En nuestro anterior post hablamos sobre SQL Server Profiler y sus trazas y comentábamos que uno de sus usos puede ser el de auditoría ya que registra todos los eventos sobre nuestros servidores SQL Server. Sin embargo su elevado consumo de recursos no lo hace la solución más ideal para esta función. Y es que, SQL Server implementa una auditoría nativa mucho más potente con menor coste de recursos que la hacen la herramienta ideal. Configurar auditorías en SQL Server no solo nos va a ayudar a supervisar la actividad y los cambios, sino que también es un proceso clave en nuestra estrategia de protección de datos y cumplimiento normativo. En este artículo, voy a tratar de explicarte cómo puedes configurar eficazmente estas auditorías, optimizando cada aspecto para obtener el máximo beneficio.
¿Qué es la Auditoría de SQL Server?
La auditoría de SQL Server es un mecanismo que permite registrar y rastrear actividades y eventos dentro de nuestras instancias de SQL Server. La auditoría puede ser configurada para capturar una variedad de eventos, desde inicios de sesión hasta cambios en la configuración del servidor. Con estos registros, podemos realizar un seguimiento detallado de quién hizo qué y cuándo, lo que es vital para la seguridad y el cumplimiento normativo.
Tipos de Auditoría de SQL Server
SQL Server proporciona dos enfoques principales para la auditoría: la auditoría de instancia y la auditoría de base de datos. Cada uno tiene sus características específicas y se aplica en diferentes contextos según los requisitos de seguridad y cumplimiento por lo que no son excluyentes.
La auditoría de instancia se enfoca en eventos que afectan a toda la instancia de SQL Server, no solo a bases de datos individuales. Es ideal para capturar eventos que tienen un impacto global en el servidor y para mantener una vista general sobre la actividad de toda la instancia. Su uso principal es registrar el cumplimiento de políticas de seguridad como la gestión de accesos y el control de cambios en la configuración del servidor o de la instancia. Para ello, captura eventos que afectan a toda la instancia, como inicios de sesión, cambios en la configuración del servidor, y operaciones de mantenimiento. También permite registrar eventos de alto nivel que impactan el funcionamiento de la instancia.
La auditoría de base de datos se centra en eventos que ocurren dentro de una base de datos específica. Es ideal para capturar eventos relacionados con las operaciones de datos y la estructura de la base de datos, proporcionando un nivel de detalle más granular. Como hemos dicho, captura eventos a nivel de base de datos, como modificaciones en los datos, cambios en los objetos, y accesos a datos y nos permite definir qué operaciones se auditan en tablas, esquemas o procedimientos almacenados específicos. Se usa principalmente para registrar operaciones como inserciones, actualizaciones y eliminaciones, es decir, control de cambios y para monitorizar y registrar el acceso a datos sensibles o críticos dentro de una base de datos.
Auditoría de Instancia en SQL Server
Ya hemos visto que la auditoría a nivel de instancia nos permite capturar eventos que afectan a toda la instancia de SQL Server, independientemente de las bases de datos individuales. Este enfoque es útil para registrar eventos que ocurren a nivel de servidor, como cambios en la configuración del servidor o inicios de sesión.
Pasos para Configurar una Auditoría de Instancia
Primero, debemos definir una auditoría que especificará qué eventos se registrarán y cómo se almacenarán los resultados. Esto se hace mediante el SQL Server Management Studio (SSMS) o mediante Transact-SQL (T-SQL).
Usando SSMS:
En SSMS, navegamos a Seguridad > Auditorías.
Hacemos clic derecho en Auditorías y seleccionamos Nueva Auditoría.
En la ventana de propiedades, configuramos la ubicación del archivo de auditoría, que puede ser un archivo de registro, un archivo de eventos o un registro de la aplicación.
Establecemos las opciones necesarias, como el tamaño máximo del archivo y la política de retención.
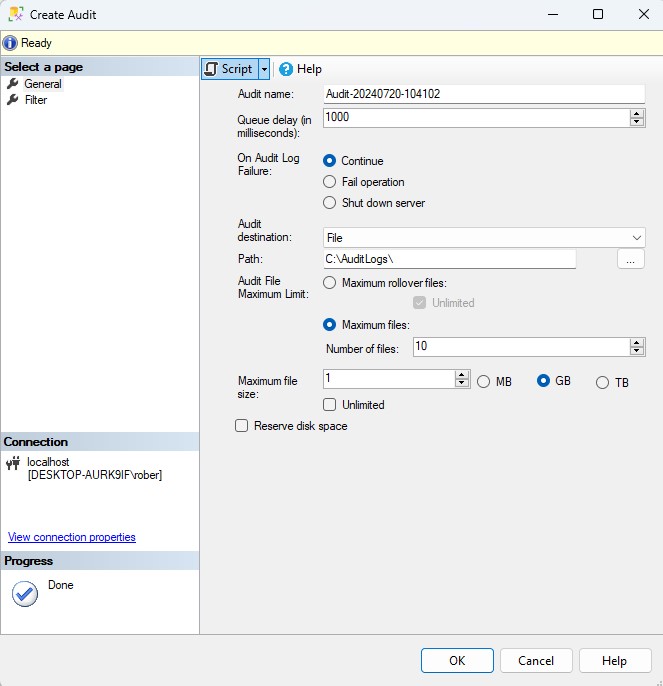
Usando T-SQL:
USE [master]
GO
CREATE SERVER AUDIT [Audit-20240720-104102]
TO FILE
( FILEPATH = N'C:\AuditLogs\'
,MAXSIZE = 1 GB
,MAX_FILES = 10
,RESERVE_DISK_SPACE = OFF
) WITH (QUEUE_DELAY = 1000, ON_FAILURE = CONTINUE)
GOUna vez creada la auditoría, debemos definir qué eventos específicos deseamos capturar. Esto se hace mediante la creación de especificaciones de auditoría.
Usando SSMS:
Navegamos a Seguridad > Especificaciones de Auditoría.
Hacemos clic derecho en Especificaciones de Auditoría y seleccionamos Nueva Especificación de Auditoría.
Seleccionamos la auditoría previamente creada y definimos los eventos que deseamos capturar, como Inicios de sesión o Cambios en la configuración.
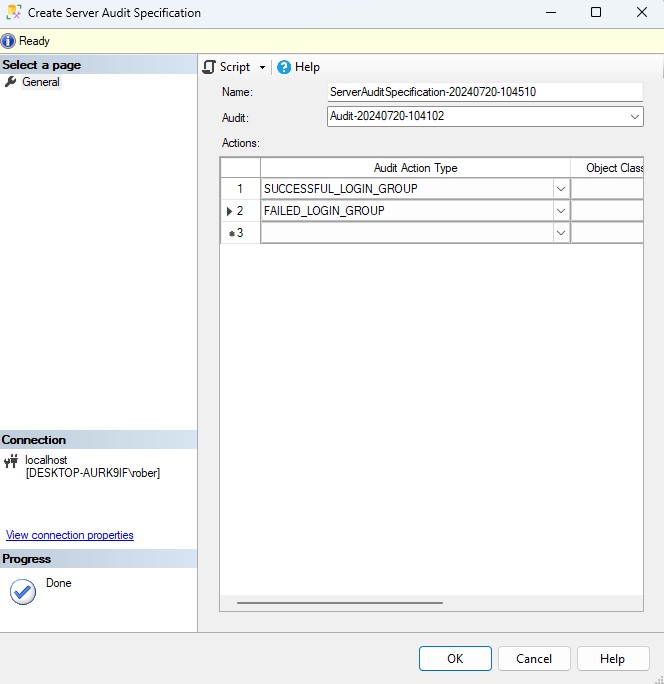
Usando T-SQL:
USE [master]
GO
CREATE SERVER AUDIT SPECIFICATION [ServerAuditSpecification-20240720-104510]
FOR SERVER AUDIT [Audit-20240720-104102]
ADD (SUCCESSFUL_LOGIN_GROUP),
ADD (FAILED_LOGIN_GROUP)
GOFinalmente, habilitamos tanto la auditoría como las especificaciones para comenzar a capturar los eventos configurados desde SSMS con clic derecho del ratón sobre los objetos y habilitar.
Usando T-SQL:
ALTER SERVER AUDIT [Audit-20240720-104102] WITH (STATE = ON)
GO
ALTER SERVER AUDIT SPECIFICATION [ServerAuditSpecification-20240720-104510] WITH (STATE = ON)Auditoría de Base de Datos en SQL Server
A diferencia de la anterior, la auditoría a nivel de base de datos se centra en registrar eventos que ocurren dentro de una base de datos específica. Este nivel de detalle es fundamental para monitorear actividades relacionadas con el contenido y los objetos de la base de datos.
Pasos para Configurar una Auditoría de Base de Datos
Al igual que con la auditoría a nivel de instancia, primero debemos crear una auditoría que especifique dónde se almacenarán los registros. Esta auditoría se crea a nivel de instancia y podemos usar la misma que teníamos antes, en la base de datos solo vamos a crear las especificaciones.
Usando SSMS:
Navegamos a la base de datos en Seguridad > Especificaciones de Auditoría.
Hacemos clic derecho en Especificaciones de Auditoría y seleccionamos Nueva Especificación de Auditoría.
Configuramos los eventos específicos, como operaciones de datos o cambios en los objetos.
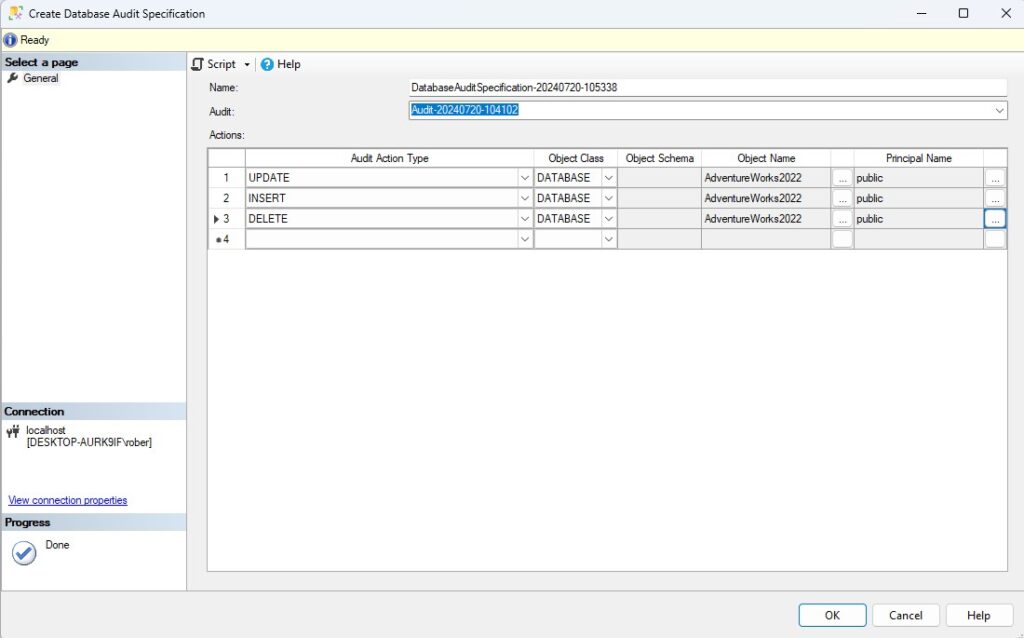
Usando T-SQL:
USE [AdventureWorks2022]
GO
CREATE DATABASE AUDIT SPECIFICATION [DatabaseAuditSpecification-20240720-105338]
FOR SERVER AUDIT [Audit-20240720-104102]
ADD (UPDATE ON DATABASE::[AdventureWorks2022] BY [public]),
ADD (INSERT ON DATABASE::[AdventureWorks2022] BY [public]),
ADD (DELETE ON DATABASE::[AdventureWorks2022] BY [public])
GOIgual que antes, activamos la auditoría y las especificaciones para comenzar a registrar los eventos.
Usando T-SQL:
ALTER DATABASE AUDIT SPECIFICATION [DatabaseAuditSpecification-20240720-105338] WITH (STATE = ON);Auditoría vs SQL Server Profiler
Como vimos en el pasado post, SQL Server Profiler es otra herramienta que, aunque no se usa para auditorías a largo plazo, sigue siendo relevante para capturar eventos en tiempo real y para el análisis detallado de sesiones y transacciones. Vamos a comparar esta herramienta con las auditorías de SQL Server en términos de capacidades y usos.
Alcance y propósito
SQL Server Profiler captura eventos en tiempo real para el análisis detallado de sesiones y transacciones. Es ideal para depurar problemas y monitorear el rendimiento en tiempo real ya que proporciona una vista instantánea de la actividad de la base de datos. Por el contrario, las auditorías de SQL Server registran eventos a lo largo del tiempo, permitiendo un seguimiento extensivo y cumplimiento normativo. Son más adecuadas para el cumplimiento de regulaciones y para proporcionar informes detallados sobre eventos históricos ya que capturan eventos críticos y permiten su almacenamiento en archivos o registros para un análisis posterior.
Persistencia
Los datos capturados por Profiler son temporales y se almacenan en memoria mientras se realiza el seguimiento. Aunque se puede salvar un archivo de traza, este no está diseñado para almacenamiento a largo plazo o para el cumplimiento normativo. Las auditorías de SQL Server sin embargo si almacenan los eventos en archivos o registros, lo que permite un almacenamiento prolongado y una revisión a largo plazo. Además facilitan la conservación de datos históricos necesarios para el cumplimiento regulatorio.
Rendimiento
Como ya vimos también, SQL Server Profiler puede impactar el rendimiento del servidor durante la captura de eventos debido a la sobrecarga de recursos. lo que no lo hace la herramienta ideal para sesiones largas y poco específicas donde el rendimiento es crítico. En este sentido, las auditorías de SQL Server tienen un menor impacto en el rendimiento, especialmente cuando se configuran para capturar solo eventos esenciales. Además nos permiten ajustar la granularidad de la auditoría para minimizar la sobrecarga.
Usabilidad
SQL Server Profiler nos ofrece una interfaz gráfica para configurar y visualizar eventos en tiempo real pero requiere de una comprensión avanzada para interpretar los eventos capturados. Las auditorías de SQL Server que configuramos a través de SSMS o T-SQL, proporcionan una forma estructurada y más amigable de registrar eventos para que puedan ser consumidos por auditores y técnicos de ciberseguridad. Las especificaciones de auditoría permiten un control preciso sobre qué eventos se registran y cómo se almacenan.
Conclusión
Configurar auditorías en SQL Server, tanto a nivel de instancia como de base de datos, es fundamental para mantener un control exhaustivo sobre nuestras bases de datos y garantizar la seguridad y el cumplimiento. A través de la correcta configuración de auditorías y especificaciones, podemos registrar eventos críticos y analizar el acceso y las modificaciones a nuestros datos. Aunque el proceso puede parecer complejo, seguir estos pasos nos permite implementar una estrategia de auditoría efectiva que proporciona una visión detallada y precisa de la actividad en nuestras instancias y bases de datos. Al final, una auditoría bien configurada es una herramienta poderosa que fortalece nuestra postura de seguridad y facilita el cumplimiento normativo.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta




