La primera elección a la que nos vamos a enfrentar cuando vamos a trabajar con SQL Server o una instancia o base de datos de Azure por primera vez es la herramienta que vamos a usar. Existen multitud de soluciones pero las principales, y desarrolladas por Microsoft, para esta tarea son SQL Server Management Studio (SSMS) o Azure Data Studio (aquí no hay siglas, nadie usa ADS). No os dejéis llevar por los nombres, ambas soluciones nos van a permitir conectarnos de la misma manera tanto a SQL Server como a instancias o bases de datos de Azure SQL. Así que, la decisión entre una u otra será por otros aspectos que las diferencian, y eso justo es lo que hoy voy a tratar de aclararos.
¿Qué son SSMS y Azure Data Studio?
SQL Server Management Studio (SSMS) es una aplicación de código cerrado pero gratuita desarrollada por Microsoft para permitir la interacción de usuarios y administradores a las bases de datos SQL Server ya sea en instalaciones On Premise como en la nube de Azure. Además, nos permite conectarnos a otros servicios de la familia de SQL Server como son SSAS, SSRS y SSIS. Gracias a esta herramienta dispondremos de una interfaz gráfica para realizar de manera gráfica cualquier operación que necesitemos sobre SQL Server y sus objetos. Dispondremos también de la posibilidad de generar código para consulta T-SQL, DMX, MDX y DAX.
Azure Data Studio, por su parte, también es una herramienta gratuita de Microsoft pero en este caso es de código abierto. Se basa en Visual Studio Code que a su vez se basa en el Framework Electron. Esto hace que, si quieres, puedas colaborar en el código de Azure Data Studio en GitHub. Si lo comparamos con SSMS estaremos ante una aplicación visualmente más moderna, más ligera y extensible. En el caso de Azure Data Studio, al igual que en Visual Studio Code, podremos instalar componentes ya sean de Microsoft o de terceros para ampliar las funcionalidades que nos ofrece. Por ejemplo, podemos agregar compatibilidad con bases de datos MySQL o PostgreSQL.
Compatibilidad Multiplataforma
SSMS lleva en el mercado desde SQL Server 2005, y aunque ha ido mejorando y añadiendo funcionalidades (ya va por la versión 20.1), en esencia es la misma aplicación Win32 para escritorios Windows. No tiene soporte para MacOS ni para Linux y eso restringe su uso a servidores o estaciones clientes con un sistema operativo Windows.
Azure Data Studio, por el contrario, al estar basado en Visual Studio es multiplataforma y podremos instalarlo en equipos Windows, Linux o Mac (no como SSMS que solo es compatible con Windows).
¿A quién va dirigido SSMS y Azure Data Studio?
SSMS es una aplicación dirigida a desarrolladores SQL Server y administradores de bases de datos o profesionales de sistemas que deban administrar Servidores SQL Server. Incluye todas las opciones de administración de forma gráfica y nos permite adaptar cualquier configuración con unos pocos clics de ratón. Gracias al soporte ampliado de las nuevas versiones, además, vamos a poder administrar de la misma manera Azure Managed Instances, Azure Databases o pools de Azure Synapse SQL. Por último, como ya hemos comentado, también vamos a poder usar SSMS para conectar con SSAS, SSRS y SSIS.
Azure Data Studio, por el contrario, es una aplicación centrada en su uso por profesionales de datos y BI y desarrolladores por lo que prescinde de todas las opciones de administración que nos brinda SSMS. Esto hace que sea una aplicación mucho más ligera como hemos comentado antes. No quiere decir que desde Azure Data Studio no vayamos a poder administrar nuestros servidores, si vamos a poder, simplemente tendremos que hacerlo por comandos T-SQL. Mucho más engorroso, ¿verdad?. Si nos gustase eso administraríamos Servidores Oracle y ganaríamos más dinero. Con Azure Data Studio tendremos la posibilidad de conectarnos a SQL Server On Premise, Azure Database, Azure Managed Instance, Azure Synapse así como a MySQL y a PostgreSQL. Sin embargo, y esto es una cosa que no entiendo, no tiene soporte para bases de datos NOSQL como la propia CosmoDB de Azure.
Características
En cuanto a la comparativa propiamente dicha, como venimos comentando, está entre las funciones que cada una de las aplicaciones nos brinda. Vamos primero a ver las características comunes a ambas aplicaciones y luego sus diferencias. Ambas tienen un editor de consultas que admite T-SQL, DMX, MDX, DAX y XMLA (SSAS) y se apoyan en IntelliSense para facilitarnos la tarea. También disponen de un explorador para visualizar jerárquicamente los objetos que componen nuestra base de datos.
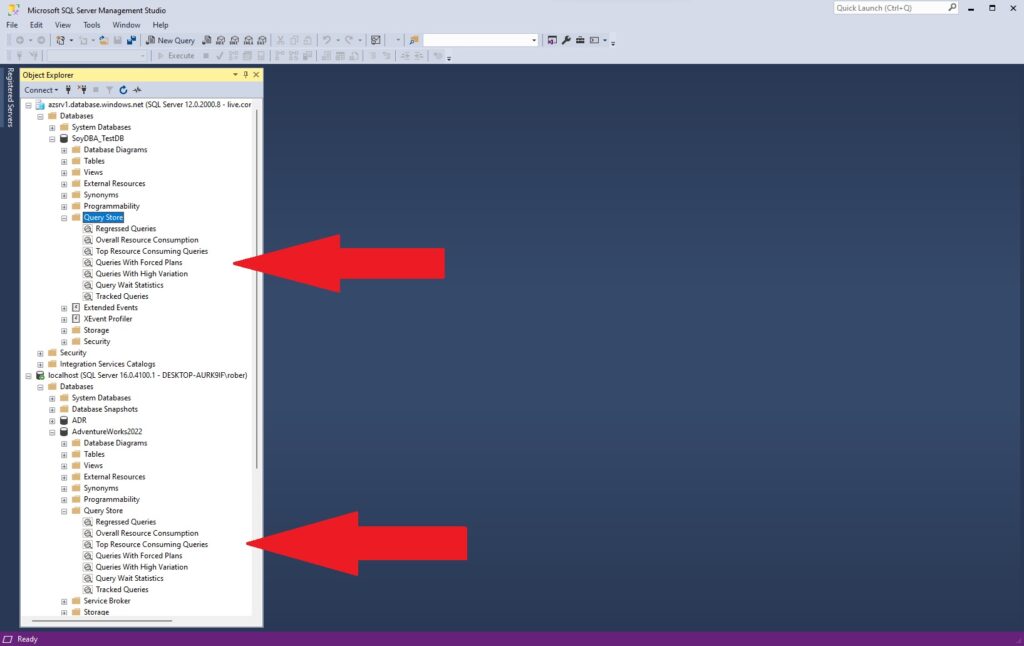
Como diferencias, SSMS dispone de un gran arsenal de herramientas pensadas para administradores y usuarios más avanzados de SQL Server entre las que podemos destacar las relacionadas con la seguridad, el mantenimiento y el Agente de SQL Server. Disponemos también de Query Store y una serie de informes predefinidos para las bases de datos que nos aportarán información muy valiosa.
Azure Data Studio, cuenta en su haber con otras características exclusivas como los cuadernos Jupyter, integración con GitHub y con Copilot y la posibilidad de instalar extensiones. Además soporta los lenguajes de programación Python, R y Scala.
Para cerrar este apartado, quiero destacar la integración entre SSMS y Azure Data Studio. Si disponemos de ambas aplicaciones instaladas, desde SSMS vamos a poder abrir Azure Data Studio directamente para poder trabajar con los cuadernos Jupyter.

Tampoco sería justo dejar de mencionar que, si bien Azure Data Studio no está pensado para administrar servidores, poco a poco se van añadiendo funcionalidades para este fin. En el momento de escribir estas líneas, podemos encontrar cómo Preview funcionalidades avanzadas hasta ahora exclusivas de SSMS.

Conclusión
Azure Data Studio y SSMS son dos poderosísimas herramientas desarrolladas por Microsoft para facilitarnos nuestras interacciones diarias con SQL y Azure. Elegir una u otra dependerá de nuestras necesidades ya que no están pensadas para el mismo público objetivo y por tanto no disponen de exactamente las mismas funcionalidades. En mi caso trabajo siempre con ambas aplicaciones abiertas y depende la tarea que tenga que realizar en ese momento uso la que mejor se adapte. Espero que gracias a este artículo vosotros podáis tomar la mejor decisión informada y veáis cubiertas vuestras necesidades. Como siempre, estamos aquí para ayudarte. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!