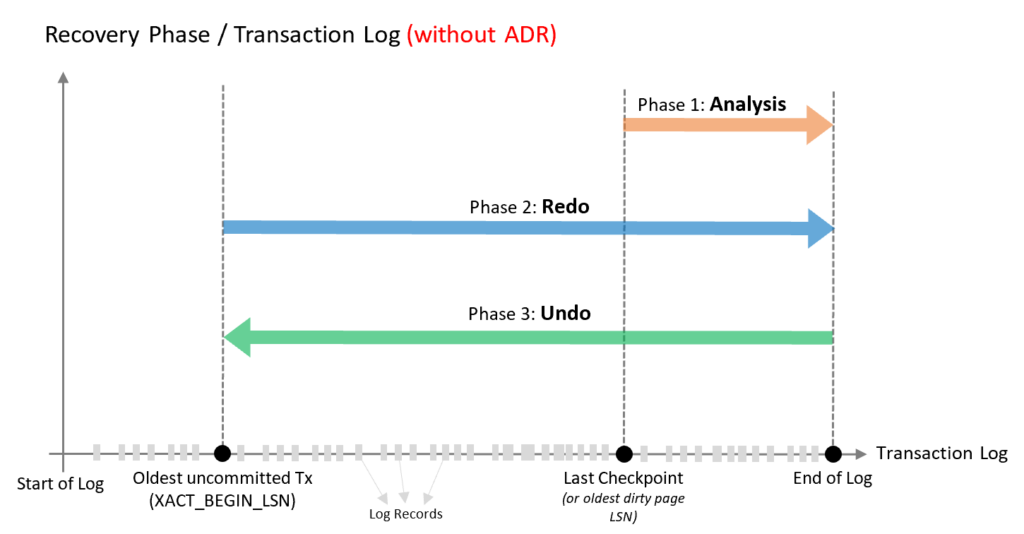
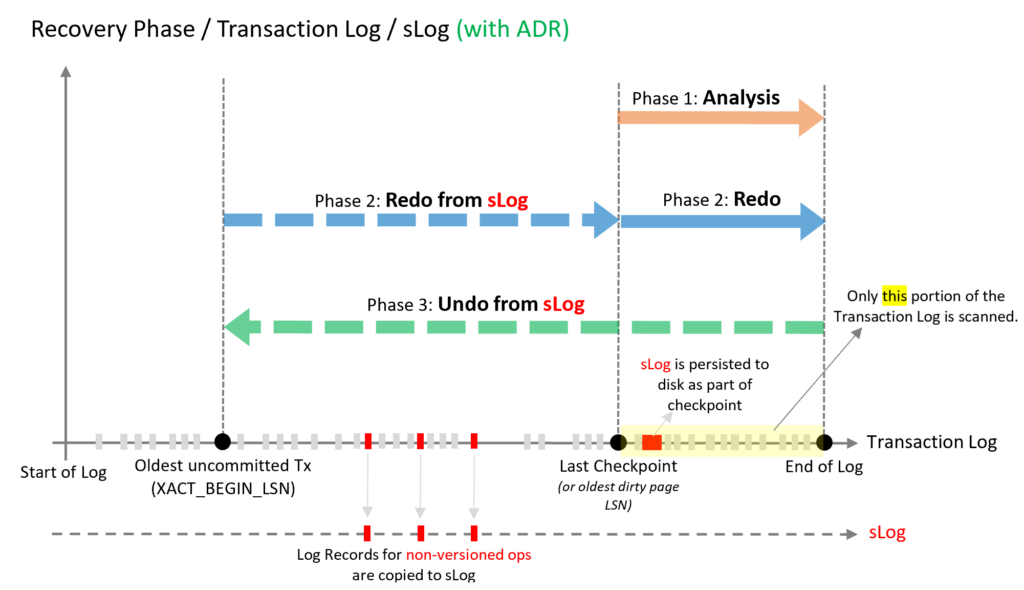
En este artículo vamos a hablar de las causas más comunes de mal rendimiento en consultas de SQL Server y cómo optimizarlas. Sabemos que el rendimiento es un aspecto crítico para cualquier aplicación que utilice una base de datos, y que SQL Server es uno de los sistemas de gestión de bases de datos relacionales más populares y potentes del mercado. Sin embargo, también sabemos que no basta con instalar SQL Server y esperar que todo funcione a la perfección. Hay que tener en cuenta una serie de factores que pueden afectar al rendimiento de las consultas, tanto a nivel de diseño como de implementación y mantenimiento.
Problemas de rendimiento por malas consultas
La forma en la que obtenemos los datos marca directamente el rendimiento de nuestros procesos, dos consultas pueden devolver exactamente el mismo resultado pero una con menos consumo de recursos que la otra. A esto es a lo que vamos a llamar optimizar una consulta. Reescribiremos la consulta evitando las siguientes prácticas en la medida de lo posible:
Funciones
Las funciones son un objeto de base de datos que nos permite encapsular código en un objeto para utilizarlo después simplemente llamando a ese objeto. Sin embargo, de cara al rendimiento pueden generarnos problemas.
Por un lado tenemos las funciones escalares, estas son las más inofensivas en cuanto a rendimiento pero cuidado con usarlas dentro de un filtro del WHERE. Estas funciones impiden que el optimizador de consultas utilice índices y obligan a realizar escaneos completos de las tablas, lo que consume más recursos y tiempo.
El otro tipo de funciones que tenemos en SQL son las funciones de tabla. Las funciones de tabla son objetos que devuelven un conjunto de filas como resultado de una consulta o una expresión. Aunque pueden ser útiles para resolver ciertos problemas complejos o integrar datos heterogéneos, también pueden afectar al rendimiento si no se usan correctamente. Por ejemplo, una función de tabla puede generar una estimación errónea del número de filas devueltas. Además, necesitan ser cargadas completamente en memoria antes de poderse ejecutar. Esto nos puede provocar un plan subóptimo o un desbordamiento de memoria. Y, aun en el caso de que la función se pueda cargar en memoria, la consulta deberá esperar a que se resuelva completamente la consulta antes de seguir con otros componentes.
Cursores o bucles para procesar datos.
Estas técnicas son propias de la programación estructurada y no aprovechan la naturaleza en bloques de SQL Server. Además, generan un mayor número de accesos a disco y bloqueos, lo que reduce el rendimiento y la concurrencia. Para evitarlo, se recomienda utilizar consultas que operen sobre conjuntos de datos en lugar de sobre filas individuales.
Subconsultas
El uso de subconsultas en ocasiones es imprescindible, sin embargo, usarlas en el SELECT o en el WHERE tienen un impacto negativo en el rendimiento. Las subconsultas son consultas anidadas dentro de otras consultas, que pueden devolver uno o varios valores. Aunque pueden ser útiles para resolver ciertos problemas complejos, también pueden afectar al rendimiento si no se usan correctamente. Por ejemplo, una subconsulta correlacionada es aquella que depende del valor devuelto por la consulta principal, lo que implica que se tenga que ejecutar tantas veces como filas devuelva la consulta principal. Esto puede generar un gran consumo de recursos y tiempo. Para evitarlo, se recomienda reescribir la consulta para utilizar JOINs.
Servidores vinculados
Los servidores vinculados son objetos que permiten acceder a datos almacenados en otros servidores mediante consultas distribuidas. Un servidor vinculado puede generar una latencia adicional al tener que comunicarse con otro servidor, lo que puede ralentizar la ejecución de la consulta. Además, nuestro SQL Server desconocerá la estimación de resultados que van a llegarnos del servidor remoto por lo que podemos tener los mismos problemas de memoria que hemos visto con las funciones de tabla. Se recomienda utilizar servidores vinculados únicamente cuando sea necesario y con criterios restrictivos para minimizar el volumen de datos transferidos.
Problemas de rendimiento por diseño y arquitectura
En ocasiones aunque nuestra consulta esté optimizada sigue rindiendo mal, y esto puede ser debido, entre otras cosas, a un mal diseño de las soluciones de bases de datos. Veamos ahora los principales problemas de diseño:
Consultas dinámicas o ad hoc
Estas consultas se construyen en tiempo de ejecución y no se almacenan en el caché del plan de ejecución, lo que implica que el optimizador tenga que generar un nuevo plan cada vez que se ejecutan. Esto consume más recursos y tiempo, y puede provocar planes subóptimos. Para evitarlo, se recomienda utilizar procedimientos almacenados o consultas parametrizadas, que se almacenan en el caché y se reutilizan cuando se ejecutan con los mismos parámetros. A este tema le dedicamos ya un artículo hace unos días.
Problemas de rendimiento de índices
Los índices son estructuras que facilitan la localización y el acceso a los datos, y son esenciales para mejorar el rendimiento de las consultas. Sin embargo, hay que tener cuidado con el tipo, el número y la definición de los índices, ya que pueden tener efectos negativos si no se usan correctamente. Por ejemplo, un índice demasiado grande o con muchas columnas puede ralentizar las operaciones de inserción, actualización o borrado, o consumir demasiado espacio en disco. Un índice mal diseñado o no utilizado puede generar escaneos innecesarios o planes ineficientes. Un índice faltante puede obligar a realizar escaneos completos o búsquedas secuenciales.
Para evitarlo, se recomienda analizar las consultas más frecuentes o críticas y crear índices adecuados para ellas, teniendo en cuenta las columnas usadas en los predicados WHERE, JOIN, ORDER BY y GROUP BY, así como la cardinalidad y la selectividad de los datos. En este blog le hemos dedicado a los índices más de media docena de artículos que os recomiendo leer.
Estadísticas desactualizadas
Las estadísticas son objetos que almacenan información sobre la distribución y la frecuencia de los valores en las columnas de las tablas e índices. El optimizador de consultas utiliza esta información para estimar el coste y elegir el mejor plan de ejecución posible. Sin embargo, si las estadísticas no reflejan la realidad de los datos, el optimizador puede generar planes subóptimos o erróneos, lo que afecta al rendimiento. Para evitarlo, se recomienda mantener las estadísticas actualizadas mediante trabajos programados como los que vimos aquí.
Problemas de rendimiento por tipos de datos inadecuados
Los tipos de datos son los que definen el formato, el tamaño y el rango de los valores que se almacenan en las columnas de las tablas e índices. Elegir el tipo de dato adecuado para cada columna es fundamental para optimizar el rendimiento de las consultas, ya que influye en el espacio ocupado, la velocidad de acceso, la precisión y la compatibilidad. Por ejemplo, un tipo de dato demasiado grande o con una precisión innecesaria puede consumir más espacio en disco y memoria, lo que ralentiza las operaciones y aumenta el riesgo de desbordamiento. Un tipo de dato incompatible con el valor esperado puede generar errores o conversiones implícitas, lo que afecta a la calidad y la eficiencia de los datos.
Para evitarlo, se recomienda elegir el tipo de dato más apropiado para cada columna, teniendo en cuenta el valor máximo, mínimo y medio que se espera almacenar, así como el uso que se le va a dar.
Es importante usar el mismo tipo de datos a la hora de escribir la consulta que el que hay en las tablas ya que una conversión obligará a SQL Server escanear completamente las tablas e índices y no poder beneficiarse de las características de árbol B.
Problemas de rendimiento por el servidor
Para terminar, vamos a ver el último factor posible en la degradación del rendimiento, el servidor. En ocasiones nos vamos a encontrar con diseños de bases de datos y consultas optimizadas y sin embargo un mal rendimiento. La principal causa de problemas con el rendimiento del servidor está relacionada con el consumo de recursos. Y es que cuando esto pasa, normalmente tendremos otro proceso ajeno al nuestro consumiendo todos los recursos del servidor. Aunque es cierto que optimizando nuestras consultas y modelos de datos necesitaremos nosotros menos recursos y seremos más resilientes ante este tipo de escenarios, en ocasiones no será suficiente y veremos como la ruedecita de abajo a la izquierda de nuestra pantalla no deja de dar vueltas y nuestra consulta no termina.
En estas ocasiones yo tiro de recursos como los procedimientos sp_who3 y sp_whoisactive para ver qué más hay en ejecución en SQL Server y ver si lo puedo detener o tengo que ir a dar una colleja a alguien.
Bloqueos
Otro posible problema que detecto con esos procedimientos son los bloqueos. Los bloqueos son mecanismos que garantizan la integridad y la consistencia de los datos cuando se realizan operaciones concurrentes sobre la base de datos. Sin embargo, también pueden afectar al rendimiento si no se gestionan correctamente. Por ejemplo, un bloqueo excesivo o innecesario puede impedir o retrasar el acceso a los datos por parte de otras transacciones, lo que reduce la concurrencia y genera esperas. Un bloqueo insuficiente o incorrecto puede provocar problemas de integridad o consistencia, como lecturas sucias o pérdidas. Para evitarlo, se recomienda utilizar el nivel de aislamiento adecuado para cada transacción, teniendo en cuenta el grado de consistencia y concurrencia que se requiere. Hablamos de niveles de aislamiento aquí.
Problemas ajenos a SQL
Si esto no devuelve nada esclarecedor es posible que el proceso que esté consumiendo los recursos sea ajeno a SQL Server y tendremos que mirar los procesos en ejecución del sistema operativo. En una ocasión me he encontrado con un caso peor, la cabina de discos estaba saturada y aunque mi servidor estaba rascándose el ombligo no había manera de que terminaran las consultas. Esto si que es un verdadero expediente X difícil de encontrar y ojalá no tengáis que lidiar nunca con una situación tan compleja.
Conclusión
Estas son solo algunas de las causas más comunes de mal rendimiento en consultas de SQL Server, pero hay muchas más que pueden influir en el comportamiento del sistema. Te invitamos a revisar los artículos que he enlazado a este si quieres profundizar más en estos temas.
Espero que este artículo te haya resultado útil e interesante. Si tienes alguna duda o comentario, no dudes en contactarnos en Twitter o por mail o dejarnos un mensaje en los comentarios de aquí abajo. Y recuerda que también tenemos un grupo de LinkedIn al que te puedes unir.