El artículo de hoy va a ser corto pero es muy importante ya que Microsoft ha publicado ayer mismo (al momento de escribir estas líneas) una actualización con un parche de seguridad crítico para SQL Server. Esto me ha llevado a escribir esto y “colarlo” por delante de lo que ya estaba programado en el blog. Vamos a aprovechar esta oportunidad para descubrir todo lo que rodea a las actualizaciones de SQL y que debemos saber y por último ya descubriremos por qué es tan importante esto que os estoy compartiendo justo hoy.
Como ya hemos dicho en muchas ocasiones, en todo lo relacionado con el mundo de la tecnología, el cambio es la única constante. Como profesionales de bases de datos, sabemos que mantener nuestros sistemas actualizados es crucial para garantizar su rendimiento, seguridad y eficiencia y por tanto para desempeñar correctamente nuestro trabajo. En este sentido SQL Server no se queda atrás y se renueva y mejora continuamente con actualizaciones.
¿Qué son las Actualizaciones de SQL Server?
Empecemos por el principio, ¿qué son las actualizaciones de SQL Server? Las actualizaciones de SQL Server son mejoras y correcciones que Microsoft lanza periódicamente para su sistema de gestión de bases de datos, SQL Server. Estas actualizaciones pueden incluir desde parches de seguridad hasta nuevas funcionalidades, pasando por mejoras de rendimiento y solución de incidencias.
Actualizar SQL Server trae consigo una serie de ventajas como ya hemos visto, no solo tendremos una mayor seguridad seguridad sino que se habilitarán nuevas funcionalidades, se mejorará el rendimiento y se solucionarán los errores.
Tipos de actualización de SQL Server
Las actualizaciones de SQL Server se pueden clasificar en dos grandes grupos, y dentro de estos encontraremos varias categorías principales. Como grandes tipos podemos diferenciar las actualizaciones mayores, que implican un cambio de versión y las menores que no implican cambio de versión. Dentro de este último grupo tenemos actualizaciones de Service Packs, Acumulativas y de seguridad.
Actualización Mayor de SQL Server
Las actualizaciones mayores de SQL Server son lanzamientos completos de nuevas versiones del sistema de gestión de bases de datos. Estas actualizaciones suelen incluir una gran cantidad de nuevas funcionalidades, mejoras de rendimiento y seguridad, y a veces cambios en la arquitectura del sistema.
Por ejemplo, SQL Server 2022, que se lanzó en noviembre de 2022, es la versión más reciente hasta la fecha. Esta versión continúa con las mejoras en seguridad y rendimiento, proporcionando una plataforma de datos moderna para escenarios híbridos.
Las actualizaciones mayores también pueden incluir cambios en la compatibilidad con versiones anteriores, por lo que es importante revisar cuidadosamente las notas de la versión antes de actualizar a una nueva versión mayor.
Actualización menor de SQL Server
Además de las actualizaciones mayores Microsoft proporciona un soporte continuo a las versiones de SQL Server que aún están dentro de los plazos de mantenimiento incluyendo las versiones generales de distribución (GDRs), los paquetes de servicio (SPs), y las actualizaciones acumulativas (CUs). Esto es lo que se conoce como actualizaciones menores y también es importante mantenernos al día con ellas.
- Service Packs (SPs): Son colecciones de actualizaciones y correcciones de errores que se lanzan periódicamente. Los SPs suelen incluir todas las actualizaciones acumulativas y parches de seguridad lanzados hasta la fecha de su publicación. Este tipo de actualizaciones no se han vuelto a publicar desde el Service Pack 3 para SQL Server 2016, ninguna de las últimas versiones de SQL Server ha tenido más Service Pack.
- Actualizaciones acumulativas (CUs): Son conjuntos de actualizaciones y correcciones de errores que se lanzan más frecuentemente que los SPs. Las CUs incluyen todas las actualizaciones desde la última CU o SP.
- Parches de seguridad: Son actualizaciones críticas que se lanzan para corregir vulnerabilidades específicas de seguridad detectadas en SQL Server. Son las más importantes y como tal se actualizarán automáticamente desde Windows Update si tenemos marcada la opción de actualizar otros productos de Microsoft. Esto es un arma de doble filo pues la actualización requiere parada del servicio y personalmente no lo recomiendo. Yo prefiero actualizar manualmente los servidores de manera controlada, empezando por entornos de desarrollo y pruebas y terminando por los más críticos de producción.
Configuración de Base de Datos: Query_Hotfixes
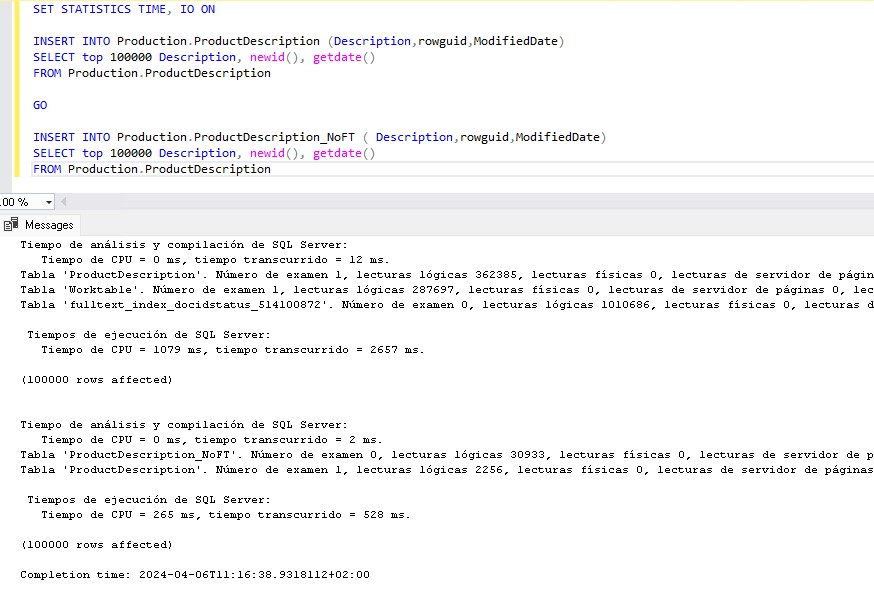
La configuración de alcance de base de datos Query_Hotfixes es una característica introducida en SQL Server 2016. Esta configuración permite habilitar o deshabilitar las correcciones del optimizador de consultas a nivel de base de datos.
Las correcciones del optimizador de consultas son mejoras o cambios en el optimizador de consultas que se introducen en las actualizaciones de SQL Server CU o SP. Antes de SQL Server 2016, para aprovechar estas mejoras, era necesario habilitar la traza 41992. Sin embargo, a partir de SQL Server 2016, estas mejoras se habilitan en la configuración de la base de datos. Para habilitar las correcciones del optimizador de consultas, puedes usar el siguiente comando:
ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES = ON;Este comando configura la base de datos para utilizar todas las correcciones del optimizador de consultas. Es importante recordar que cualquier cambio en esta configuración sólo afectará a la base de datos en la que se ejecuta el comando y que por defecto esta característica viene siempre deshabilitada.
El Último parche GDR: 09/04/2024
El 9 de abril de 2024, Microsoft lanzó una actualización de seguridad para SQL Server 2019 y 2022. Esta actualización resuelve varias vulnerabilidades críticas, en particular en los controladores ODBC y OLE DB de Microsoft para SQL Server. Antes de esta actualización o si aún no la hemos instalado, estas vulnerabilidades podrían permitir la ejecución remota de código. Esto significa que un atacante podría tomar el control de nuestros sistemas, afectando gravemente a la integridad y confidencialidad de la información. Al instalar esta actualización, se protegen los sistemas contra estas amenazas, reforzando la seguridad de nuestras bases de datos.
Es importante destacar que para aplicar esta actualización, debes tener instalado SQL Server 2019 o 2022. Se han publicado los parches para las versiones sin ninguna CU o para los sistemas actualizados a la última CU de cada versión. Es decir tenemos esta actualización GDR para SQL 2019, SQL 2019 CU25, SQL 2022 y SQL 2002 CU 12.
Correciones de este GDR
Esta es la lista de CVEs corregidos en esta actualización:
- CVE-2024-28929 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28930 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28931 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28932 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28933 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28934 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28935 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28936 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28937 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28938 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28941 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28943 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29043 – Microsoft ODBC Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28939 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28940 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28942 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28944 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28945 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28927 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28910 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29044 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28906 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29045 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28908 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29046 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28926 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28909 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29047 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28911 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28912 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28914 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28913 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29048 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29982 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29983 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29984 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-29985 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
- CVE-2024-28915 – Microsoft OLE DB Driver for SQL Server Remote Code Execution Vulnerability
Conclusión
Mantener SQL Server actualizado es una tarea esencial para cualquier profesional de bases de datos. No solo nos ayuda a mantener nuestras bases de datos seguras, sino que también nos permite aprovechar las últimas mejoras y funcionalidades. Así que, recordemos siempre mantener un ojo en las últimas actualizaciones de SQL Server aquí. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
PD: Perdón, al final no ha sido un artículo tan corto como imaginaba pero, ¿qué le vamos a hacer? Son cosas del directo, ya os he contado que esto no estaba pensado.