Hoy os he creado un video tutorial detallado sobre cómo usar la función MERGE en T-SQL. He intentado que el video sea una buena herramienta tanto para los principiantes que buscáis entender los fundamentos de MERGE, como para profesionales de SQL que deseen refrescar sus conocimientos.
En este video, desgloso los conceptos fundamentales de la función MERGE y te muestro cómo puedes utilizarla para combinar datos de dos tablas en SQL Server. Aprenderás a realizar operaciones de inserción, actualización y eliminación en una sola instrucción, lo que te permitirá manejar tus datos de manera más eficiente.
Casos de uso de MERGE
Además de enseñarte cómo usar MERGE, déjame contarte algunos escenarios comunes en los que la función MERGE puede serte especialmente útil. Principalmente la vas a usar para sincronización de tablas (como hemos visto en el video), actualización de datos basada en condiciones específicas o la combinación de datos de múltiples fuentes. Al entender estos casos de uso, podrás ver el verdadero poder de MERGE y cómo puede facilitar tu trabajo con SQL Server con un código más limpio y más eficiente.
Espero que te haya gustado el video, si es así por favor, deja tu me gusta y suscríbete al canal que nos ayuda mucho. Si quieres ver más videos como este puedes encontrarlos todos aquí. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram al que te puede unir. En este grupo estamos creando una comunidad de usuarios y administradores de SQL Server donde cualquiera pueda preguntar sus dudas y compartir sus casos prácticos para que todos seamos mejores profesionales. ¡Hasta la próxima!
En esta ocasión vengo a explicaros como puedes hacer para reducir el espacio que ocupan nuestras bases de datos liberando el espacio libre que hay en los ficheros. Para ello, tendremos que hacer un Shrink de los ficheros de base de datos. Tendrás que hacerlo tanto en el ficheros de datos como en el de log (o en el que sepamos que existe un problema).
Evita siempre que puedas la operación de reducir de ficheros, sobre todo en los ficheros de datos, ya que consume muchos recursos del servidor y además va a empeorar el rendimiento de nuestra base de datos. Si no queda más remedio o si has eliminado tanta información que merezca la pena hacerlo, ten la precaución de programarlo fuera de horas de trabajo y de reconstruir los índices fragmentados una vez termines.
En los ficheros de log, como en los de TempDB no vas a tener los problemas de fragmentación pero si de consumo de recursos por lo que aunque no tengamos que ser tan estrictos si debemos intervenir con la debida precaución.
Puedes encontrar los script que he usado en el video aquí. Espero que te haya gustado el video, si es así por favor, deja tu me gusta y suscríbete al canal que nos ayuda mucho. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram al que te puede unir. En este grupo estamos creando una comunidad de usuarios y administradores de SQL Server donde cualquiera pueda preguntar sus dudas y compartir sus casos prácticos para que todos seamos mejores profesionales. ¡Hasta la próxima!
Cuando trabajamos con bases de datos SQL Server, los bloqueos pueden ser una de las características de implementación que más dolores de cabeza nos pueden dar como DBAs. A los usuarios también, por supuesto, pero ellos trasladarán sus quejas a nosotros.
Por esto, en el vídeo de hoy, te enseño a detectar bloqueos en SQL Server o Azure SQL. Gracias a procedimientos integrados de sistema como sp_who o sp_who2 podremos verlo de una forma muy básica. Si queremos más nivel de detalle podremos recurrir a procedimientos de terceros como sp_who3, sp_whoisactive o sp_BlitzWho.
Si queremos detectar un bloqueo de una forma rápida y ligera, los procedimientos de sistema sp_who y sp_who2 son un gran aliado. Sin embargo, la información que nos van a mostrar es más bien justa. Si tenemos ocasión, siempre será recomendable de recurrir a procedimientos más completos como los citados en el vídeo.
También podremos hacer uso del siguiente script que nos muestra los procesos con bloqueos:
SELECT
DB_NAME(sp.dbid) as [DBname],
sp.spid,
CASE
WHEN (ecid > 0) THEN 'Parallel process, false alert'
ELSE ''
END as 'Parallel?',
blocked,
loginame,
hostname,
program_name,
cmd,
st.text as SQL,
sp.status,
login_time,
last_batch,
GETDATE() as [current_time],
waittime,
lastwaittype,
waitresource
FROM sys.dm_exec_requests er
CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) st
JOIN sys.sysprocesses sp
ON er.session_id = sp.spid
WHERE blocked <> 0
OR spid IN (SELECT blocked FROM sys.sysprocesses)
Como ves, el script hace uso de las vistas de administración dinámica de sistema sys.dm_exec_request y sys.sysprocesses para localizar los bloqueos. Además de la función sys.dm_exec_sql_text para devolver el texto de la consulta que está ejecutando esa sesión. En determinadas ocasiones, dependiendo del bloqueo, es posible que este script no resuelva debido a la función. En esos casos comenta esa parte del código para por lo menos localizar los bloqueos.
Espero que te haya gustado el video, si es así por favor, deja tu me gusta y suscríbete al canal que nos ayuda mucho. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram al que te puede unir. En este grupo estamos creando una comunidad de usuarios y administradores de SQL Server donde cualquiera pueda preguntar sus dudas y compartir sus casos prácticos para que todos seamos mejores profesionales. ¡Hasta la próxima!
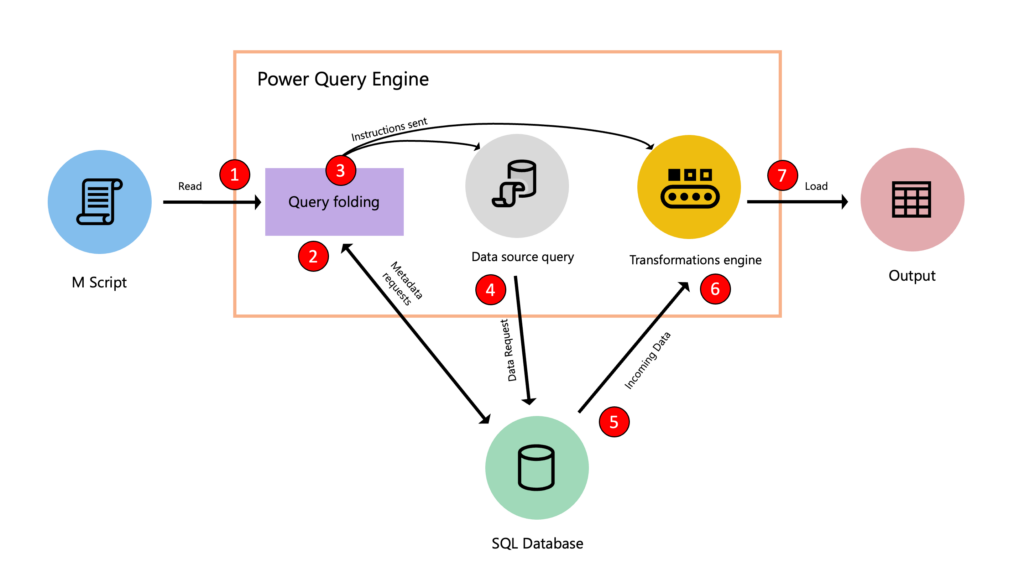
Si ya has trabajado alguna vez con Power BI, sobre todo si te has interesado por su rendimiento, te sonará el concepto plegado de consultas (query folding en inglés). Este concepto es clave en el rendimiento de power BI y sin embargo a mucha gente se le escapa o no lo comprende muy bien. Hoy, voy a intentar arrojar algo de luz sobre este tema de manera sencilla y para todos los públicos aunque, ya os adelanto que el tema da para mucho y si os interesa al final del artículo os dejo alguna recomendación extra para continuar aprendiendo.
¿Qué es el plegado de consultas?
Empecemos por el principio, el plegado de consultas, o “Query Folding”, es un proceso por el cual el motor de Power Query (mashup engine) intenta llevar a cabo la mayor cantidad de transformaciones de datos posible en los sistemas de origen origen, en lugar de hacerlo después de que los datos se hayan cargado en la memoria. Esto puede resultar en una mejora significativa del rendimiento de Power BI, especialmente cuando se trabaja con grandes volúmenes de datos.
¿Qué es Power Query?
¡Quieto Roberto! A más de uno le acaba de volar la cabeza con el párrafo anterior. He introducido el concepto Power Query sin explicaros lo que es, perdonadme. Power Query es una característica de Power BI que cumple las funciones de ETL (extraer, transformar y cargar datos). Gracias al motor mashup engine es capaz de extraer datos de varios orígenes, transformar lo que sea necesario y por último cargarlos en un destino. Principalmente vamos a poder encontrar esta función en Power BI, en los flujos de datos de Power BI (dataflows) y en Microsoft Excel 2016 o superiores. Adicionalmente vamos a poder usar Power Query en Excel 2010 y 2013 si descargamos e instalamos manualmente el componente.
¿Cómo funciona el plegado de consultas?
Cuando creamos una consulta con lenguaje M en Power Query, estamos definiendo una serie de pasos para obtener y transformar nuestros datos. Estos pasos pueden incluir filtrado, agrupación, unión de tablas, entre otros. Idealmente, queremos que estos pasos se realicen en el origen de los datos. Esto es lo que se conoce como plegado de consultas y se podrá llevar a cabo en la mayoría de los casos si los orígenes admiten lenguaje SQL y, siempre y cuando, la instrucción M se traduzca en una sola select con funciones que existan en el lenguaje SQL.
Power Query recibe el script en código M desde el editor avanzado.
El mecanismo de plegado de consultas envía una consulta de metadatos al origen de datos para evaluar sus características.
El mecanismo de plegado de consultas determina qué información extraer del origen de datos y qué conjunto de transformaciones deben producirse dentro del motor de Power Query.
Power Query consulta el origen de datos mediante una consulta nativa.
El origen de datos devuelve los datos al motor de Power Query.
Una vez que los datos están en Power Query, el motor de transformación de Power Query (también conocido como motor de mashup) realizará las transformaciones que no se pudieron plegar ni descargar en el origen de datos.
Carga en el modelo de Power BI (o en excel) de los datos extraídos y transformados.
¿Por qué es importante?
El plegado de consultas es especialmente útil cuando trabajamos con grandes conjuntos de datos. Al realizar las transformaciones en el origen de los datos, reducimos la cantidad de datos que necesitamos cargar en la memoria, lo que puede resultar en un rendimiento significativamente mejorado. Si por ejemplo solo necesitamos unas pocas filas y columnas de la tabla de origen, gracias al plegado de consultas no vamos a tener que traer todos los datos para luego filtrarlos. Igualmente si, podemos realizar las uniones entre tablas, agregaciones y ordenados en el origen (que está optimizado para ello) es trabajo que le quitamos a nuestro Power BI.
Tiene otras ventajas, como que Power BI optimizará en gran medida las cargas incrementales de los datos cuando las consultas son 100% plegables ya que si no habría que leer todo el origen y cargarlo en memoria para que el mashup engine cribe las filas nuevas de las ya existentes.
¿Cómo saber si se está realizando el plegado de consultas?
Power Query Dataflows proporciona indicadores visuales que nos permiten saber si se está realizando el plegado de consultas. Estos indicadores se encuentran en la ventana de Power Query y nos muestran qué pasos se están plegando a través de iconos. Esto está muy bien resumido en la documentación oficial así que os dejo directamente el extracto.
En Power BI Desktop no va a ser tan sencillo verlo como mirar los iconos al lado de los pasos de la transformación, sin embargo, eso no significa que no podamos verlo. Simplemente con hacer clic derecho sobre el paso y verificar si nos está ofreciendo ver la consulta nativa podremos saber si se mantiene o no el plegado de consultas.
Andrés en nuestro grupo de Telegram añade:«Otra de las formas de saber si el plegado se mantiene, es con la función Value.Metadata (tabla). Devuelve información sobre si existe o no el plegado. Del mismo modo, podemos usar una instrucción para mantener el plegado, es con la función Value.NativeQuery() y con el parámetro EnableFolding=true. Esto nos permitirá enviar una consulta directa a SQL Server, mantener el plegado y poder seguir realizando pasos que mantengan el plegado. El problema es que cuando escribes directamente la consulta desde el conector a SQL Server, la consulta ya no seguirá plegando de ahí en adelante. Por suerte, la función Value.NativeQuery(…), si nos permite esto.«
Niveles de plegado de consulta
Como hemos visto a lo largo de este artículo, existen ciertas operaciones de transformación de datos incompatibles con el plegado de consultas. A esto se le llama romper el plegado de consultas y deberemos evitarlo en la medida de lo posible. Aun así, esto no quiere decir que la consulta ya no se vaya a plegar por tener un paso incompatible, la optimización del motor de Power Query sabrá plegar todos los pasos posibles y solo efectuar en el motor de transformaciones lo estrictamente necesario. En este sentido, nos vamos a encontrar con tres niveles de plegado de consultas:
Plegado de consultas completo: Todas las transformaciones de consulta se delegan en el origen de datos. El motor de Power Query realiza un procesamiento mínimo y muy eficiente.
Plegado parcial de consultas: Una parte de las transformaciones de la consulta, y no todas, se pueden delegar en el origen de datos. En este caso, una parte de las transformaciones las realiza el origen de datos y el resto se producen en el motor de transformaciones de Power Query.
Sin plegado de consultas: La consulta no se puede plegar. Normalmente contiene transformaciones que no se pueden traducir al lenguaje de consulta nativo del origen de datos, ya sea porque las transformaciones no son compatibles o porque el conector no admite el plegado de consultas. En este caso, Power Query obtiene los datos sin procesar del origen de datos y utiliza el motor de Power Query para lograr los datos deseados mediante el procesamiento de las transformaciones necesarias a nivel del motor de Power Query.
Conclusión
El plegado de consultas es un concepto complejo pero crucial para el rendimiento en Power BI. Si trabajas a menudo con Power Query dedica tiempo a entender en profundidad esta funcionalidad y así mejorar considerablemente tus resultados. Por mi parte no me queda más que, como os había prometido al inicio, recomendaros el libro “Power BI Dataflows” de Francisco Mullor para convertiros en unos verdaderos maestros de la herramienta. Si solo os interesa este tema que hemos tratado hoy o si queréis usarlo como aproximación al libro, Fran ha publicado el capítulo dedicado al plegado de consultas de manera que está accesible de manera gratuita aquí. También podéis pasar por la academia virtual de Alex Ayala donde encontraréis cursos de Power BI de gran calidad.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Continuamos con los videos de T-SQL avanzado con los modificadores WITH CUBE y WITH ROLLUP. Estos son modificadores de la cláusula GROUP BY. Gracias a WITH CUBE vamos a poder totalizar nuestras agrupaciones junto a los resultados de nuestras consultas y con WITH ROLLUP podremos ver solo totales agrupados por varios campos.
Al igual que comentamos en nuestro anterior video de T_SQL Avanzado el uso de este tipo de consultas en vistas que luego se consumirán desde Power BI nos va a evitar caer en el error de romper el plegado de consultas. También vamos a conseguir con una sola consulta los resultados que, de otra manera, necesitaríamos por lo menos dos consultas, con el doble de lecturas sobre los datos y, por tanto, con mayor consumo de recursos.
Espero que te haya gustado el video, si es así por favor, deja tu me gusta y suscríbete al canal que nos ayuda mucho. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram al que te puede unir. En este grupo estamos creando una comunidad de usuarios y administradores de SQL Server donde cualquiera pueda preguntar sus dudas y compartir sus casos prácticos para que todos seamos mejores profesionales. ¡Hasta la próxima!
Os voy a contar un caso real. Hace años, trabajando yo en un cliente, empezamos a notar una degradación de rendimiento en determinadas operaciones sobre la base de datos. Pero solo pasaba con las consultas que se ejecutaban desde determinados paquetes SQL Server Integration Services (SSIS). Antes de que podáis pensar que esas consultas no estaban optimizadas os diré que lo estaban, las mismas consultas ejecutadas directamente contra la base de datos funcionaban. Entonces, el problema tenía que estar en SSIS.
La siguiente prueba fue validar la ejecución de un paquete manualmente desde visual estudio y uno ya desplegado en el catálogo.El primero de ellos funcionaba como se esperaba mientras que el ya desplegado tardaba mucho más. ¿Qué estaba pasando? Pues no me enrollo más.
El problema era el mantenimiento (concretamente la falta de mantenimiento) en la base de datos del catálogo SSIS, la SSISDB. Además todo esto se agravaba debido a una mala elección en el nivel de detalle de los logs que deja el catálogo de SSIS.
¿Qué es la SSISDB?
Como hemos dicho, la SSISDB es la base de datos del catálogo de SQL Server Integration Services. En ella se van a desplegar los paquetes, va a almacenar todos sus metadatos (proyectos, entornos, parámetros, etc…) y, además, todo el historial de ejecuciones.
¿Qué mantenimiento necesita la SSISDB?
Como toda base de datos en SQL Server, las tablas sufren variaciones que conlleva fragmentación de los índices. Por este motivo, como cualquier otra base de datos, vamos a tener que implementar un mantenimiento de índices y de estadísticas de las tablas. Además, aunque algunos datos son fácilmente recuperables desplegando de nuevo los proyectos, por seguridad debemos programar chequeos de integridad y copias de seguridad frecuentes.
Mantenimientos específicos de SSISDB
Vale, la SSISDB necesita el mismo mantenimiento que el resto de mis bases de datos pero, además de los mantenimientos de una base de datos normal, existen una serie de consideraciones específicas que debemos tener en cuenta. Como hemos visto, entre otras cosas esta base de datos almacena el historial de ejecuciones de nuestros paquetes y, como todas las tablas de log, estas deben ser purgadas regularmente.
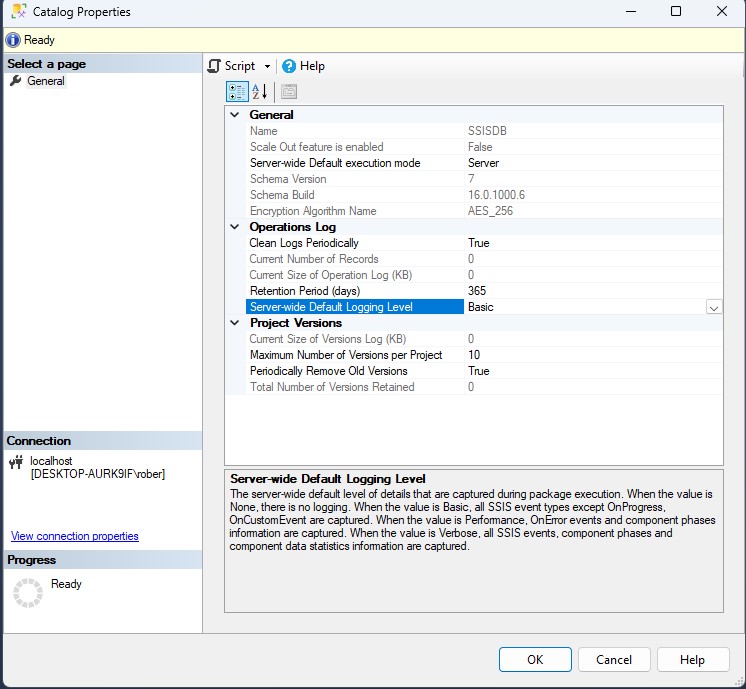
Si accedemos a las propiedades de nuestro catálogo de SSIS vamos a ver que por defecto está habilitada la limpieza de registros antiguos de log con un periodo de retención de un año. Pero, ¿realmente necesitamos un año de log? Para mi la respuesta es no. Y es que yo siempre hablo con mis clientes y nunca hemos considerado necesario más de una semana o un mes a lo sumo. Otra de las opciones que vamos a encontrar en este apartado es el nivel de log que se va a almacenar pero, esto es más extenso y luego volvemos sobre ello.
Antes de meternos de lleno con el nivel de log vamos a ver otra de las opciones de purgado de datos que podemos encontrar en las propiedades del catálogo, el número de versiones de los proyectos. El catálogo de SSIS por defecto almacena un máximo de 10 versiones por proyecto y va limpiando las anteriores. Esta cantidad puede ser correcta o no para ti, valora con el equipo de desarrolladores de los paquetes y ten en cuenta si ya existe otro control de versiones a nivel de desarrollo como un Git.
Nivel de log de SSIS
Como hemos visto antes, el nivel de registro de SSIS es una característica que nos permite a los administradores de bases de datos elegir el nivel de verbosidad del log de ejecuciones de los paquetes SSIS almacenados en el catálogo de integration services. Por defecto consta de cuatro niveles que son Ninguno, Básico, Rendimiento y Detallado.
Ninguno: Como su nombre indica, este nivel no registra ninguna información. Es útil cuando se tiene confianza en el rendimiento del paquete y no se requiere seguimiento.
Básico:Este es el nivel predeterminado y proporciona suficiente información para entender el flujo de ejecución y solucionar problemas comunes.
Rendimiento: Este nivel está diseñado para registrar información que ayuda a solucionar problemas de rendimiento. Registra sólo los eventos necesarios para proporcionar información sobre el rendimiento.
Detallado: Este nivel registra información detallada sobre la ejecución del paquete. Aunque puede ser útil para solucionar problemas complejos, también puede generar una gran cantidad de datos de registro.
Bajo mi punto de vista, y siendo totalmente sincero con vosotros, ninguno de estos 4 niveles se adapta a las necesidades reales de un entorno de producción. No registrar eventos es un peligro y no seríamos capaces de depurar un error, el nivel básico (el predeterminado) almacena demasiada información inutil (he visto hasta reportes de cientos de hojas para una única ejecución de un paquete). Lo mismo me pasa con el nivel de rendimiento que, me da datos que no necesito en mi dia a dia de un servidor productivo. El detallado es para ni plantearselo, para mi, solamente tiene sentido en un servidor de pruebas si estás depurando la ejecución de los paquetes.
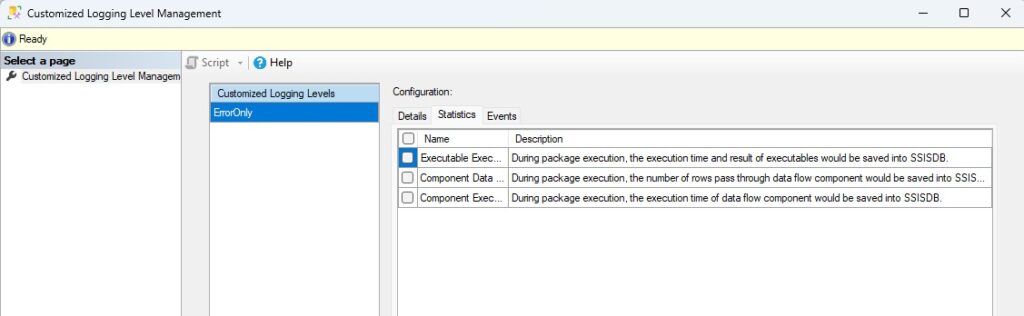
Por suerte para nosotros, existe la posibilidad de crear un nivel de registro personalizado solo con los eventos y las estadísticas que queramos ver. En mi caso, acostumbro a crear un nivel “Solo Errores” que es lo único que me interesa en la mayoría de los casos.
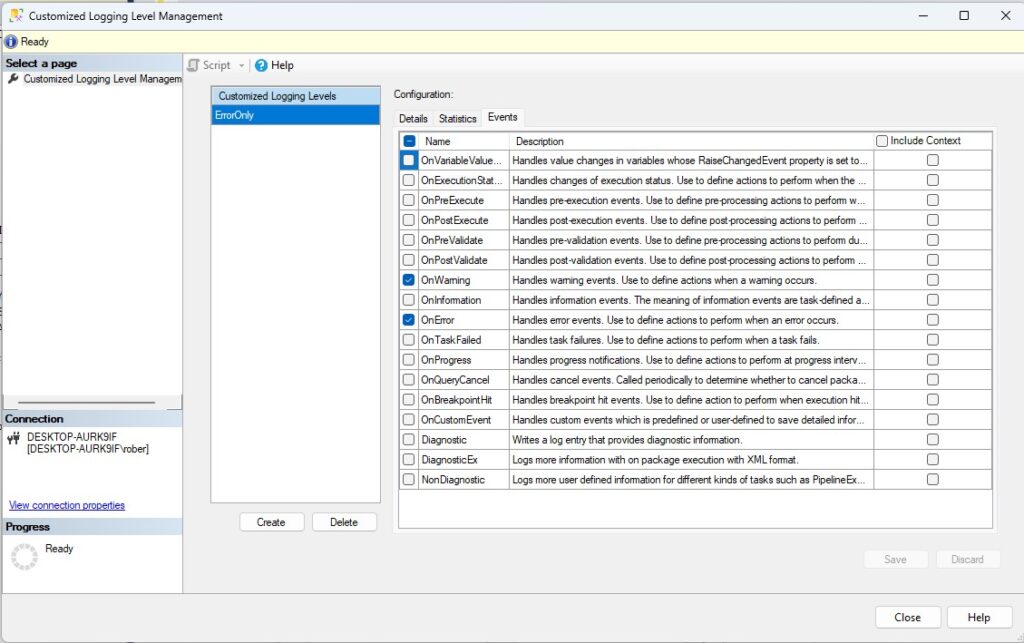
Niveles de log personalizados en SSIS
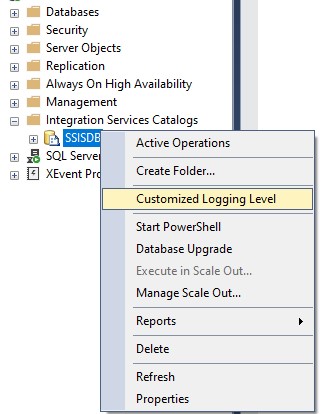
Para crear un nivel de log personalizado lo primero que haremos será acceder a la opción dedicada a este fin en el menú contextual que se abre al hacer clic derecho sobre nuestro catálogo. En la ventana que se nos abrirá podremos crear uno o varios niveles personalizados. En las imágenes os muestro como lo suelo hacer yo.
Una vez creado el nivel personalizado, iremos a las propiedades del catálogo y lo configuraremos como nivel por defecto. Esto hará que todos los nuevos jobs que creemos para ejecutar los paquetes o todas las nuevas ejecuciones manuales de este paquete se hagan bajo este nivel de registro. Sin embargo, todos los jobs que ya existieran antes de cambiar el nivel de log seguirán con el antiguo nivel por defecto (básico si no lo habíais cambiado) por lo que habrá que cambiarlos a mano.
Cambiar el nivel de log para los jobs de SSIS existentes
Uno que ya es perro viejo pero sobre todo es vago, no suele estar por la labor de cambiar cosas a mano en todos los jobs. Sobre todo en entornos donde la cantidad de paquetes es elevada por este motivo tengo una manera de proceder para automatizar el proceso. Os detallo los pasos.
Elijo un paso de un job de ejemplo.
Localizo el paso seleccionado en la tabla msdb.dbo.sysjobstesps y copio el campo command.
Cambio a mano el nivel de log para ese paso.
Vuelvo a la tabla msdb.dbo.sysjobstesps y copio nuevamente el campo command.
Creo un script para reemplazar en todos los pasos tipo ‘SSIS’ los cambios que he observado en el campo.
Por ejemplo:
UPDATE msdb.dbo.sysjobsteps SET command = REPLACE(command, '$ServerOption::LOGGING_LEVEL(Int16)\"";1 ','$ServerOption::LOGGING_LEVEL(Int16)\"";100 /Par "\"$ServerOption::CUSTOMIZED_LOGGING_LEVEL\"";ErrorOnly ') WHERE subsystem='SSIS'
Conclusión
Una buena gestión y administración de nuestro catálogo SSIS es crucial para su futuro rendimiento. Dedica el tiempo que necesites a estas optimizaciones, los usuarios lo van a agradecer. Por otro lado, puede ser interesante configurar niveles con más detalle de log en tus servidores de pruebas para facilitar el debugueado a los desarrolladores. Solo tu conoces tu entorno, comentalo con los usuarios y, seguro, conseguirás el equilibrio perfecto.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Hace aproximadamente un año, Jose Manuel Jurado publicó este artículo en el blog de Microsoft. La verdad es que cuando lo vi me resultó curioso pero no le di mayor importancia, será porque no estaba yo tan enamorado como ahora de las bondades de query store. El caso es que parece que el artículo se me quedó grabado aunque nunca había vuelto a él ni lo había puesto en práctica. Y digo esto porque esta semana, hablando con mis compañeros de trabajo sobre los eventos extendidos y explicándoles cómo xEvents ampliaba con creces las características de SQL Server Profiler, les comenté que podrías crear una sesión que solo capture eventos que desencadenen cierto error.
Esto no es nuevo para vosotros, ya lo vimos aquí. Entonces se me encendió la bombilla y volvió a mi el artículo de José Manuel, ¿y si capturamos con eventos extendidos las consultas con advertencias en sus planes de ejecución?
Por qué xEvents para localizar advertencias
Como os he dicho, la idea de esta solución es una mezcla de curiosidad y mini-reto personal. Sin embargo, se me ocurre que puede ser una solución ideal para varios escenarios gracias a la capacidad de eventos extendidos de activar y desactivar la captura de datos a nuestra voluntad. Esto lo hace ideal para capturar eventos contenidos en el tiempo que nosotros hayamos localizado un problema. Tampoco vamos a necesitar en estos casos el historial de planes de ejecución como nos ofrece Query Store.
Capturando advertencias de conversión con eventos extendidos
Como algunos ya sabéis, un error de conversión de datos puede generar dos tipos de problema: errores de cardinalidad o errores en el plan de búsqueda. Es común que sean ambos pero, vamos a partir de la misma premisa del escenario original y vamos a capturar solo los warning de conversión del tipo “seek plan” o errores en el plan de búsqueda. Además vamos a añadir un par de filtros extra como limitar la captura a sesiones con un session ID mayor de 50 para evitar procesos de usuario y a limitarlo a las bases de datos con un ID mayor que 4 para evitar las bases de datos internas de SQL.
CREATE EVENT SESSION [Convert Warnings] ON SERVER ADD EVENT sqlserver.plan_affecting_convert( ACTION(sqlserver.database_name,sqlserver.is_system,sqlserver.sql_text,sqlserver.username) WHERE ([package0].[greater_than_uint64]([sqlserver].[session_id],(50)) AND [package0].[equal_uint64]([convert_issue],'Seek Plan') AND [sqlserver].[database_id]>(4))) ADD TARGET package0.event_file(SET filename=N'Convert Warnings') WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON) GO
Y aquí lo podéis ver en funcionamiento:
¿Y el resto de advertencias?
Ahora que hemos visto que mi idea original es viable, ¿por qué quedarnos aquí? Ya vimos en el post sobre planes de ejecución que existen más tipos de advertencias en los planes de ejecución. ¿Y si hacemos una sesión que capture todos esos tipos de alertas? Pues sí mis queridos lectores, claro que os voy a enseñar esto también, ya sabéis que no soy yo de conformarme con poco. Tras indagar un poco en todas las posibles advertencias de planes de ejecución que podemos capturar con xEvents he creado esta sesión que vamos a repasar ahora juntos:
CREATE EVENT SESSION [WARNINGS] ON SERVER ADD EVENT sqlserver.hash_warning( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))), ADD EVENT sqlserver.missing_column_statistics( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))), ADD EVENT sqlserver.missing_join_predicate( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))), ADD EVENT sqlserver.plan_affecting_convert( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))), ADD EVENT sqlserver.sort_warning( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))), ADD EVENT sqlserver.unmatched_filtered_indexes( ACTION(sqlserver.sql_text,sqlserver.username) WHERE (([sqlserver].[session_id]>(50)) AND ([sqlserver].[database_id]>(4)))) ADD TARGET package0.event_file(SET filename=N'WARNINGS') WITH (STARTUP_STATE=ON) GO
Aquí podemos ver varios eventos todos ellos relacionados con advertencias en los planes de ejecución entre los que encontramos:
Hash_warning: Este tipo de advertencia nos indica que la operación hash ha usado más memoria de la disponible y ha tenido que escribir datos en el disco.
Missing_column_statistics: Veremos esta advertencia cuando una consulta accede a una columna que no tiene estadísticas disponibles que podrían haber sido útiles para la optimización de consultas.
Missing_join_predicate: Se produce cuando una consulta ejecutada no tiene un predicado de combinación.
Plan_affecting_convert: Este es el caso que hemos visto en el escenario anterior, hay un error de conversión afectando al plan de ejecución.
Sort_Warning: Indica que la operación de ordenación ha usado más memoria de la disponible y ha tenido que escribir datos en el disco.
Unmatched_filtered_indexes: Este error es causado cuando SQL Server no puede hacer uso de un índice filtrado debido a que la consulta está parametrizada. Y si, esta es una de las limitaciones de SQL Server que más quebraderos de cabeza nos pueden dar.
Además, para cada uno de los eventos se han aplicado los mismos filtros de session ID y Database ID del escenario anterior.
Conclusión
Ya sea con query store como hizo Jose Manuel o con eventos extendidos como hemos visto aquí localizar las consultas con advertencias en sus planes de ejecución para luego arreglar el problema nos ayudará a mejorar el rendimiento de nuestro servidor y a no malgastar recursos. No cometas el error que cometí yo y no esperes un año para ponerte a buscar proactivamente este tipo de problemas. Y si se te ocurre otra forma de conseguir lo mismo dejalo en los comentarios o ponte en contacto conmigo para que te publique un artículo sobre el tema, yo estaré encantado de hacerlo. Somos una comunidad y el objetivo es compartir el conocimiento.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Colabora con nosotros
SoyDBA.es es gratis para ti y siempre va a serlo. Sin embargo, a nosotros si que nos cuesta dinero además de mucho esfuerzo. Puedes colaborar con nosotros con un donativo por PayPal o usando nuestros enlaces de afiliado para colaborar sin que te cueste nada. Tenemos enlace de Amazon y de Aliexpress
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.