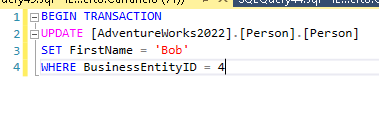Ayer vimos con detalle cómo restaurar una base de datos en SQL Server, sin embargo, en muchas ocasiones lo que necesitaremos es restaurar solo una tabla. El motivo más común para tener que restaurar una copia de seguridad es por un fallo humano a la hora de modificar datos, por lo que necesitaremos restaurar una o varias tablas pero no toda nuestra base de datos. Lamentablemente SQL Server no ha desarrollado aún (finales de 2023) ninguna funcionalidad para hacer esto de forma fácil y eficiente. Mientras esto no pase, vamos a ver paso a paso cómo podemos hacer para recuperar nuestra tabla a un momento anterior.
Preparación del entorno
Para las pruebas voy a usar la base de datos StackOverflow2013. Esta es una base de datos de ejemplo, pero podéis usar cualquier base de datos de pruebas que tengáis.
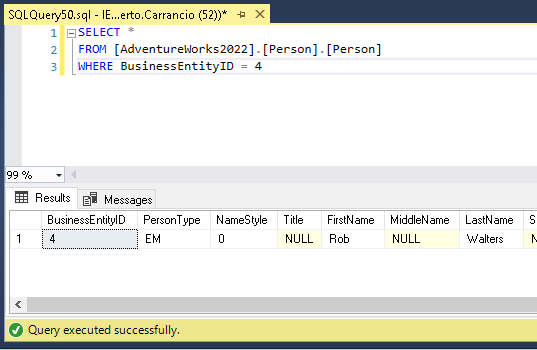
Tomaré como ejemplo esta tabla
Aplicaré estas 2 sentencias para cambiar los datos:
delete from [dbo].[VoteTypes] where id > 3
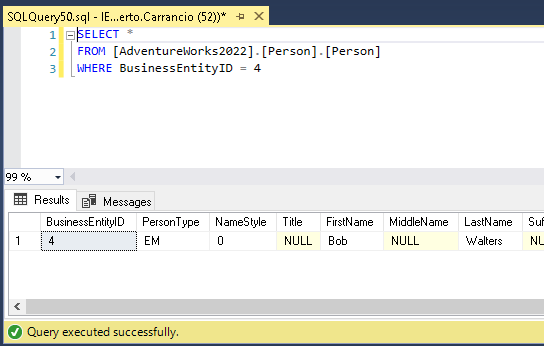
update [dbo].[VoteTypes] set Name = 'Closed'
Restaurar: Paso 1
Como hemos dicho lo primero que tenemos que hacer es restaurar una copia de la base de datos de antes de haber cometido el fallo. No sabemos que más operaciones legítimas se han hecho en la base de datos por lo que no podemos sobrescribir los datos. Restauraremos la base de datos con otro nombre para no pisar nada. Todo esto lo vimos en el post de ayer por lo que no nos vamos a detener más en este punto.
Restaurar: Paso 2
Una vez tengamos nuestra copia restaurada con otro nombre tendremos que mover los datos de la tabla a la base de datos original. Para eso podemos hacerlo con el asistente de copia de datos o mediante script, veámoslo.
Asistente de copia de datos
Nos situaremos sobre la base de datos original y abriremos el asistente desde el menú del botón derecho del ratón. Elegiremos como origen la base de datos restaurada, como destino la original y copiaremos los datos de la tabla borrando lo que contiene actualmente. Como la tabla del ejemplo contiene un campo IDENTITY nos aseguraremos de marcar el check para poder insertar en esos campos.
Abrir asistente de importación.Origen de datosDestino de datosConfiguración de la copia
Script INSERT INTO
Para esta técnica también vamos a vaciar la tabla original. A continuación habilitaremos la inserción de campos IDENTITY para despues insertar los datos desde la tabla de la base de datos restaurada.
TRUNCATE TABLE [StackOverflow2013].[dbo].[VoteTypes]
GO
SET IDENTITY_INSERT [StackOverflow2013].[dbo].[VoteTypes] ON
GO
INSERT INTO [StackOverflow2013].[dbo].[VoteTypes] (id, name)
SELECT id, name FROM [StackOverflow2013_RESTORE].[dbo].[VoteTypes]
GO
Script MERGE
Muchas veces, solo unos pocos datos estarán mal y borrar y cargar la tabla entera no será una solución eficiente. En estos casos podremos usar MERGE para solo insertar los registros que faltan o actualizar solo los que no estén bien. Esta sería la sintaxis en nuestro caso:
SET IDENTITY_INSERT [StackOverflow2013].[dbo].[VoteTypes] ON
GO
MERGE [StackOverflow2013].[dbo].[VoteTypes] AS Destino
USING [StackOverflow2013_RESTORE].[dbo].[VoteTypes] AS Origen
ON Destino.ID = Origen.ID
WHEN NOT MATCHED BY Target THEN
INSERT (id, Name)
VALUES (Origen.ID, Origen.Name)
WHEN MATCHED AND Destino.Name <> Origen.Name THEN
UPDATE SET Destino.Name = Origen.Name ;
GO
Restaurar: Paso 3
Una vez que nuestra tabla vuelva a tener los datos correctos avisaremos a los usuarios para que lo confirmen. Si todo está ok, ya solo nos restaría borrar la base de datos restaurada para liberar ese espacio.
Conclusiones
Como hemos visto, restaurar una tabla es un proceso manual que tenemos que controlar. Habrás notado que durante este artículo he sido bastante crítico con el hecho de que no haya una forma de restaurar una tabla de un archivo de copia de seguridad y seguramente vosotros estéis en la misma situación. Es normal, a día de hoy las restauraciones de tablas son la segunda petición a Microsoft más votada por los usuarios en la web de feedback de usuarios. Hace un año Microsoft confirmó tenerlo como una tarea pendiente para futuras versiones de SQL Server. Aun así, mientras esto no llegue, tenemos que conocer el procedimiento de memoria y estar familiarizados con él ya que es una labor crítica.
Cuando se pierden unos datos de producción, estamos sometidos a mucha presión y tenemos que dar una solución rápida y eficaz por lo que os recomiendo practicar esto que hemos visto en diferentes situaciones. De esta manera, el día que os toque lidiar con ello, será todo mucho más sencillo.
En el pasado post vimos todo lo que necesitamos saber sobre las copias de seguridad de SQL Server excepto una cosa, como restaurarlas en caso de necesidad. Como esto no puede ser, vamos a ponerle solución ahora mismo. Ya hemos comentado en varias ocasiones que restaurar copias de seguridad es una de las principales tareas de todo DBA. De hecho, es de las primeras cosas que suele aprender un DBA de SQL Server.
Consideraciones antes de restaurar
Lo primero que tenemos que tener claro a la hora de restaurar una base de datos es la compatibilidad. Solo podremos restaurar una base de datos si viene de un servidor con una versión de SQL igual o inferior al servidor de destino.
¿Sobrescribir o no sobrescribir? Esa es la cuestión
Cuando confirmamos que es posible restaurar, valoraremos si vamos a sobrescribir datos existentes. En caso afirmativo, asegúrate de tener confirmación de los responsables de los datos. Una vez revertido el estado de la base de datos a un momento anterior se perderán todos los datos que no existieran al momento de hacer la copia. Si la base de datos que estamos restaurando no existe en este servidor no vamos a sobrescribir los datos. Si existe tendremos la opción de restaurar sobrescribiendo o crear una base de datos nueva con otro nombre.
Una vez que tengamos claro lo anterior es el momento de volverse a preguntar si realmente tenemos claro que vamos a sobrescribir datos. Puedo parecerte un pesado pero, confía en mí, TODOS nos hemos cargado una base de datos alguna vez por menospreciar este detalle. Revísalo varias veces y asegúrate de que los usuarios han entendido las implicaciones. Aun así, si no tenemos problemas de tiempo ni de espacio, es recomendable hacer una copia de seguridad de lo que hay antes de sobrescribir.
¿Ya lo tiene todo el mundo claro? Ok es el momento de mirar las copias de seguridad y ver cuál se adapta mejor a nuestras necesidades. Si tenemos suerte, será suficiente con una copia completa pero puede que además necesitemos una copia diferencial y varias copias del log.
Por último, si sabemos cuánto ocupa la base de datos, es el confirmaremos que tenemos espacio suficiente.
¿Cómo restaurar una base de datos SQL Server?
Ha llegado de ponernos manos a la obra, tenemos que restaurar nuestros datos y la operativa cambiará en función de las decisiones que hayamos tomado. En cualquiera de los casos tendremos la opción de restaurar desde el entorno gráfico o por script. Mi consejo es que inicies el proceso desde el entorno gráfico pero antes de finalizar saques el script. Esto te permitirá una última revisión de que todo está como quieres.
Abriremos la ventana de restauración de bases de datos de nuestro SSMS, seleccionaremos restaurar desde dispositivo y seleccionaremos de una sola vez todos los ficheros que necesitemos (completa + diferencial + logs). Esta es la manera más sencilla, SQL se encargará de todo lo necesario para restaurar los ficheros en el orden correcto. Elegiremos también la ruta donde se van a restaurar los ficheros de base de datos, nos propondrá la ruta por defecto y podremos cambiarla si es necesario. Las opciones principales que debemos seleccionar es si deseamos mantener o no la configuración de replicación en caso de existir y si queremos restringir el acceso de usuarios una vez restaurada. Además de la opción de sobrescribir en caso de ser necesario. Si la base de datos existe y vamos a sobrescribir podremos cerrar todas las conexiones existentes antes de restaurar, lo que pone la base de datos en SINGLE_USER, restaura y vuelve a configurar el MULTI_USER.
Con todo configurado podemos darle a OK, aunque como ya os he dicho yo soy partidario de sacar el script y verificar que todo está correcto. Si lo hacéis y tenéis más de un archivo para restaurar veréis que todos los ficheros menos el último se restauran con la opción NORECOVERY, lo que deja la base de datos inaccesible pero preparada para restaurar nuevos archivos. Esta opción también la podemos seleccionar a mano si lo deseamos.
Permisos
Si la base de datos que vamos a crear es nueva, necesitaremos permisos de CREATE DATABASE, este permiso está incluido en los roles de servidor SYSADMIN y DBCREATOR. Si la base de datos necesitaremos SYSADMIN ya que teniendo DB_OWNER en esa base de datos no será suficiente..
Próximos pasos
Si nuestra base de datos viene de otro servidor lo más probable es que una restaurada nuestra base de datos tengamos que asignar los permisos a los usuarios del servidor actual. Además si usamos SQL es probable que nos encontremos con un problema de usuarios huérfanos (en otro post lo veremos en detalle y su solución).
Una de las tareas más importantes que debemos hacer como DBAs son las relacionadas con las copias de seguridad. Tenemos que saber cómo hacer copias de seguridad y cómo restaurarlas. Esto nos permitirá recuperar nuestras bases de datos a un momento anterior en caso de incidente que podría ir desde un borrado accidental de un dato hasta un fallo total del servidor.
Tipos de copias de seguridad
Existen 3 tipos principales de copias de seguridad: Completas, Diferenciales y de log de transacciones. Las copias de log de transacciones solo podremos hacerlas si tenemos nuestra base de datos en modo de recuperación completa.
Copias Completas
Este tipo de copia de seguridad es el principal, no podremos realizar ninguno de los otros tipos de copias de seguridad si no existe previamente una de estas. Esta copia de seguridad almacena en un archivo todo lo que contiene la base de datos en ese momento. Este archivo será suficiente para restaurar la base de datos.
Copias Diferenciales
Esta copia de seguridad almacena todos los cambios que ha sufrido nuestra base de datos desde la última copia de seguridad completa. Para restaurarlo deberemos disponer de la copia base que deberemos restaurar primero.
Copias de los logs de transacciones
Cuando tenemos las bases de datos en modo de recuperación completa todas las transacciones se van almacenando en el log de transacciones. Se almacenan en el log de transacciones hasta que no se vuelquen en un archivo de copia de seguridad. Por lo tanto este archivo lo que almacena son las transacciones realizadas en la base de datos. Para restaurarlo debemos restaurar una copia completa y todos las copias de log, una a una y en orden hasta el punto exacto en el tiempo que deseemos.
Tipos especiales de copias
Dentro de estos tipos principales de copias de seguridad podemos encontrarnos con alguna variación que si bien es parecida tiene algunas particularidades.
Copias de seguridad solo copia
Este es un tipo de copia especial que no afecta a la cadena de copias de seguridad convencional. Como hemos comentado, cuando queremos restaurar una copia diferencial debemos primero restaurar la copia base completa. Esta relación necesaria se conoce como cadena de copias de seguridad. En ocasiones necesitaremos hacer una copia de seguridad para otros motivos sin afectar a la cadena existente, para ello usaremos la opción solo copia. Las opción solo copia se puede usar para copias de seguridad completas o de log de transacciones. Las copias de seguridad solo copia no vacían el log de transacciones.
Copias de seguridad de archivos o grupos de archivos
Cuando tenemos más de un archivo de datos en nuestra base de datos (en el mismo o en distinto grupo de archivos) y la base de datos está en modo de recuperación completa podemos realizar copias de seguridad completas o diferenciales parciales de solo uno o varios archivos. Al trabajar con copias de seguridad parciales existe el riesgo de perder la consistencia de las bases de datos.
Opciones de copias de seguridad
A la hora de hacer una copia de seguridad tenemos una serie de opciones importantes que tenemos que conocer. Por un lado en el apartado de opciones de medios podremos elegir si en caso de existir el fichero de copia queremos sustituirlo por el nuevo o si queremos anexar la copia al archivo existente. Aquí tenemos también las opciones de verificar el backup al finalizar, hacer un checksum antes de escribir el archivo y si en caso de error deseamos continuar.
Como opciones de la copia podremos definir un nombre, una descripción y una fecha de expiración. Una copia de seguridad se va a poder restaurar aunque se haya superado la fecha de expiración, esta solo se usa para saber cuándo se puede eliminar la copia por los procesos de limpieza. Como última opción,tenemos otra muy importante, la compresión o no compresión del archivo de copia de seguridad.
Si quereis podemos ver esto en un caso práctico en otro artículo, ahora tenéis que saber que una copia comprimida llevará más consumo de CPU pero ocupará menos. Para una copia local, si tenemos espacio suficiente una copia sin comprimir (tanto para copiar como para restaurar) pero para una copia en una ubicación de red, ese extra de tamaño, penalizará tanto que, la mayoría de las veces, compensará comprimir nuestra copia.
¿Cómo hacer copias de seguridad en SQL Server?
Como ya habréis podido notar los que seguís el blog, hacer un manual paso a paso no es el objetivo de estos artículos. Aquí queremos que entendáis los conceptos y sepamos lo que estamos haciendo, de cómo se hace está internet lleno. Solo vamos a comentar que podemos hacer nuestras copias de seguridad desde el entorno gráfico, por script o con herramientas de terceros. Si queréis saber como hacer las copias por el entorno gráfico o por script podéis consultar la documentación oficial. Como herramientas de terceros hay muchas en el mercado aunque, personalmente, no me canso de recomendar la solución de OLA HALLENGREN.
Permisos necesarios
Para poder hacer copias de seguridad necesitarás los permisos de BACKUP DATABASE y BACKUP LOG. Estos permisos están incluidos en el rol de servidor sysadmin y de los roles de bases de datos db_owner y db_backupoperator.
Además de los permisos en SQL, el usuario de servicio de SQL deberá tener permisos de lectura y escritura en el directorio destino de las copias de seguridad. Si vamos a programar las copias en un job, el usuario de servicio del Agente de SQL también necesitará permisos.
Próximos pasos
Ahora que ya sabemos como funcionan las copias de seguridad en SQL Server os emplazo a leer el próximo artículo en el que hablaremos de sus restauraciones. Al igual que en este, veremos las opciones de restauración que podemos definir y en qué nos van a afectar.
En el post de ayer pudimos ver qué es un DBA y os prometí hablaros de las tareas que todo DBA de SQL Server debe ejecutar a diario. Pues bien, vamos a ello. Existen una serie de tareas que por su criticidad deberemos realizar o revisar diariamente. Obviamente todas estas estas tareas son candidatas de automatizarse, cosa que debe de ser nuestro objetivo final. Aunque, próximamente iremos viendo cómo debemos automatizar todas estas tareas hoy nos vamos a centrar solo en enumerarlas y ver por qué son necesarias.
Como comentamos ayer, una de las cualidades más importantes del buen administrador es tener el control absoluto sobre todo lo que gestiona. Esto no es solo aplicable a las bases de datos pero como este blog habla de ser DBA nos vamos a centrar en ello. Para tener un control absoluto sobre nuestros sistemas debemos por un lado llevar un mantenimiento preventivo para asegurar que no se produzcan incidencias. Por otro lado, deberemos también adelantarnos a los posibles problemas con una buena monitorización. Para que no se nos escape nada de lo que pasa es recomendable una buena auditoría. Y por último, por si todo lo demás falla, debemos asegurarnos de tener un buen plan de recuperación. Ahora sin más palabrería vamos a ver uno a uno cada uno de estos grupos que acaban de salir.
Tareas de copia de seguridad
Aunque en la introducción hemos hablado del plan de recuperación en último lugar, es tan importante que vamos a empezar por este apartado. Es importante tener al menos una copia diaria de todos los entornos de producción, aunque yo soy partidario de tener más y de todos los entornos. Una buena política de copias de seguridad tendrá una retención acorde con las necesidades técnicas y legales (en ocasiones hasta 10 años de retención para datos críticos).
En SQL Server existen 3 tipos de copias de seguridad: completa, diferencial y del log de transacciones. Mi política de backups modelo para un entorno productivo pasa por una copia completa semanal (los domingos), una copia diferencial diaria (de lunes a sábado) y una copia del log de transacciones cada hora. En este escenario ideal, mi retención de las copias semanales sería de 3 a 6 meses, las diarias de 1 a 3 meses y las horarias de al menos una semana.
No podemos hacer copias y olvidarnos de ellas, además de revisar cada día que las tareas no han dado error es importante que, con cierta frecuencia, recuperemos al menos uno de los ficheros de copias de seguridad para asegurarnos de que es correcto. SQL Server implementa la opción de verificar todos los backups durante el proceso de copia, pero para mi, esto no sustituye una prueba periódica. Aunque los backups sean correctos puede que el almacenamiento donde los tenemos se dañe con el tiempo y tenemos que ser capaces de reaccionar antes de que sea tarde.
Tareas de mantenimiento
Para mi, un buen plan de mantenimiento de SQL Server debe incluir tareas de desfragmentación de índices, actualización de las estadísticas y un chequeo de la integridad de las bases de datos. Estas son tareas muy pesadas por lo que tendrán una programación en las horas de menor actividad y nosotros solo verificaremos que han completado correctamente. Para este tipo de tareas yo siempre confío en los scripts de OLA Hallengren, software libre y de uso muy extendido en nuestro sector.
Desfragmentación de índices y actualización de estadísticas
El rendimiento de nuestras bases de datos depende en gran medida de sus índices. SQL Server los usará para acceder de eficientemente a los datos que almacenamos y si no están en buenas condiciones no va a poder usarlos. Por este motivo es de vital importancia un buen plan de reorganización y reconstrucción de los índices fragmentados. Como norma general reorganizaremos los índices con una fragmentación entre el 5 y el 30%. Con menos de un 5% de fragmentación podemos considerar el índice en óptimas condiciones de funcionamiento. Para los índices fragmentados más del 30% ejecutaremos una tarea de reconstrucción que será más óptima.
Hemos dicho que SQL Server usa los índices para acceder a los datos pero esto no lo hace por arte de magia, implementa unos algoritmos que miran las estadísticas de las tablas y toman la decisión de qué índice usar y cuando. Es por esto que un mantenimiento de índices siempre debe de ir acompañado por un mantenimiento de estadísticas.
Todo esto que os acabo de comentar, se puede hacer en una única ejecución de los procedimiento almacenados de OLA con el siguiente script:
Comprobaciones de integridad de las bases de datos
Existen varios tipos de comprobaciones de integridad pero nosotros nos vamos a centrar en dos. Por un lado tenemos el famoso DBCC CHECKDB que nos revisa tanto la integridad de los datos como que los ficheros de base de datos no estén corruptos. Si a este comando le añadimos el comando PHYSICAL ONLY omitiremos el chequeo de integridad de los datos y solo se verificará que los ficheros no estén corruptos.
Debemos comprobar que nuestra base de datos no está corrupta de manera recurrente, siempre que sea posible ejecutaremos una comprobación completa a diario. Si no tenemos una ventana de mantenimiento disponible en el día a día para esta comprobación completa haremos al menos una comprobación physical only y dejaremos la comprobación para un día del fin de semana con mayor ventana de mantenimiento.
Esta comprobación la haremos con el siguiente script de OLA (la última línea solo la descomentaremos en caso de querer un chequeo physical only)
Un DBA profesional sabe anticiparse a los problemas, pero no porque tenga un especial sentido arácnido, sino porque tiene una buena monitorización que le avisa a los primeros síntomas. El log de errores de SQL Server debe ser nuestro amigo, debemos leerlo en busca de pistas que nos indiquen que algo no está como debería. Debemos prestar especial atención a los errores 823, 824 y 825 así como a todos los mensajes con una gravedad mayor a 17.
Si nuestro servidor tiene salida a internet y configurado el correo de base de datos lo mejor sería programar alertas para estos casos. Otros aspectos importantes a monitorizar son los bloqueos de consultas, sesiones con transacciones abiertas de larga duración, espacio restante en disco y en los ficheros de bases de datos si hemos definido un límite de crecimiento. Yo también suelo programar una alerta que comprueba que todas las bases de datos estén ONLINE. Por último si somos responsables de la ejecución de algún job miraremos su historial de ejecución.
Tareas de auditoría
Si bien este tipo de tareas no suelen incluirse en los listados de tareas diarias, una buena auditoría nos ayudará a saber qué está pasando. Además, podremos entender mejor los problemas que les puedan surgir a los usuarios. Y no hablo de una auditoría completa de todo lo que se ejecuta sino de por ejemplo auditar los inicios de sesión incorrectos. Esta auditoría, activada por defecto en SQL Server, nos ayuda a afrontar incidentes de acceso de los usuarios ya que registra el motivo del fallo. Si un usuario no puede acceder pero no vemos registro en el log es probable que no esté llegando al servidor.
Otra auditoría que a mi me es muy útil es el registro de cambios en la estructura de las tablas, con una consulta en un job vuelco en una tabla el contenido de la vista information_schema.columns y puedo detectar cuando hay un cambio que me pueda dar problemas. Me gusta también implementar en todos mis sistemas de producción una auditoría que registre diariamente en una tabla los permisos de todos los usuarios de SQL Server para que, cuando se produzca un fallo de permisos, pueda ver si ese usuario ha perdido los permisos por algo o es que nunca los ha tenido.
Conclusión
Es importante saber prevenir y anticiparnos a los problemas. Diariamente mantendremos nuestras bases de datos y revisaremos que todo esté correcto. En resumen:
Optimizaremos índices y estadísticas.
Chequeamos la integridad de las bases de datos.
Haremos y verificaremos las copias de seguridad.
Buscaremos errores en el log de errores de SQL Server.
Revisaremos el espacio libre en disco.
Auditamos los problemas más comunes a los que nos podamos llegar a enfrentar.
Puede parecer mucho pero os aseguro que todas estas tareas se pueden automatizar y al final lo único que debemos hacer es estar pendientes de un sistema de monitorización o del correo electrónico que nos avise en caso de que algo no va como debería.
En esta segunda entrada sobre los niveles de aislamiento vamos a ver qué significa en la práctica lo que vimos en el post de ayer. Si aún no lo has leído te recomiendo que vayas primero a él para saber de lo que hablamos. Vamos a comparar el mismo caso práctico con los niveles de aislamiento READ UNCOMMITTED, READ COMMITTED y READ COMMITTED SNAPSHOT.
Para que todos podáis hacer las pruebas en vuestra instalación de SQL vamos a usar la base de datos de ejemplo AdventureWorks. AdventureWorks es una base de datos de ejemplo que proporciona Microsoft y que está disponible para descargar en su web. Tanto si estáis empezando a aprender SQL como si ya lleváis tiempo y queréis estar al día os recomiendo siempre que tengáis una instalación donde hacer pruebas con alguna base de datos de ejemplo. Otra buena base de datos que no debería faltar en vuestra instalación de pruebas es la versión SQL de los datos anonimizados de stackoverflow que proporciona Brent Ozar.
Caso Práctico
Este ejemplo es uno de los más típicos que nos vamos a encontrar en nuestro día a día como DBA. Vamos a simular 2 transacciones, la primera va a hacer una actualización de la tabla de personas y mientras la actualización esté en progreso una segunda transacción va a intentar leer los datos.
NIVEL DE AISLAMIENTO READ COMMITTED
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla. Se genera un bloqueo exclusivo sobre el registro.
Cuando la segunda sesión va a leer se queda en espera, el intento de bloqueo compartido sobre el registro no es compatible con el bloqueo exclusivo de la transacción de la primera sesión.
rollback
La transacción se aborta. Se genera un rollback y se libera el bloqueo exclusivo.
Con el bloqueo exclusivo liberado la segunda sesión ya es capaz de devolver los datos solicitados.
NIVEL DE AISLAMIENTO READ COMMITTED SNAPSHOT
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla. Se genera un snapshot del dato anterior a la transacción en TempDB
Cuando la segunda sesión solicita ese registro lo puede recuperar del snapshot en TempDB.
rollback
La transacción se aborta. Se genera un rollback y se elimina el snapshot.
NIVEL DE AISLAMIENTO READ UNCOMMITTED
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla.
Cuando la segunda sesión solicita ese registro lo lee directamente aunque se esté modificando.
rollback
La transacción se aborta y se genera un rollback
En una segunda lectura la sesión 2 recupera un dato diferente.
Conclusión
Hemos podido ver que significa leer datos sucios y qué implicaciones tiene. Además, hace unos días vimos también el peligro de las lecturas fantasma de NOLOCK que también se producen en el nivel de aislamiento READ UNCOMMITTED. Tras esta serie de artículos estamos preparados para elegir los niveles de aislamiento correctos para nuestras bases de datos.
Ahí va mi recomendación personal: si tenemos que hacer una prueba o leer un dato puntualmente en un entorno productivo pero sin afectar a la producción podemos usar READ UNCOMMITTED. No deberíamos usar este nivel de aislamiento en ningún caso más. Usaremos un nivel de aislamiento READ COMMITTED SNAPSHOT si nuestra base de datos tiene un problema de bloqueos. Si estamos desarrollando una base de datos nueva mi recomendación también sería READ COMMITTED SNAPSHOT. Por el contrario, en la mayoría de los casos, si todo funciona con la configuración por defecto mejor dejarlo como está. Al fin y al cabo, un cambio que va a afectar a todas las transacciones requiere un esfuerzo en pruebas que rara vez nos será rentable si no es para solucionar un problema específico.
Como os prometí en el pasado artículo sobre el uso de NOLOCK hoy vamos a profundizar sobre los distintos niveles de aislamiento que implementa SQL Server. Es teoría básica de bases de datos, pero me parece imprescindible volver a ello frecuentemente y afianzar conceptos clave que marcarán el funcionamiento de nuestra base de datos. Aunque los niveles de aislamiento son algo común de todos los gestores de bases de datos, no todos implementan todos ni usan el mismo nivel por defecto. Aunque según el estándar SQL existen 4 niveles de aislamiento, en este artículo nos vamos a centrar en los niveles de aislamiento que implementa SQL Server. No solo porque es mi base de datos principal, sino también porque SQL Server implementa 5+1 niveles de aislamiento frente a los 3 que soporta Oracle o los 4 del estándar de PostgreSQL.
Antes de profundizar en los niveles de aislamiento, hay que afianzar otra serie de conceptos básicos como las propiedades ACID de una base de datos y la gestión de concurrencia basada en bloqueos.
Gestión de transacciones
Tenemos que entender las transacciones como la operación más básica del motor de base de datos. Son operaciones indivisibles y tienen que terminar completamente. Para entenderlo podemos compararlo con una transacción comercial, Tu pides un producto y esperas a que el vendedor te diga el precio. El vendedor te dice el precio y espera a que le des el dinero. Tu le das el dinero y esperas a que te de el producto. Si la transacción es correcta llegará hasta el final, pero si se detiene en cualquiera de las fases se volverá a la situación inicial donde tu tienes el dinero pero no el producto.
Con este ejemplo en mente vamos a explicar lo que son las propiedades ACID (siglas en inglés de Atomicidad, Consistencia, Aislamiento y Durabilidad).
Atomicidad: Como hemos dicho, las transacciones son la operación básica de las bases de datos y deben ser indivisibles. Al igual que en nuestro ejemplo de la compra, para que la operación se finalice se tienen que completar todos los pasos de la transacción.
Consistencia: Toda transacción debe mantener la coherencia de la base de datos. Si no termina correctamente tiene que hacer rollback (deshacer los cambios) y volver al estado original. Es lo mismo que cuando decíamos que si nuestra compra se interrumpe volvemos a tener el dinero pero no el producto.
Aislamiento: Cada transacción es independiente de las demás. El comportamiento de esta característica cambiará en función del nivel, que es lo que vamos a ver más adelante. En nuestro ejemplo, nuestra compra no se ve afectada por las demás compras.
Durabilidad: Todas las transacciones tienen que estar registradas en la base de datos y permanecer en ella después de una interrupción de servicio. Cuando el servicio se reanude, las transacciones confirmadas se verán reflejadas en la base de datos, mientras que las no confirmadas sufrirán un rollback.
Gestión de concurrencia
Tipos de bloqueos
Por defecto, SQL Server implementa los bloqueos para garantizar el aislamiento de las transacciones. En este contexto podemos encontrarnos con dos tipos de bloqueos, los bloqueos compartidos y los bloqueos exclusivos. Entenderemos el bloqueo compartido como el tipo de bloqueo para operaciones de lectura y los bloqueos exclusivos como los bloqueos para las escrituras.
Compatibilidad entre bloqueos
Cada operación de lectura generará un bloqueo compartido sobre el recurso que lea. Pueden existir varias operaciones de lectura simultáneas sobre un mismo recurso y cada una de ellas generará un bloqueo compartido. Las operaciones de escritura, sin embargo, generarán un bloqueo exclusivo, ya que mientras hay una escritura en curso no puede haber más operaciones (ni lecturas ni escrituras) sobre ese recurso.
Cuando se inicia una operación de escritura, intentará generar un bloqueo exclusivo en el recurso afectado. Si existen bloqueos (compartidos o exclusivos) en el recurso este intento de bloqueo exclusivo no podrá iniciarse y esperará a que termine el resto de transacciones.
Niveles de aislamiento
Como a estas alturas ya sabrás, los niveles de aislamiento son una forma de controlar el acceso concurrente a los datos de una base de datos, es decir, cómo se comporta el sistema cuando varios usuarios o procesos intentan leer o modificar los mismos registros al mismo tiempo. Los niveles de aislamiento afectan al rendimiento y a la consistencia de los datos, así que vamos a verlos en detalle.
Read uncommitted isolation
Este es el nivel más bajo de aislamiento, permite leer los datos que están siendo modificados por otras transacciones, incluso si éstas no han terminado o confirmado sus cambios. Esto puede provocar problemas como lecturas sucias, lecturas no repetibles o lecturas fantasma, que veremos más adelante. Este nivel tiene el mejor rendimiento, pero el peor nivel de consistencia. Es el equivalente al uso de NOLOCK que vimos en el post anterior.
Read committed isolation
Este es el nivel predeterminado de SQL Server. Impide leer los datos que están siendo modificados por otras transacciones hasta que éstas terminen y confirmen sus cambios. Esto evita las lecturas sucias, pero no las lecturas no repetibles o las lecturas fantasma. Este nivel tiene un buen equilibrio entre rendimiento y consistencia, pero puede no ser suficiente para algunas operaciones críticas.
Read committed snapshot isolation (RCSI)
Este es el nivel predeterminado de Azure SQL Database y de Oracle, por ejemplo. Es, simplemente, una variación de Read Committed que en vez de generar bloqueos genera snapshots. Los snapshots son la versión original de los datos modificados, se almacenan en tempdb mientras dure la transacción bloqueante. El resultado es que una transacción de lectura nunca bloqueará a una escritura y viceversa. Se diferencia de read uncommitted en que, aunque el dato que estás leyendo pueda estarse cambiando, lo que lees si que ha sido un dato confirmado en algún momento.
Repeatable read isolation
Este nivel garantiza que si una transacción lee un registro, nadie podrá modificarlo hasta que la transacción termine. Esto evita las lecturas no repetibles, pero no las lecturas fantasma. Este nivel tiene un peor rendimiento que el anterior, ya que bloquea más registros y puede generar más contención.
Serializable isolation
Este es el nivel más alto de aislamiento, que impide cualquier modificación concurrente de los datos que lee una transacción. Esto evita tanto las lecturas no repetibles como las lecturas fantasma, pero tiene el peor rendimiento y el mayor riesgo de bloqueos y esperas.
Snapshot isolation
Este nivel permite leer los datos tal y como estaban al inicio de la transacción, sin importar si otros usuarios o procesos los han modificado después. Esto evita todos los problemas de consistencia mencionados, pero tiene un mayor coste de almacenamiento y procesamiento, ya que requiere mantener varias versiones de los datos en la base de datos. Puede generar errores cuando concurren varios procesos de escritura.
A modo resumen podemos ver estas dos tablas:
* Snapshot es un nivel de aislamiento solo a nivel de transacción. En caso de colisión en la escritura devuelve un error. ** SERIALIZABLE También bloquea la inserción de registros nuevo
Problemas de no elegir el nivel de aislamiento correcto
Hemos hablado de que los niveles de aislamiento nos puede ocasionar una serie de problemas como lecturas sucias, lecturas no repetibles y lecturas fantasma, pero, ¿qué son estos términos?
– Lectura sucia: No es leer “50 sombras de Grey”. Ocurre cuando una transacción lee un dato que está siendo modificado por otra transacción, pero ésta no ha confirmado sus cambios. Por ejemplo, si la transacción A modifica el precio de un producto, pero no lo confirma, y la transacción B lee ese precio, puede obtener un valor incorrecto o inconsistente.
– Lectura no repetible: Ocurre cuando una transacción lee dos veces el mismo dato, pero obtiene valores distintos porque otra transacción lo ha modificado entre medias. Por ejemplo, si la transacción A lee el stock de un producto, luego la transacción B lo reduce al comprarlo, y la transacción A lo vuelve a leer, obteniendo un valor menor al esperado.
– Lectura fantasma: Ocurre cuando una transacción lee un conjunto de datos que cumple cierto criterio, pero luego otra transacción inserta o elimina registros que también cumplen ese criterio. Por ejemplo, si la transacción A cuenta el número de clientes que viven en una ciudad, luego la transacción B añade o borra clientes de esa ciudad, y la transacción A vuelve a contarlos, puede obtener un número diferente al inicial.
Conclusión
Como hemos visto, elegir el nivel de aislamiento ideal para nuestra base de datos es un pulso entre rendimiento y coherencia de los datos. Recuerda que debes elegir el nivel adecuado para cada caso, teniendo en cuenta las ventajas e inconvenientes de cada uno. Un nivel de aislamiento serializable sería lo más seguro pero prácticamente imposibilita la concurrencia entre varios procesos, mientras que un Read Uncommitted ofrece el mejor rendimiento a un precio demasiado alto.
A partir de aquí, en tu mano está elegir el nivel de aislamiento ideal para tu base de datos. Solo espero que este post te haya ayudado a entender mejor qué son los niveles de aislamiento en SQL Server y cómo afectan a la consistencia y al rendimiento de tu base de datos. Si tienes alguna duda o comentario, puedes dejarlo abajo en los comentarios, mandarme un mail o contactarme por Twitter.
SQL Server implementa varios niveles de aislamiento sobre los que hablaremos más en profundidad en un futuro post, aunque por defecto se implementa el nivel READ COMMITTED o lecturas confirmadas. Sin embargo, esto se puede cambiar a nivel base de datos, transacción o incluso para una tabla dentro de una misma transacción. Hoy nos vamos a centrar en este último caso para lo que vamos a usar el HINT NOLOCK. Vamos a ver casos prácticos de uso aunque antes aclararemos algunos conceptos básicos.
Primero de todo, ¿qué es un HINT?
Un HINT (en español sugerencia de consulta) es un parámetro que indicamos a la hora de escribir nuestras consultas SQL y modifican el comportamiento del optimizador de consultas y del motor de base de datos. En SQL Server tenemos HINTS de 3 tipos: los HINTS de combinación, para especificar el tipo de JOIN que va a aplicar el motor de base de datos (Loop, Merge, Hash o Remote). Los HINTS de consulta, que se aplican con la cláusula OPTION y afectan a todos los operadores de la consulta y, por último, los HINTS de tabla que requieren la cláusula WITH y se usan para invalidar el comportamiento predeterminado del optimizador de consultas sobre esa tabla durante la instrucción DML.
Los HINT de tabla se pueden aplicar sin la cláusula WITH aunque esto es una característica en desuso que dejará de tener compatibilidad en futuras versiones de SQL Server. Deberemos declarar la cláusula WITH para asegurarnos la futura compatibilidad de nuestro código.
WITH (NOLOCK) un poco (más) de teoría
Entrando ya en lo que nos ocupa, NOLOCK es, como hemos podido ver, un HINT de tabla que le dice al motor de base de datos que no mire ni aplique bloqueos sobre esa tabla. En resumidas cuentas, es como si leyéramos nuestra tabla en un nivel de aislamiento READ UNCOMMITTED.
Así, a priori, puede parecer una buena idea usarlo, no bloqueos significa menos tiempos de espera y hasta menos consumo de recursos al no tener que dedicar esfuerzos en gestionar los bloqueos de filas, páginas o tablas. Podemos pensar, también, que los datos que estamos leyendo no cambian y por eso no nos preocupa. Sin embargo, NOLOCK tiene un “problema” y son las lecturas fantasma (no te preocupes si no entiendes nada, lo vamos a ver en la práctica).
Demostración
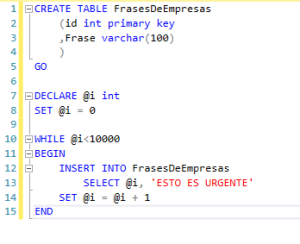
Preparación de un entorno de laboratorio
Para comprobar cómo funciona NOLOCK y sus efectos vamos a crear una tabla que vamos a llamar FrasesDeEmpresa. A continuación, vamos a añadirle 10.000 registros con una frase que normalmente se ha dicho más de 10.000 veces en todas las empresas del mundo: “ESTO ES URGENTE”
Uso de NOLOCK
Tenemos creada nuestra tabla FrasesDeEmpresa con sus 10.000 registros. Pongamos que alguien decide cambiarla y ahora la frase más escuchada es “Si funciona no lo toques”. Supongamos también que mientras alguien está cambiando todos los registros nosotros queremos leerlo. Como hemos dicho el comportamiento normal de SQL es READ COMMITTED así que hasta que quién está escribiendo no termine nosotros no podemos leer y sufriremos un bonito bloqueo.
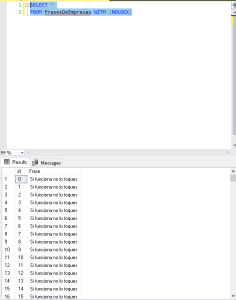
Oh vaya, lecturas confirmadas significa que no puedo leer hasta que el que escribe no confirme que ha terminado. ¿Quién lo iba a decir? Esto era urgente así que voy a usar NOLOCK y voy a leer lo que haya en ese momento aunque esté a medias.
Problemas de NOLOCK
Como hemos visto gracias al HINT NOLOCK hemos podido leer lo que se estaba escribiendo. El problema viene si por lo que sea la transacción de escritura no termina y deja todo como estaba, habríamos leído una información que nunca ha sido correcta. Pero hay más, como os decía antes este no es el único problema de NOLOCK, podemos tener las denominadas lecturas fantasmas. Esto es que por leer datos que se están manipulando nos encontremos con más o menos registros de los que verdaderamente hay. Veamos un ejemplo:
¿Qué ha pasado aquí? Nosotros teníamos 10.000 registros y solo los estaban actualizando. No se ha borrado ninguno y sin embargo nuestra cuenta ha contado un registro menos la mayoría de las veces.
Para entender esto tenemos que entender el comportamiento de los índices clustered. Si os fijáis, cuando he definido la tabla he definido el campo id como Primary Key lo que automáticamente lo convierte en índice clustered. Los datos están almacenados en mi disco duro ordenados por id. Cuando yo voy recorriendo todos los registros de mi tabla FrasesDeEmpersas para contar mientras otro mueve los registros de sitio me puedo encontrar con que un registro que ya he leido se mueve hacia delante y lo cuento 2 veces o con el caso contrario, que un registro que voy a leer simplemente ya no está ahí porque está detrás. Esto es lo que se conoce como lecturas fantasma y es el verdadero problema de NOLOCK y del nivel de aislamiento READ UNCOMMITTED.
Conclusión
A veces nos podemos sentir tentados de usar lecturas sucias para evitar bloqueos. Cuando esto pase, lo mejor es que dejemos lo que estamos haciendo, vayamos a tomar una cerveza y esperemos a que se nos pase. Siento ser tan tajante pero para mi no es una opción una configuración que pone en peligro cualquiera de las propiedades ACID de nuestra base de datos. Existen alternativas a los bloqueos como el nivel de aislamiento READ COMMITTED SNAPSHOT (el que implementa Oracle y no se ha acabado el mundo) que veremos en futuras entradas del blog y que nos solucionarán el problema sin poner el peligro la integridad de nuestros resultados.
Colabora con nosotros
SoyDBA.es es gratis para ti y siempre va a serlo. Sin embargo, a nosotros si que nos cuesta dinero además de mucho esfuerzo. Puedes colaborar con nosotros con un donativo por PayPal o usando nuestros enlaces de afiliado para colaborar sin que te cueste nada. Tenemos enlace de Amazon y de Aliexpress
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.