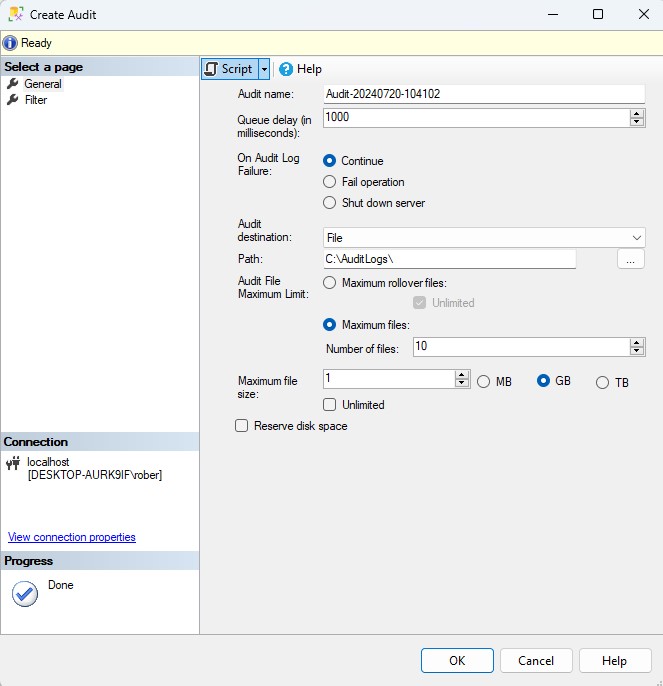
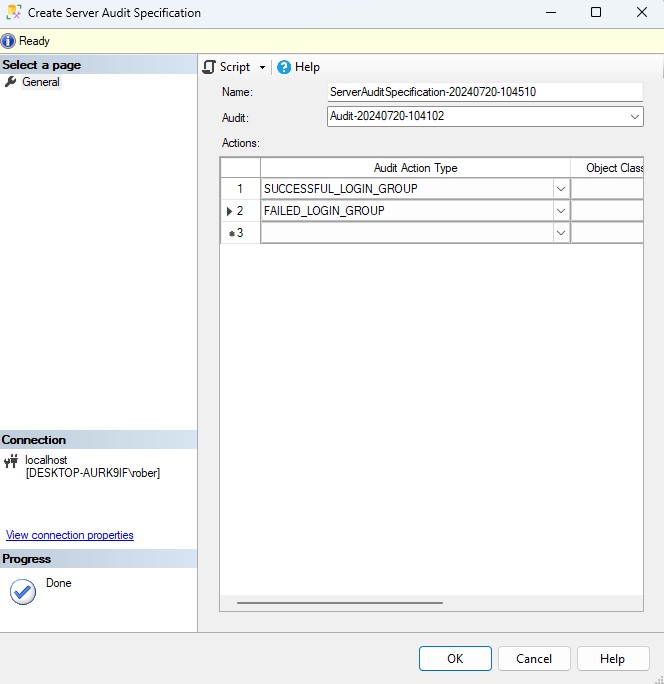
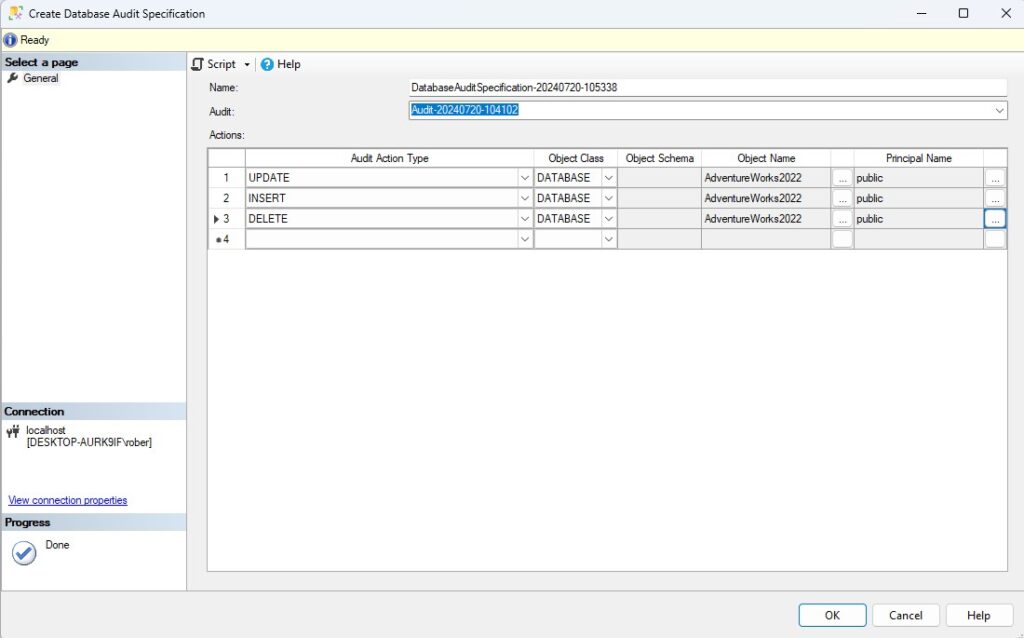
Cuando hablamos de bases de datos, términos como instancia, base de datos (BBDD) y esquema son fundamentales, pero no en todos los sistemas tienen los mismos significados, lo que genera confusión entre los desarrolladores y administradores de bases de datos principiantes. En este artículo, voy a explicarte lo que significan en SQL Server así como las diferencias y relaciones entre estos conceptos tan clave que son el pilar de nuestro RDBMS.
Cuando trabajamos con SQL Server o Azure SQL, es crucial entender cómo están organizados los datos y las estructuras que los contienen. A menudo, los términos «instancia», «base de datos» y «esquema» se utilizan indistintamente, pero cada uno tiene un significado específico y una función distinta. Veamoslo.
¿Qué es una Instancia en SQL Server?
Una instancia de SQL Server es una “copia” del motor de base de datos que se ejecuta como un servicio del sistema operativo. Es la aplicación del servidor SQL instalada en nuestro equipo y podemos tener una o varias instaladas y ejecutándose a la vez. Cada instancia puede contener varias bases de datos y tiene su propia gestión de la memoria, los procesos y su propia configuración.
Tipos de Instancias
Existen dos tipos principales de instancias en SQL Server:
- Instancia predeterminada: Por defecto es la primera instancia instalada en el servidor y no tiene nombre específico. Se accede a ella utilizando sólo el nombre del servidor.
- Instancia con nombre: Se pueden instalar múltiples instancias con nombre en un mismo servidor, y se accede a ellas utilizando el formato Nombre_Servidor\Nombre_Instancia.
Esto no es siempre así, puedes poner un nombre a todas tus instancias o instalar primero una instancia con nombre y después la predeterminada. Lo que sí es importante es que solo puede haber una instancia predeterminada en el servidor y eso se configura al momento de la instalación.
Ventajas y desventajas de Múltiples Instancias
Las múltiples instancias tienen ciertas ventajas, por ejemplo, permiten un mayor aislamiento ya que se pueden separar las cargas de trabajo críticas en diferentes instancias. Esto nos permite una configuración independiente donde cada instancia puede tener su propia configuración de seguridad, memoria y opciones de rendimiento. Además es más sencillo gestionar actualizaciones y parches sin afectar a todas las bases de datos.
Esto no quiere decir que tengamos que tener un solo servidor de SQL con todas las instancias, aunque es una opción válida, todo lo que hemos visto como ventajas es aún mayor cuando tenemos servidores independientes cada uno con una instancia, aunque sean servidores virtuales. Aunque esta solución tiene un mayor coste, a mi es la que más me gusta.
Base de Datos (BBDD)
Una base de datos (BBDD) es una colección organizada de datos que se puede acceder, gestionar y actualizar fácilmente. En SQL Server, cada base de datos es una entidad autónoma que contiene sus propios conjuntos de archivos.Cada base de datos en SQL Server consta de tres tipos principales de archivos: Los archivos de datos primarios (.mdf) que contienen los datos de la base de datos y su estructura, los archivos de datos secundarios (.ndf) utilizados para distribuir datos en diferentes discos y mejorar el rendimiento y los archivos de registro o log de transacciones (.ldf) que almacenan todas las transacciones y cambios a la base de datos, cruciales para la recuperación ante fallos.
Esquemas en SQL Server
Un esquema es un contenedor lógico dentro de una base de datos que agrupa objetos como tablas, vistas, procedimientos almacenados, etc. Ayuda a organizar los objetos y facilita la gestión de permisos y la segmentación de datos.
Los esquemas son extremadamente útiles para la segregación de datos permitiéndonos separar datos y objetos por departamentos o aplicaciones y mejorando así la gestión de la seguridad al aplicar permisos a nivel de esquema en lugar de a nivel de objeto. También son un gran aliado para la organización ya que nos va a permitir mantener un orden lógico y estructurado dentro de una base de datos.
Diferencias Clave entre Instancia, BBDD y Esquema en SQL Server
Para recapitular, y a modo resumen, vamos a destacar las diferencias esenciales entre estos tres conceptos:
- Instancia: Es el entorno de ejecución del motor de base de datos que puede contener múltiples bases de datos. Proporciona aislamiento y configuración independiente.
- Base de Datos (BBDD): Es una colección autónoma de datos y objetos dentro de una instancia. Cada base de datos tiene su propio conjunto de archivos de datos y registro.
- Esquema: Es un contenedor lógico dentro de una base de datos que organiza y agrupa objetos. Facilita la gestión de permisos y la segregación de datos.
Conclusión
Entender las diferencias y relaciones entre instancia, base de datos y esquema es fundamental para cualquier profesional que trabaje con SQL Server o Azure SQL. Desde la gestión de múltiples instancias hasta la organización de datos en esquemas, cada componente tiene su lugar y función específica. Al aprovechar estas herramientas de manera efectiva, podemos garantizar que nuestras bases de datos sean robustas, seguras y escalables, tanto en entornos locales como en la nube.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
No te vayas aun. Hemos creado una página donde estamos recopilando todos estos artículos que dan respuesta a estas preguntas frecuentes de SQL Server. Pásate por aquí a echar un vistazo.