenido. Normalmente, tiene sentido crear carpetas para diferentes departamentos o equipos de la empresa como, por ejemplo, ventas, contabilidad, marketing, etc…
Aunque en Power BI Report Server (PBIRS), también podemos definir la seguridad en elementos individuales (por ejemplo, un único informe), normalmente no es una práctica. En implementaciones grandes, podemos encontrarnos con decenas o cientos de informes y mantener individualmente los permisos sería una pesadilla. Del mismo modo tenemos que huir de los permisos a usuarios individuales y, siempre que sea posible, utilizar grupos de usuarios. Si llevamos esto a rajatabla, podremos proteger múltiples informes relacionados y habilitar su uso para un subconjunto de usuarios sin complicaciones.
En la mayoría de los casos, también recomiendo que os ciñais a una estructura de carpetas plana. De este modo, no solo será más fácil proteger las carpetas, también PBIRS coincidirá lógicamente con la estructura plana de Workspaces en el servicio Power BI. Esto nos facilitará la tarea de migración o transferencia del contenido de Power BI Report Server (PBIRS) al servicio Power BI en la nube si alguna vez queremos hacerlo.
Reutilizar un modelo de datos en Report Server
Una de las limitaciones de Power BI Report Server (PBIRS) frente al servicio de Power BI en la nube es la capacidad de utilizar un mismo modelo de datos para diferentes informes. Así, mientras que en Power BI en la nube todos nuestros informes pueden acceder a un mismo modelo, si tenemos 12 informes que usan el mismo modelo de datos, en Power BI Report Server (PBIRS) tendremos que mantener 12 copias del modelo de datos. Esto, no hace falta que os lo diga, es un problema a la hora de actualizar los modelos y puede generar una discrepancia de datos entre los informes, que, en el mejor de los casos, nos provocará una reprimenda por parte de los usuarios.
Sin embargo, nosotros que somos DBAs y sabemos de bases de datos y, sobre todo, de servicios de SQL Server, sabemos que podemos aprovecharnos de las capacidades de SQL Server Analysis Services para almacenar nuestras bases de datos dimensionales y, desde los informes de Power BI simplemente acceder a ese único origen de datos compartido para todos los reportes.
Analysis Services es una excelente opción si ya tenemos una inversión en SQL Server y sus componentes de BI, que la tendremos si hemos licenciado PBIRS con la licencia de SQL Server Enterprise. Sin embargo, si estamos implementando Power BI Report Server gracias al licenciamiento de Power BI Premium, también podemos aprovechar los conjuntos de datos que residen en la capacidad Premium como modelos de datos reutilizables.
Podemos establecer una conexión desde nuestros informes de Power BI a un conjunto de datos Premium como si fuera un modelo de Analysis Services. Para ello, debemos asegurarnos de que nuestra capacidad Premium tenga habilitada la lectura en la configuración del extremo XMLA.
Conclusión
En resumen, Power BI Report Server (PBIRS) es una herramienta muy potente, que, si se configura y gestiona adecuadamente, puede convertirse en un pilar fundamental para la inteligencia de negocio en tu organización. Desde la configuración avanzada para habilitar funciones como «Mis informes» o controlar la exportación de datos subyacentes, hasta la gestión cuidadosa de la seguridad a nivel de carpetas y la reutilización de modelos de datos, podemos optimizar cada aspecto de PBIRS para alinearlo con las necesidades y políticas de nuestra empresa. Implementar estas buenas prácticas no solo mejorará el rendimiento y la seguridad de nuestro entorno de reportes, sino que también facilitará futuras migraciones al servicio Power BI en la nube, asegurándonos que nuestra infraestructura de BI está preparada para el crecimiento y el cambio.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!