Llevamos los dos últimos artículos hablando de los índices de texto completo (FullText) en SQL Server. Hemos aprendido lo qué son y cómo se administran, sin embargo hay un tema, quizá lo más importante, que habíamos dejado para el final. Y no es otro que su uso y el impacto en el rendimiento. ¿Realmente merece la pena este tipo de índices? Vamos a descubrirlo juntos.
Cláusulas específicas para buscar en índices FullText
Normalmente cuando tenemos que buscar texto dentro de una columna en SQL usamos la cláusula LIKE y nos apoyamos en el carácter % que hace de comodín. Sin embargo, cuando hemos añadido una columna a un índice FullText se nos habilitan otras opciones de búsqueda como son CONTAINS, FREETEXT, CONTAINSTABLE y FREETEXTTABLE. Aunque todas son cláusulas para filtrar por texto tienen algunas diferencias que debemos conocer.
CONTAINS: La Precisión
CONTAINS es una cláusula que permite realizar búsquedas de texto completo en columnas de tipo char, varchar o text dentro de SQL Server. Esta cláusula es especialmente poderosa por su capacidad de buscar palabras o frases específicas, e incluso formas de una palabra, dentro de un texto. Por ejemplo, si queremos encontrar todos los registros que contengan la palabra «optimización», CONTAINS nos facilitará esta tarea con gran precisión.
FREETEXT: La Relevancia
Por otro lado, FREETEXT es menos estricta que CONTAINS y se utiliza para buscar términos que sean «similares» o relacionados con el texto de la consulta, sin necesidad de que sean exactos. Es decir, FREETEXT no solo nos va a devolver los campos que contengan esa palabra sino también los que contengan algún sinonimo. Esto es ideal para cuando la intención es más importante que la coincidencia literal, permitiendo una búsqueda más «libre» y basada en la relevancia.
CONTAINSTABLE: Resultados Ordenados
CONTAINSTABLE es una función que extiende las capacidades de CONTAINS, devolviendo una tabla de resultados con las filas que coinciden con la búsqueda, junto con un rango de relevancia, conocido como «rank». Esto permite no solo encontrar las coincidencias, sino también ordenarlas por su relevancia, facilitando la identificación de los resultados más pertinentes.
FREETEXTTABLE: Mayor Flexibilidad en la Búsqueda
Similar a CONTAINSTABLE, FREETEXTTABLE aplica los principios de FREETEXT a una tabla de resultados clasificables. Esta función es crucial cuando buscamos entender el contexto general de los términos de una búsqueda dentro de un conjunto de datos, proporcionándonos una clasificación que nos ayuda a discernir la importancia relativa de cada registro encontrado.
Sintaxis y ejemplos de la búsqueda de texto
Ahora que ya sabemos las diferencias entre las distintas búsquedas vamos a ver como se usan en un caso práctico. Para esto vamos a usar la base de datos de ejemplo de Microsoft AdventureWorks. Como ya sabréis (o no, no importa) esta base de datos tiene datos de ejemplo de una tienda de bicicletas. Vamos a buscar, entonces, por la palabra rendimiento en la tabla de descripciones de los productos. Lamentablemente no tenemos una base de datos AdventureWorks con datos en español así que tendremos que buscar en inglés pero es solo por esto. Vosotros tendreis que buscar en el idioma que tengáis vuestros datos y, muy importante, tendréis que haber creado directamente el índice en ese idioma (si no sabéis como se hace os lo conté aquí).
Vamos a hacer la misma búsqueda con todas las posibles opciones que hemos visto antes:
select *
from Production.ProductDescription
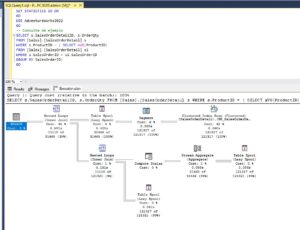
where Description like '%Performance%'
select *
from Production.ProductDescription
where CONTAINS (Description,'"Performance*"')
select *
from Production.ProductDescription
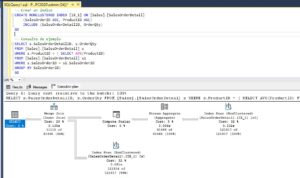
where FREETEXT (Description, '"Performance"')
SELECT *
FROM Production.ProductDescription AS FT_TBL
INNER JOIN CONTAINSTABLE (Production.ProductDescription, Description, '"Performance*"' ) AS KEY_TBL
ON FT_TBL.ProductDescriptionID = KEY_TBL.[KEY]
SELECT *
FROM Production.ProductDescription AS FT_TBL
INNER JOIN FREETEXTTABLE(Production.ProductDescription, Description, '"Performance"' ) AS KEY_TBL
ON FT_TBL.ProductDescriptionID = KEY_TBL.[KEY] Podríamos entrar aquí y ahora en todas las opciones avanzadas de filtrado que incluyen cada una de estas opciones frente al tradicional y simple LIKE pero, convertiría este artículo en eterno y tampoco es el objetivo del post. Si queréis profundizar más tenéis la documentación oficial y si queréis que veamos aquí algunos ejemplos podeis pedirmelo y lo haremos.
Rendimiento en las búsquedas de texto
Vamos ahora a comparar el rendimiento de las consultas anteriores. Para que el ejemplo tenga más relevancia he creado aproximadamente unos 200.000 registros en la tabla en lugar de los menos de 800 que trae cuando restauramos la base de datos. No sufráis por eso que después de eso también he actualizado los índices y estadísticas de la tabla. Esto nos va a permitir verificar mejor las diferencias.
Estos han sido los resultados ejecutando las anteriores consultas:
| Cláusula | Tiempo de CPU | Lecturas lógicas | Porcentaje del plan |
| LIKE | 781 milisegundos | 4365 páginas | 77% |
| CONTAINS | < 1 milisegundo | 278 páginas | 5% |
| FREETEXT | < 1 milisegundo | 278 páginas | 7% |
| CONTAINSTABLE | < 1 milisegundo | 278 páginas | 5% |
| FREETEXTTABLE | < 1 milisegundo | 278 páginas | 7% |
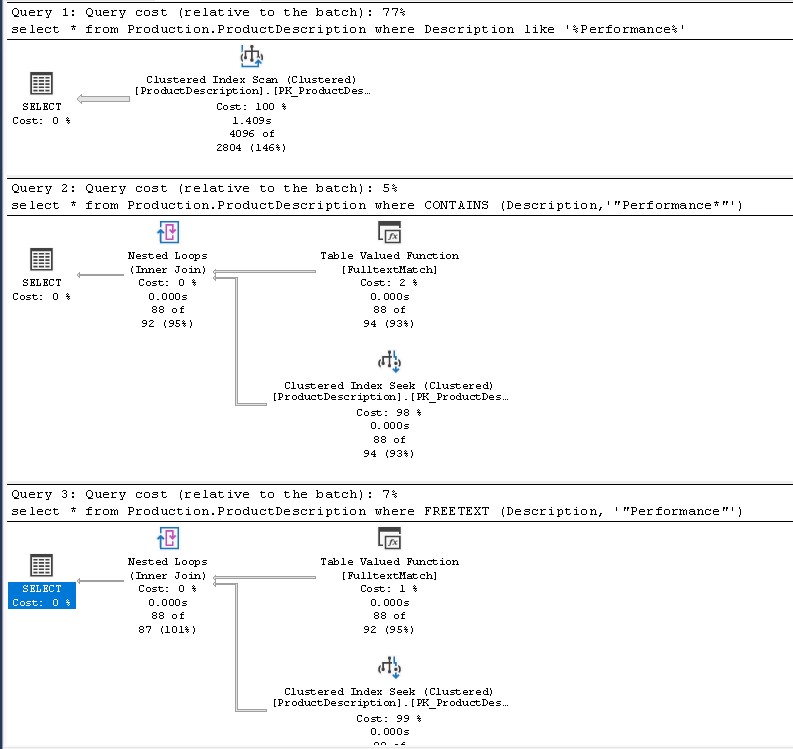
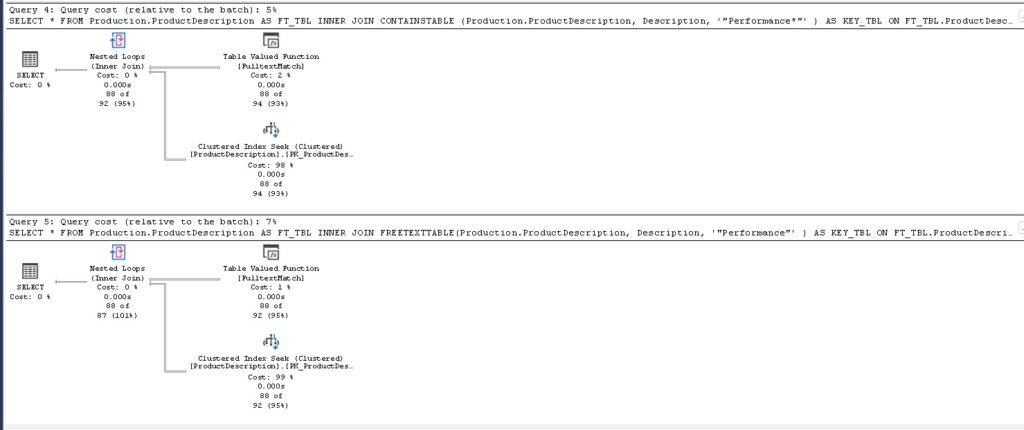
Las conclusiones son obvias, el mayor consumo de recursos es con Like, cuando no se usa el índice FullText tardando 780 veces más en completar la consulta y leyendo 34 Mb de información (4365 páginas * 8Kb por página / 1024 = 34 Mb) frente a los solo 2 Mb de información que se leen las consultas que sí hacen uso del índice de texto completo.
Rendimiento en escrituras
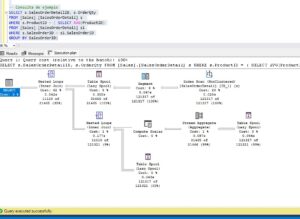
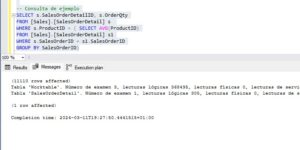
Ya hemos hablado en varias ocasiones de esto pero no está de más recordarlo, los índices en SQL “no son gratis” y por no son gratis me refiero a que hay un precio a pagar por toda esta mejora de rendimiento en las lecturas. En concreto el precio a pagar es un gran empeoramiento de las escrituras. Para verificar hasta dónde es negativo este impacto en las escrituras he creado una tabla en mi SQL Server con la misma estructura que con la que estamos haciendo la prueba y con los mismos datos pero sin el índice de texto completo. Si que tiene el resto de los índices que tiene la tabla original (PK + Nonclustered). A continuación he insertado en las dos tablas los mismos 100.000 registros para medir los tiempos.
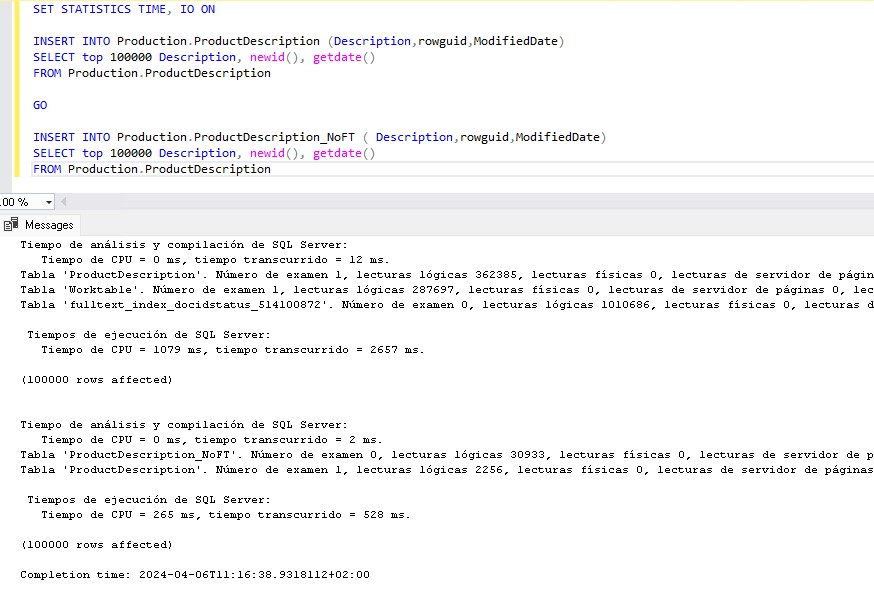
Como podéis ver en la imagen, el resultado de la inserción en la tabla sín índice FullText ha tardado 225 milisegundos frente a 1079 milisegundos en la tabla que tiene índice de texto completo. En cuanto a la información que se ha necesitado leer para hacer la inserción encontramos que para insertar en la tabla con FullText hemos tenido que leer 12,6 Gb de información mientras que para la que no tiene ese índice solo hemos tenido que leer 259,2 Mb.
Conclusión
Los índices de texto completo o FullText pueden ser un gran aliado en las consultas de lecturas, no tanto en las escrituras, donde nos pueden llegar a dar verdaderos problemas de rendimiento. Además, al contrario que en los índices normales donde su creación es transparente, para aprovechar la mejora de un índice FullText tendremos que adaptar nuestro código y usar las cláusulas específicas que usarán el índice.
Espero que esta serie de artículos te haya ayudado a comprender mejor los índices de texto completo y a poder analizar si son o no beneficiosos para tus escenarios de uso actuales y futuros. Como siempre, te animo a experimentar con estas técnicas y a explorar todas las posibilidades que ofrecen. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!