Continuamos con nuestra serie sobre soluciones de alta disponibilidad en SQL Server hablando de la replicación. La replicación en SQL Server es un mecanismo que permite distribuir y sincronizar datos entre diferentes bases de datos, ya sea en la misma instancia o en instancias separadas. La replicación puede tener varios objetivos, como mejorar el rendimiento, la disponibilidad, la escalabilidad o la seguridad de los datos.
Existen diferentes tipos de replicación en SQL Server, cada uno con sus propias características, ventajas y desventajas. En este artículo vamos a explicar los conceptos básicos de la replicación, los tipos que existen y las razones por las que se utiliza.
¿Qué es la replicación?
La replicación es una solución que nos permite mantener actualizados los datos entre diferentes bases de datos. La base de datos que contiene los datos originales se llama publicador, y las bases de datos que reciben las copias se llaman suscriptores. El publicador puede tener uno o varios suscriptores, y cada suscriptor puede recibir una copia completa o parcial de los datos del publicador.
Todo el proceso se realiza mediante agentes, que son procesos que se encargan de leer, distribuir y aplicar los cambios de los datos entre el publicador y los suscriptores. Los agentes pueden ejecutarse de forma continua o programada, según el tipo de implementación y las necesidades del negocio.
Los agentes utilizan una base de datos intermedia llamada distribuidor, que almacena los cambios de los datos del publicador hasta que son enviados a los suscriptores. El distribuidor puede estar en la misma instancia que el publicador o en una instancia separada.
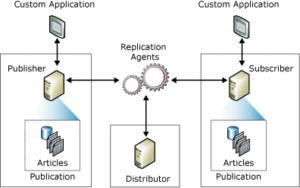
Un aspecto importante de esta solución es que se hace a nivel de objeto, es decir, se pueden seleccionar qué tablas, vistas, procedimientos almacenados u otros objetos se quieren replicar, sin tener que replicar toda la base de datos o la instancia. Esto permite tener un mayor control y flexibilidad sobre lo que se replica y cómo se replica. Además, se pueden aplicar filtros, transformaciones o reglas personalizadas para adaptar los datos y objetos replicados a las necesidades específicas de cada caso.
Tipos de replicación
Existen tres tipos principales de replicación en SQL Server según el nivel de detalle, la frecuencia y la dirección de los cambios que se quieren replicar. Elegiremos un tipo u otro de implementación en función de nuestras necesidades.
Replicación transaccional
Consiste en enviar los cambios de los datos del publicador a los suscriptores casi en tiempo real, después de cada transacción. Este modo de implementación es adecuado para escenarios en los que necesitamos una alta consistencia y disponibilidad de los datos. Tiene una serie de limitaciones como que todas las tablas tienen que tener PK o que no se puede modificar la estructura de las tablas que participan en la replicación.
Replicación de instantáneas (snapshot)
Consiste en enviar una copia completa de los datos del publicador a los suscriptores cada cierto tiempo. Este modo de implementación es adecuado para escenarios en los que los datos no cambian con mucha frecuencia o no necesitamos una sincronización inmediata, como por ejemplo en sistemas de reportes o análisis.
Replicación de mezcla (merge)
Consiste en combinar la replicación transaccional y la replicación de instantáneas, permitiendo que tanto el publicador como los suscriptores puedan modificar los datos y sincronizarlos periódicamente. Este modo de implementación es adecuado para escenarios en los que se requiere una alta escalabilidad y flexibilidad, como por ejemplo en sistemas distribuidos o móviles.
Ventajas y desventajas de la replicación
Ventajas
Como venimos viendo en los distintos artículos de esta serie, tener los datos replicados mejora el rendimiento al reducir la carga de trabajo en el publicador y permitir acceso de lectura desde diferentes ubicaciones.
Otra de las ventajas de la replicación es que mejora la disponibilidad al proporcionar redundancia y tolerancia a fallos en caso de que el publicador o alguno de los suscriptores no esté disponible. Además nos permite agregar más suscriptores según aumente la demanda lo que se traduce en una buena escalabilidad. Por último, mejora la seguridad al permitir aplicar diferentes niveles de acceso a los datos para cada suscriptor.
Inconvenientes
Sin embargo, la replicación también tiene algunas desventajas. Aumenta la complejidad al requerir una configuración y administración más cuidadosa y detallada. Por otro lado, aumenta el consumo de recursos al requerir más espacio en disco, memoria y red para almacenar y transmitir los datos.
Además, uno de los mayores inconvenientes de la replicación es el riesgo de inconsistencia o pérdida de datos si ocurren errores o conflictos durante el proceso de replicación. Por experiencia, es uno de los procesos en SQL Server con más tasa de error y con un mantenimiento complejo y, a veces, difícil de encontrar la causa de los problemas.
Relación vs Alta Disponibilidad
Como hemos podido ver, la replicación es una forma de lograr la alta disponibilidad. Sin embargo, la replicación no es lo mismo que la alta disponibilidad, ya que esta última implica otros aspectos como el balanceo de carga, el monitoreo, la recuperación ante desastres o el mantenimiento preventivo.
Tanto la replicación como las soluciones de alta disponibilidad buscan mejorar la confiabilidad y la continuidad del servicio minimizando las interrupciones o las pérdidas de datos. La replicación y la alta disponibilidad se complementan y se benefician mutuamente. Sin embargo, mientras que la replicación se enfoca en distribuir y sincronizar los datos, una solución de alta disponibilidad nos debe garantizar el funcionamiento del servicio. La replicación puede ser una parte de una solución de alta disponibilidad, pero no es suficiente por sí sola.
Conclusión
La replicación en SQL Server es un mecanismo poderoso y versátil que nos permite sincronizar datos entre diferentes bases de datos. Dependiendo del tipo de replicación elegido, se pueden obtener diferentes beneficios y desafíos. Como DBAs, debemos analizar las necesidades del negocio y las características de los datos antes de implementar una solución basada en la replicación. Asimismo, es importante entender la relación entre la replicación y la alta disponibilidad, y cómo ambas pueden contribuir a mejorar el servicio.
La replicación en SQL Server es un tema muy amplio y con muchas opciones de configuración y personalización. En este artículo solo hemos visto una introducción general a la teoría y el por qué de las cosas. Seguro que en futuros artículos hablaremos más en profundidad de este tema, aunque ya será fuera de esta serie. Como ya sabéis, podéis dejarme vuestras dudas y comentarios abajo, por Twitter o mail. ¡Hasta la próxima!