Hoy me he encontrado con un caso que es más habitual del que me gustaría y quería compartirlo con vosotros y ver qué podemos aprender de él. Estaba revisando el servidor de un cliente que nunca ha tenido un DBA, era un SQL Server 2022 Standard que había montado su equipo de IT. El caso es que, aun siendo un SQL Server 2022, todas las bases de datos estaban en nivel de compatibilidad 100, es decir en el modo de funcionamiento propio de SQL Server 2008. Al preguntar, me han contado que desde su primer SQL Server 2008 su informático siempre había ido aplicando las actualizaciones y subidas de versiones cuando era necesario pero claro, no sabían que había que cambiar nada en las bases de datos.
Este caso que os cuento no es excepcional, y muchos administradores de bases de datos han pasado por situaciones similares. Tener bases de datos en un SQL Server moderno pero con un nivel de compatibilidad antiguo es más común de lo que parece. Pero, ¿qué implica esto realmente? ¿Por qué es importante gestionar correctamente los niveles de compatibilidad? Vamos a profundizar en este tema y en las consideraciones clave antes de realizar cualquier cambio.
¿Qué es el Nivel de Compatibilidad en SQL Server?
El nivel de compatibilidad de una base de datos en SQL Server define qué conjunto de características y comportamientos del motor de base de datos están habilitados para esa base de datos en particular. Microsoft SQL Server introduce constantemente nuevas funcionalidades y mejoras en el motor de consulta con cada versión. Sin embargo, para evitar problemas de compatibilidad con aplicaciones antiguas, permite mantener una base de datos funcionando con un conjunto de reglas de versiones anteriores.
Por ejemplo, una base de datos con nivel de compatibilidad 100 (SQL Server 2008) ejecutada en un SQL Server 2022 seguirá comportándose en muchos aspectos como si estuviera en SQL Server 2008. Esto puede parecer una buena idea para garantizar que las consultas y procedimientos almacenados antiguos sigan funcionando sin problemas, pero también significa renunciar a muchas mejoras de rendimiento y nuevas funcionalidades del motor de base de datos.
¿Por qué es importante el Nivel de Compatibilidad?
El nivel de compatibilidad afecta aspectos fundamentales del comportamiento de SQL Server, incluyendo el optimizador de consultas, nuevas funciones y sintaxis de T-SQL y mejoras en la seguridad y el rendimiento general.
Como sabéis, SQL Server introduce mejoras constantes en el optimizador de consultas en cada nueva versión del producto. Mantener un nivel de compatibilidad antiguo significa que las consultas podrían no beneficiarse de los nuevos algoritmos y estrategias de ejecución de consultas. Además, algunas funciones y tipos de datos más modernos pueden no estar disponibles en niveles de compatibilidad antiguos.
En cuanto a seguridad, Microsoft mejora continuamente la seguridad en SQL Server, y algunas de estas mejoras solo están disponibles en niveles de compatibilidad más recientes. Lo mismo pasa con el rendimiento, características como Batch Mode on Rowstore, Adaptive Query Processing, Memory Grant Feedback, entre muchas otras, solo están habilitadas en niveles de compatibilidad más recientes.
El cambio clave con el Nivel de Compatibilidad 120 (SQL Server 2014)
Uno de los cambios más significativos en la historia de los niveles de compatibilidad de SQL Server ocurrió con SQL Server 2014 (Nivel 120). Microsoft rediseñó por completo el comportamiento del optimizador de consultas con la introducción del nuevo estimador de cardinalidad.
¿Qué es el estimador de cardinalidad y por qué es importante?
El estimador de cardinalidad es el componente del optimizador de consultas que predice cuántas filas se van a procesar en cada paso de una consulta. Estas predicciones, basadas entre otras cosas en las estadísticas, influyen directamente en la selección de planes de ejecución eficientes.
Con SQL Server 2014, Microsoft cambió la forma en que se estiman las filas, lo que en muchos casos mejoró el rendimiento, pero en otros, los menos, generó degradaciones inesperadas. Por eso, al cambiar el nivel de compatibilidad de 110 (SQL Server 2012) a 120 (SQL Server 2014), algunos planes de ejecución cambiaron drásticamente. Si tu base de datos aún se encuentra en un nivel de compatibilidad antiguo (110 o inferior), al actualizar a 120 o superior, es crucial revisar los planes de ejecución antes de aplicar el cambio en producción.
Impacto del Nivel de Compatibilidad 120 en los planes de mantenimiento
Otro cambio relevante con SQL Server 2014 y su nivel de compatibilidad 120 fue cómo se comportaban los planes de mantenimiento. Antes de SQL Server 2014, muchas bases de datos dependían de planes de mantenimiento que ejecutaban reconstrucción y reorganización de índices, estadísticas de actualización y otras tareas rutinarias de mantenimiento. Sin embargo, al actualizar a SQL Server 2014 con nivel de compatibilidad 120, muchos de estos procesos cambiaron significativamente debido a un nuevo comportamiento en la actualización de estadísticas
En versiones anteriores, las estadísticas se actualizaban con una heurística más básica basada en el número de cambios en los índices. A partir de SQL Server 2014, Microsoft introdujo un algoritmo mejorado que ajusta automáticamente la frecuencia de actualización de estadísticas en función de la variabilidad de los datos. Esto significa que algunos planes de mantenimiento antiguos pueden volverse ineficientes, ya que las estadísticas pueden actualizarse con menor frecuencia de lo esperado.
Cambios en la fragmentación de índices
También, antes de SQL Server 2014, los DBA solíamos programar reconstrucción y reorganización de índices en intervalos fijos. Sin embargo, con el nuevo estimador de cardinalidad, algunas consultas que antes se beneficiaban de la reconstrucción de índices ya no requieren mantenimiento tan frecuente, mientras que otras pueden necesitar ajustes más específicos.
Nuevo comportamiento en las esperas de consultas y la concesión de memoria
SQL Server 2014 introdujo Memory Grant Feedback, que ajusta dinámicamente la memoria asignada a las consultas. Este cambio afectó la manera en que los planes de mantenimiento deben ejecutarse en bases de datos de gran tamaño, ya que ahora SQL Server aprende con el tiempo y puede mejorar la asignación de memoria en ejecuciones repetitivas. Sin embargo, si por una actualización de estadísticas o mantenimiento de índices el plan se recompila todos esos cálculos ya no valen.
¿Cómo adaptar los planes de mantenimiento?
Si decides actualizar el nivel de compatibilidad a 120 o superior, es recomendable revisar y adaptar los planes de mantenimiento de la base de datos para evitar ineficiencias. Lo primero que tienes que hacer es revisar la estrategia de actualización de estadísticas.
En lugar de una actualización forzada en cada ciclo, es mejor (generalmente) dejar que SQL Server maneje esto dinámicamente. Por supuesto, siempre evalúa el impacto real en las consultas antes de aplicar actualizaciones manuales con UPDATE STATISTICS.
En cuanto a la reconstrucción de índices podemos utilizar la DMV sys.dm_db_index_physical_stats para analizar si realmente es necesario reconstruir índices. Y, como hemos dicho siempre que hablamos de mantenimiento de índices, ciertas tablas pueden beneficiarse más de una reorganización en lugar de una reconstrucción completa. Tendremos que valorar el nivel de mantenimiento en función de la fragmentación del índice.
En cualquier caso, Query Store puede ayudarnos a detectar cambios drásticos en planes de ejecución antes y después de cambiar el nivel de compatibilidad. Podemos incluso usar la opción de force plan si una consulta se ve afectada negativamente tras el cambio.
Consideraciones antes de cambiar el Nivel de Compatibilidad
A modo resumen de lo que llevamos hasta aquí, antes de modificar el nivel de compatibilidad de una base de datos, debemos hacer una serie de verificaciones y pruebas para asegurarnos de que el cambio no afectará negativamente a la operativa.
- Analizar dependencias y compatibilidad con las aplicaciones
- Revisar consultas y procedimientos almacenados
- Ejecutar pruebas de rendimiento en un entorno de pruebas
- Usar Query Store para comparar planes de ejecución
- Ajustar planes de mantenimiento según el nuevo comportamiento de SQL Server
Cómo cambiar el Nivel de Compatibilidad
Para cambiar el nivel de compatibilidad de una base de datos en SQL Server, podemos hacerlo desde las propiedades de la base de datos en SSMS en la pestaña “Opciones”. También lo puedes hacer utilizando la siguiente instrucción T-SQL:
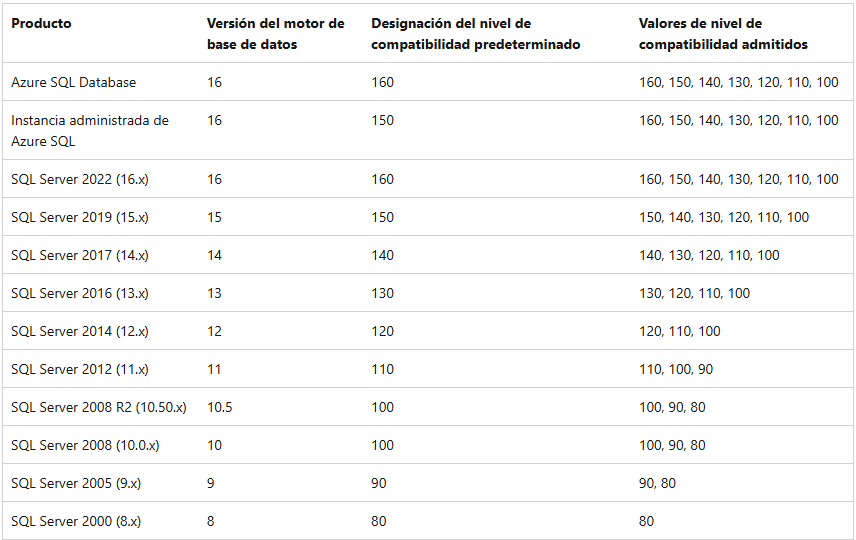
ALTER DATABASE NombreBaseDatos SET COMPATIBILITY_LEVEL = 150; En este ejemplo 150 es para SQL Server 2019, los niveles de compatibilidad son los siguientes:
También podemos verificar el nivel de compatibilidad actual para todas las bases de datos con esta consulta:
SELECT name, compatibility_level FROM sys.databases Conclusión
El nivel de compatibilidad en SQL Server no es solo una configuración más; afecta directamente al rendimiento, comportamiento del optimizador de consultas y eficiencia de los planes de mantenimiento. Con el cambio introducido en SQL Server 2014, muchas bases de datos experimentaron transformaciones en sus planes de ejecución y rutinas de mantenimiento. Antes de hacer cualquier modificación, es clave realizar pruebas exhaustivas y ajustar estrategias de optimización. Si vamos a actualizar, hagámoslo bien y con un plan claro para minimizar riesgos y aprovechar al máximo las mejoras de SQL Server.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!