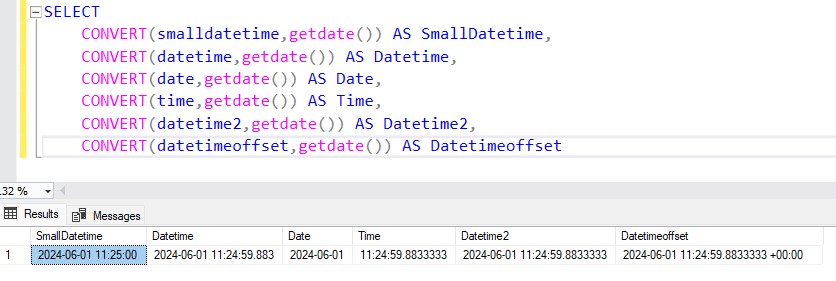
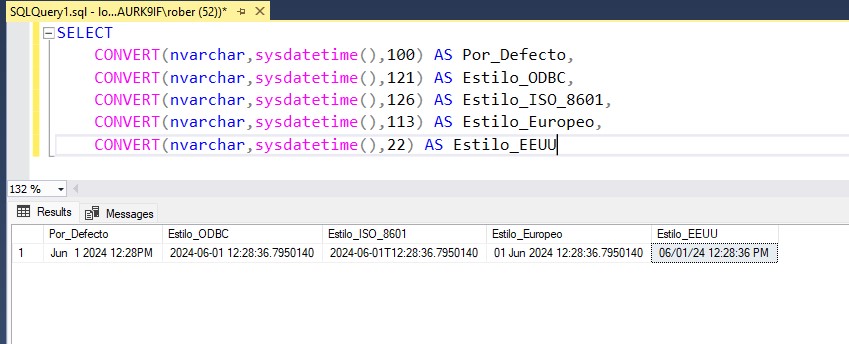
Os voy a contar un caso real. Hace años, trabajando yo en un cliente, empezamos a notar una degradación de rendimiento en determinadas operaciones sobre la base de datos. Pero solo pasaba con las consultas que se ejecutaban desde determinados paquetes SQL Server Integration Services (SSIS). Antes de que podáis pensar que esas consultas no estaban optimizadas os diré que lo estaban, las mismas consultas ejecutadas directamente contra la base de datos funcionaban. Entonces, el problema tenía que estar en SSIS.
La siguiente prueba fue validar la ejecución de un paquete manualmente desde visual estudio y uno ya desplegado en el catálogo.El primero de ellos funcionaba como se esperaba mientras que el ya desplegado tardaba mucho más. ¿Qué estaba pasando? Pues no me enrollo más.
El problema era el mantenimiento (concretamente la falta de mantenimiento) en la base de datos del catálogo SSIS, la SSISDB. Además todo esto se agravaba debido a una mala elección en el nivel de detalle de los logs que deja el catálogo de SSIS.
¿Qué es la SSISDB?
Como hemos dicho, la SSISDB es la base de datos del catálogo de SQL Server Integration Services. En ella se van a desplegar los paquetes, va a almacenar todos sus metadatos (proyectos, entornos, parámetros, etc…) y, además, todo el historial de ejecuciones.
¿Qué mantenimiento necesita la SSISDB?
Como toda base de datos en SQL Server, las tablas sufren variaciones que conlleva fragmentación de los índices. Por este motivo, como cualquier otra base de datos, vamos a tener que implementar un mantenimiento de índices y de estadísticas de las tablas. Además, aunque algunos datos son fácilmente recuperables desplegando de nuevo los proyectos, por seguridad debemos programar chequeos de integridad y copias de seguridad frecuentes.
Mantenimientos específicos de SSISDB
Vale, la SSISDB necesita el mismo mantenimiento que el resto de mis bases de datos pero, además de los mantenimientos de una base de datos normal, existen una serie de consideraciones específicas que debemos tener en cuenta. Como hemos visto, entre otras cosas esta base de datos almacena el historial de ejecuciones de nuestros paquetes y, como todas las tablas de log, estas deben ser purgadas regularmente.
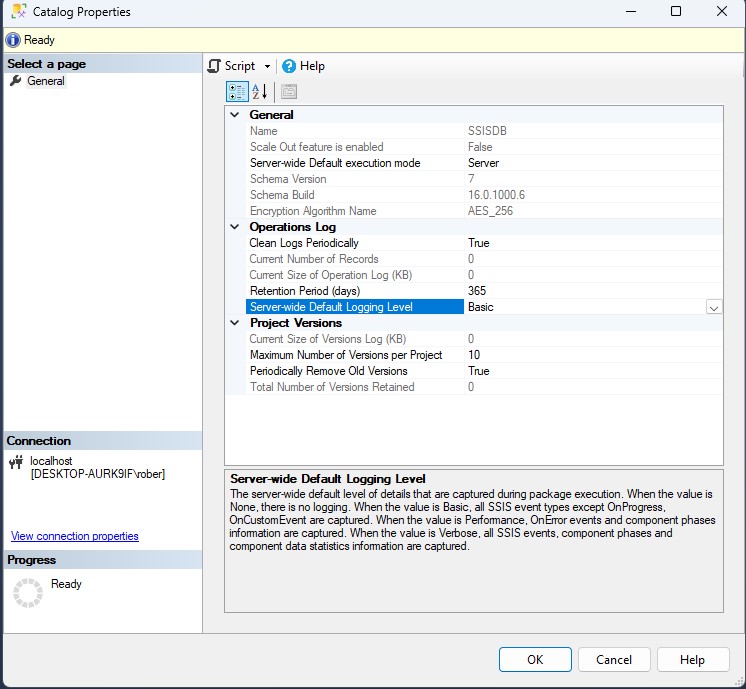
Si accedemos a las propiedades de nuestro catálogo de SSIS vamos a ver que por defecto está habilitada la limpieza de registros antiguos de log con un periodo de retención de un año. Pero, ¿realmente necesitamos un año de log? Para mi la respuesta es no. Y es que yo siempre hablo con mis clientes y nunca hemos considerado necesario más de una semana o un mes a lo sumo. Otra de las opciones que vamos a encontrar en este apartado es el nivel de log que se va a almacenar pero, esto es más extenso y luego volvemos sobre ello.
Antes de meternos de lleno con el nivel de log vamos a ver otra de las opciones de purgado de datos que podemos encontrar en las propiedades del catálogo, el número de versiones de los proyectos. El catálogo de SSIS por defecto almacena un máximo de 10 versiones por proyecto y va limpiando las anteriores. Esta cantidad puede ser correcta o no para ti, valora con el equipo de desarrolladores de los paquetes y ten en cuenta si ya existe otro control de versiones a nivel de desarrollo como un Git.
Nivel de log de SSIS
Como hemos visto antes, el nivel de registro de SSIS es una característica que nos permite a los administradores de bases de datos elegir el nivel de verbosidad del log de ejecuciones de los paquetes SSIS almacenados en el catálogo de integration services. Por defecto consta de cuatro niveles que son Ninguno, Básico, Rendimiento y Detallado.
- Ninguno: Como su nombre indica, este nivel no registra ninguna información. Es útil cuando se tiene confianza en el rendimiento del paquete y no se requiere seguimiento.
- Básico:Este es el nivel predeterminado y proporciona suficiente información para entender el flujo de ejecución y solucionar problemas comunes.
- Rendimiento: Este nivel está diseñado para registrar información que ayuda a solucionar problemas de rendimiento. Registra sólo los eventos necesarios para proporcionar información sobre el rendimiento.
- Detallado: Este nivel registra información detallada sobre la ejecución del paquete. Aunque puede ser útil para solucionar problemas complejos, también puede generar una gran cantidad de datos de registro.
Bajo mi punto de vista, y siendo totalmente sincero con vosotros, ninguno de estos 4 niveles se adapta a las necesidades reales de un entorno de producción. No registrar eventos es un peligro y no seríamos capaces de depurar un error, el nivel básico (el predeterminado) almacena demasiada información inutil (he visto hasta reportes de cientos de hojas para una única ejecución de un paquete). Lo mismo me pasa con el nivel de rendimiento que, me da datos que no necesito en mi dia a dia de un servidor productivo. El detallado es para ni plantearselo, para mi, solamente tiene sentido en un servidor de pruebas si estás depurando la ejecución de los paquetes.
Por suerte para nosotros, existe la posibilidad de crear un nivel de registro personalizado solo con los eventos y las estadísticas que queramos ver. En mi caso, acostumbro a crear un nivel “Solo Errores” que es lo único que me interesa en la mayoría de los casos.
Niveles de log personalizados en SSIS
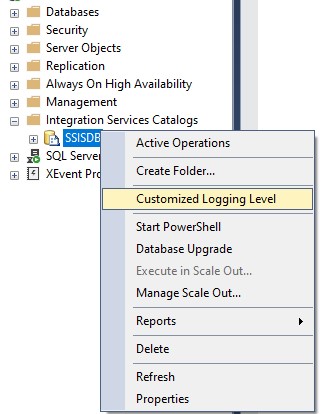
Para crear un nivel de log personalizado lo primero que haremos será acceder a la opción dedicada a este fin en el menú contextual que se abre al hacer clic derecho sobre nuestro catálogo. En la ventana que se nos abrirá podremos crear uno o varios niveles personalizados. En las imágenes os muestro como lo suelo hacer yo.
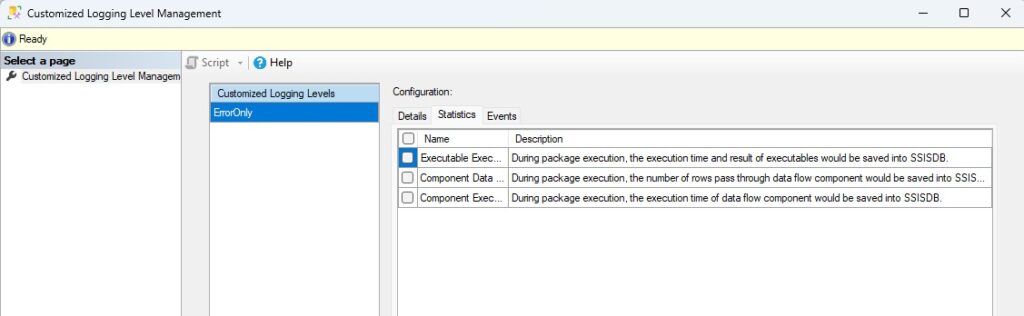
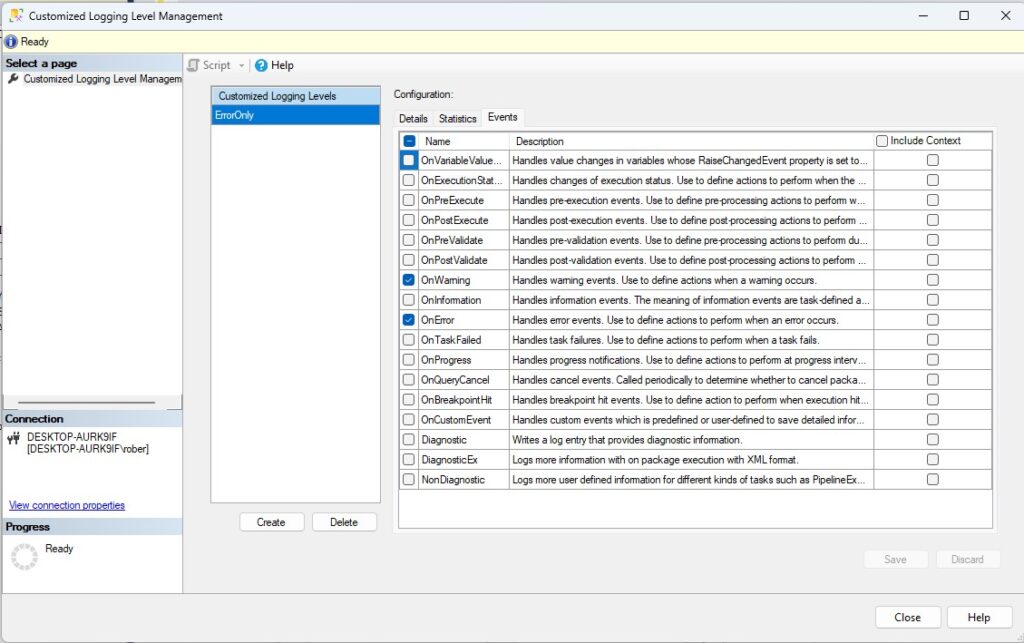
Una vez creado el nivel personalizado, iremos a las propiedades del catálogo y lo configuraremos como nivel por defecto. Esto hará que todos los nuevos jobs que creemos para ejecutar los paquetes o todas las nuevas ejecuciones manuales de este paquete se hagan bajo este nivel de registro. Sin embargo, todos los jobs que ya existieran antes de cambiar el nivel de log seguirán con el antiguo nivel por defecto (básico si no lo habíais cambiado) por lo que habrá que cambiarlos a mano.
Cambiar el nivel de log para los jobs de SSIS existentes
Uno que ya es perro viejo pero sobre todo es vago, no suele estar por la labor de cambiar cosas a mano en todos los jobs. Sobre todo en entornos donde la cantidad de paquetes es elevada por este motivo tengo una manera de proceder para automatizar el proceso. Os detallo los pasos.
- Elijo un paso de un job de ejemplo.
- Localizo el paso seleccionado en la tabla msdb.dbo.sysjobstesps y copio el campo command.
- Cambio a mano el nivel de log para ese paso.
- Vuelvo a la tabla msdb.dbo.sysjobstesps y copio nuevamente el campo command.
- Creo un script para reemplazar en todos los pasos tipo ‘SSIS’ los cambios que he observado en el campo.
Por ejemplo:
UPDATE msdb.dbo.sysjobsteps
SET command = REPLACE(command, '$ServerOption::LOGGING_LEVEL(Int16)\"";1 ','$ServerOption::LOGGING_LEVEL(Int16)\"";100 /Par "\"$ServerOption::CUSTOMIZED_LOGGING_LEVEL\"";ErrorOnly ')
WHERE subsystem='SSIS'Conclusión
Una buena gestión y administración de nuestro catálogo SSIS es crucial para su futuro rendimiento. Dedica el tiempo que necesites a estas optimizaciones, los usuarios lo van a agradecer. Por otro lado, puede ser interesante configurar niveles con más detalle de log en tus servidores de pruebas para facilitar el debugueado a los desarrolladores. Solo tu conoces tu entorno, comentalo con los usuarios y, seguro, conseguirás el equilibrio perfecto.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!