El romance entre DevOps y SQL Server es complicado. Como esas parejas que se quieren a gritos, viven juntas, pero uno duerme en el sofá y el otro con el gato. Porque claro, DevOps suena precioso sobre el papel: integración continua, despliegues automáticos, infraestructura como código y todo ese rollo de agilidad infinita. Pero cuando llevamos eso a una base de datos relacional que todavía tiene stored procedures escritos en 2009 por alguien que ya no trabaja en la empresa… el cuento cambia.
Nosotros, los DBAs, vivimos en esa intersección peligrosa entre los mundos del código y los datos. Y cuando alguien decide que ahora todo tiene que ir por pipelines de CI/CD porque “lo ha dicho el consultor de DevOps”, hay que tener cuidado. Porque sí, automatizar es maravilloso. Pero automatizar sin entender es como montar un sistema de riego automático sin comprobar si hay goteras. Spoiler: las hay. Y en producción.
Vamos a ver cómo podemos integrar nuestro trabajo como DBAs en ese ciclo CI/CD sin que todo explote. O al menos, sin que explote demasiado.
DevOps, el síndrome del pipeline perfecto y la realidad del script roto
Hay que empezar aclarando una cosa: el mundo del desarrollo de software y el de las bases de datos no evolucionan igual. Mientras los desarrolladores compilan, versionan y despliegan sin mirar atrás, nosotros lidiamos con sistemas vivos. La base de datos no se borra y se vuelve a levantar como si fuera un contenedor. Cada ALTER TABLE toca datos reales. Y cada script mal planteado puede dejar un sistema en coma.
El enfoque de Database as Code nos ayuda a acercarnos al modelo DevOps. Usar herramientas como SSDT, Flyway, Liquibase, Redgate SQL Change Automation o, incluso, migraciones de Entity Framework, nos permite tener nuestros objetos versionados, controlar los cambios y desplegar de forma coherente. Hasta aquí, todo bien.
Pero claro, la teoría no menciona qué pasa cuando hay diferencias de collation entre entornos, cuando un índice tarda 45 minutos en crearse o cuando un trigger olvidado lanza una tormenta de inserts en cascada. Eso no lo arregla ningún pipeline.
Por eso, antes de lanzarnos a automatizar, necesitamos tener una estrategia de cambios bien pensada, un control de versiones sólido y, sobre todo, scripts que no se limiten a “funcionar en desarrollo”. El típico CREATE TABLE que nadie probó con un insert de 10 millones de filas no es infraestructura como código: es una amenaza.
Automatización con cabeza: lo que sí y lo que no en DevOps
No todo se debe automatizar. Sí, lo he dicho. Y lo repito. Hay tareas que siguen necesitando supervisión humana porque los datos no perdonan errores.
Automatiza los despliegues de cambios de esquema cuando están bien versionados y han pasado por entornos intermedios. Automatiza los backups, los restores de prueba, las revisiones de espacio en disco y las tareas de mantenimiento. Automatiza las revisiones de cumplimiento de convenciones con linting de scripts. Incluso automatiza los unit tests con tSQLt si tienes valor.
Pero no automatices, por ejemplo, la ejecución de un DROP COLUMN en producción sin que nadie revise qué otras vistas o procedimientos dependían de ella. Tampoco automatices sin revisión los despliegues que incluyen cambios destructivos o transformaciones masivas de datos. Y por supuesto, no pongas en un pipeline un script que actualiza 300 millones de registros en una tabla sin particiones y sin índices adecuados. Eso no es DevOps. Eso es sabotaje con CI/CD.
Porque sí, puedes tener despliegues automáticos cada cinco minutos. Pero si lo que despliegas son bombas lógicas, lo que estás haciendo no es integración continua: es desastre continuo.
DevOps si, pero con backups
Convertir la base de datos en código es un avance necesario. Repositorio Git, revisiones con Pull Requests, validaciones automáticas, historial de cambios… todo eso mejora la calidad y la trazabilidad. Nos permite dormir un poco más tranquilos. Por algo SSMS 21 incorpora soporte Git.
Pero ojo: base de datos como código no significa que los datos también lo sean. Los objetos son versionables. Los datos no lo son. No de la misma forma.
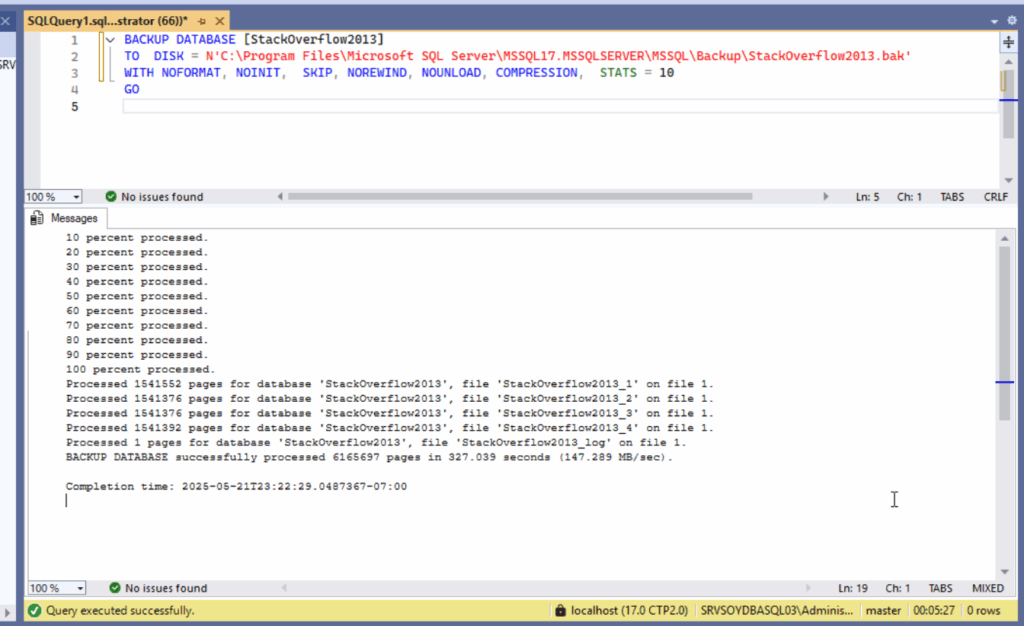
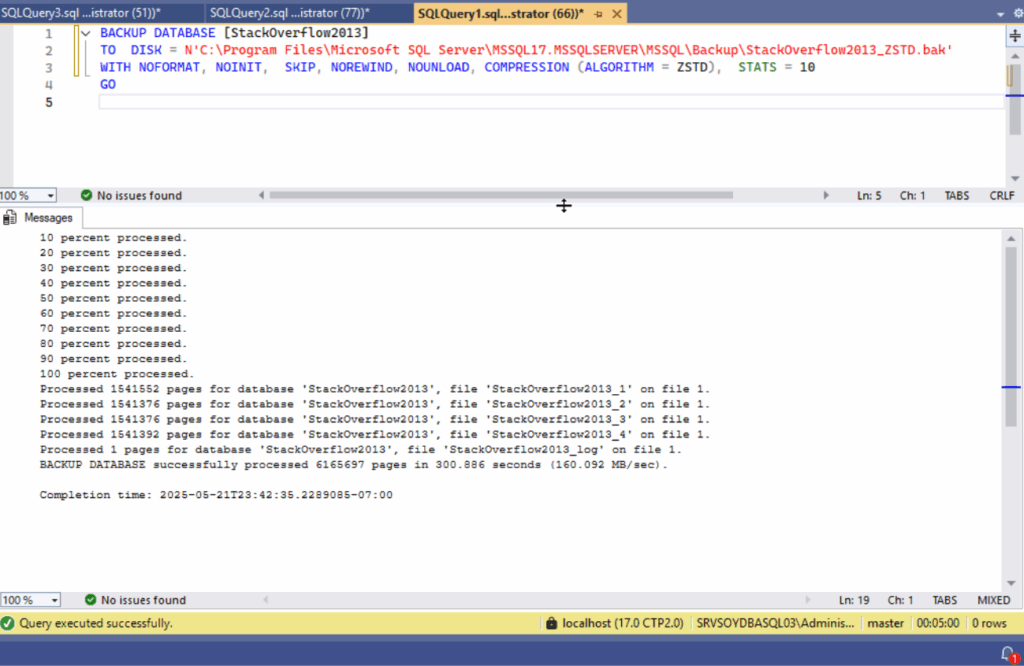
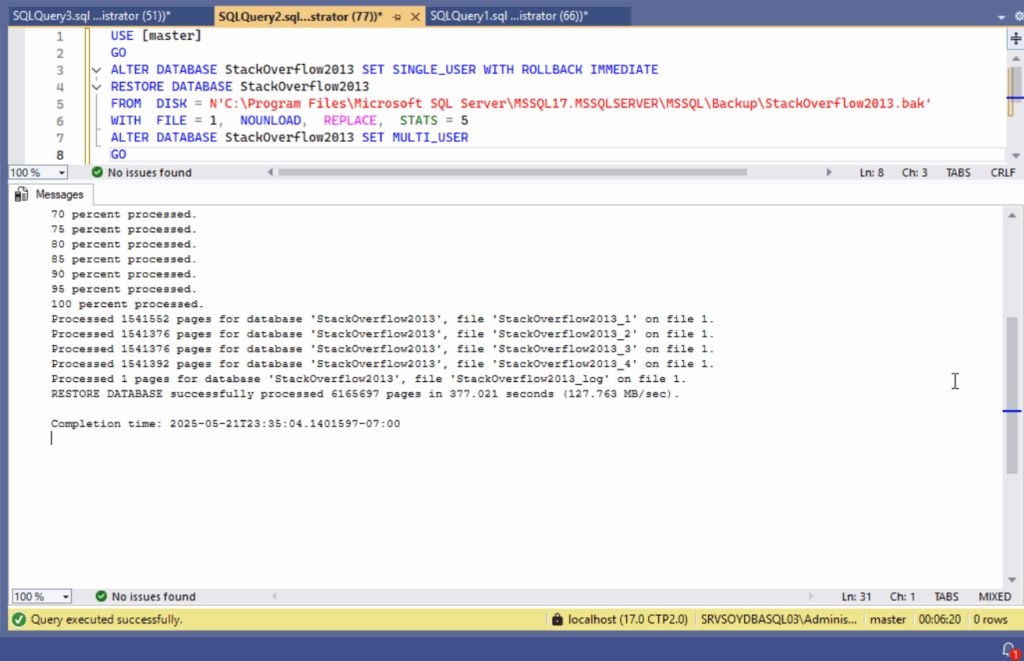
Por eso, ningún pipeline que toque la base de datos debería existir sin un buen backup previo. Y no, no vale con el backup nocturno. Un BACKUP DATABASE justo antes del despliegue, con nombre identificable y retención clara. Si algo va mal, hay que poder volver atrás. Nada de rezar a San Point-in-Time-Restore.
Además, si versionamos la base de datos, también hay que versionar los scripts de recuperación. ¿Qué haces si se despliega una función que rompe una lógica crítica? ¿Esperar a que el desarrollador vuelva de comer? No. Hay que tener plan B. Y plan C.
Roles y responsabilidades: DevOps no sustituye al DBA
En algunos modelos DevOps mal entendidos, parece que el DBA es prescindible. “Ya tenemos pipelines”, dicen. Claro. Y también tienes un coche, pero no han desaparecido los talleres mecánicos porque ahora sabes cambiar una rueda.
El rol del DBA en DevOps es más importante que nunca. Porque ahora, además de saber mantener sistemas estables, necesitamos saber cómo se integran en procesos automáticos, cómo se controlan los cambios, cómo se auditan los scripts y cómo se asegura la integridad del sistema en cada paso.
El DBA no solo ejecuta. Diseña el flujo. Revisa los PR. Define los checks de calidad. Valida la coherencia entre entornos. Y, sobre todo, es quien entiende que los datos no son líneas de código: son el corazón del negocio. Si fallan, no hay rollback que salve la reputación.
¿Y si todo explota igual?
Spoiler: alguna vez explotará. No importa lo bueno que sea tu pipeline. Alguien olvidará algo. Un script fallará. Una tabla no tendrá stats. Un índice nuevo matará el plan de ejecución.
Lo importante es que cuando eso pase, tengas herramientas para detectar, reaccionar y recuperar rápido. Logging detallado. Monitores activos. Backups listos. Versionado claro. Y sobre todo, un equipo que sepa que los despliegues no son cosa del azar, sino de la preparación. Herramientas como la de Four9s (sponsor de nuestros eventos online mensuales) ayudan a monitorizar estos cambios.
Porque en DevOps, como en SQL Server, todo funciona… hasta que no.
Conclusión
Integrar SQL Server en un entorno DevOps no es imposible, pero tampoco es trivial. Exige entender los riesgos, planificar con cabeza y automatizar sin perder el control. Versionamos código, sí. Pero protegemos datos. Y eso no se hace con fe ciega en YAMLs.
No somos un estorbo para la agilidad. Somos los que impedimos que se despliegue una migración irreversible a las 18:00 del viernes. Así que, si vamos a vivir en este nuevo mundo de CI/CD, vivamos con dignidad. Con backups. Con validaciones. Y con esa sospecha saludable de que un script sin revisar es una granada sin anilla.
El amor entre DevOps y SQL Server existe. Pero como todo amor real, necesita trabajo, comunicación y saber cuándo decir: “Esto mejor lo revisamos antes de darle al botón.”
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!