Continuamos con el tema de ayer sobre los índices de texto completo y hoy vamos a centrarnos en aspectos más prácticos. Si aún no has leído el artículo introductorio de ayer sobre los índices FullText te recomiendo que lo hagas antes de seguir con este para saber de lo que estamos hablando. Si ya leíste vamos a hacer un pequeño resumen para reforzar los conceptos clave. Los índices de texto completo o FullText son unos índices especiales que nos ayudarán en nuestras búsquedas sobre columnas con gran cantidad de texto. Además, tienen la particularidad de que se organizan en catálogos, aspecto clave para su creación y futuro mantenimiento.
Requisitos para crear un índice FullText
Para crear los índices FullText lo primero que necesitaremos será tener instalada la característica de SQL con la que trabajan, no tiene pérdida se llama FullText o Texto Completo dependiendo del idioma de nuestro instalador. Una vez instalada tenemos que asegurarnos de tener corriendo el servicio para la extracción de texto completo, tampoco tiene pérdida y lo localizaremos por su nombre rápidamente junto con el resto de servicios en el administrador de configuración de SQL Server.
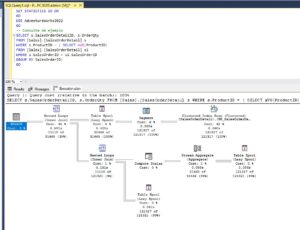
Una vez estemos seguros de que el servicio está instalado y en ejecución podremos proceder con la creación del catálogo que, recordad que es requisito imprescindible para este tipo de índices. Para crear el catálogo usaremos la sintaxis siguiente sintaxis:
CREATE FULLTEXT CATALOG NombreCatalogo;Para ver los catálogos existentes podemos hacerlo en SSMS, desplegando la carpeta almacenamiento dentro de la base de datos o con la siguiente consulta:
select * from sys.fulltext_catalogs
Creación de índices FullText
Una vez que cumplamos con los requisitos anteriores estaremos ya preparados para crear nuestro índice FullText. Tenemos que saber que podemos crear índices de texto completo tanto en tablas como en vistas indexadas pero solo uno por tabla (o vista). El índice de cada tabla podrá contener hasta 1024 columnas. La sintaxis de creación es la siguiente:
CREATE FULLTEXT INDEX ON table_name
[ ( { column_name
[ TYPE COLUMN type_column_name ]
[ LANGUAGE language_term ]
[ STATISTICAL_SEMANTICS ]
} [ , ...n ]
) ]
KEY INDEX index_name
[ ON <catalog_filegroup_option> ]
[ WITH ( <with_option> [ , ...n ] ) ]
[;]
<catalog_filegroup_option>::=
{
fulltext_catalog_name
| ( fulltext_catalog_name , FILEGROUP filegroup_name )
| ( FILEGROUP filegroup_name , fulltext_catalog_name )
| ( FILEGROUP filegroup_name )
}
<with_option>::=
{
CHANGE_TRACKING [ = ] { MANUAL | AUTO | OFF [ , NO POPULATION ] }
| STOPLIST [ = ] { OFF | SYSTEM | stoplist_name }
| SEARCH PROPERTY LIST [ = ] property_list_name
}No voy a entrar en todas las opciones de creación de un índice FullText, para eso podéis consultar la documentación oficial aquí. Nos vamos a centrar en las más importantes. Como veis es parecido a la sintaxis de creación de índices que todos conocemos. Especificaremos la tabla sobre la que crearlo y las columnas que incluirá. Como opción podemos definir el idioma del texto de esas columnas para las búsquedas, si no lo especificamos se usará el idioma por defecto de la instancia. Esto es importante si tenéis el servidor en inglés pero los datos en español, por ejemplo. Esta opción de language admite tanto el alias como el lcid de los idiomas de la vista del sistema sys.syslanguages.
Otro de los aspectos clave y que es obligatorio es definir un índice de referencia con la clave para nuestro nuevo índice FullText. Debe ser una clave única que no admita valores nulos. Para un mejor rendimiento se recomienda que sea un identificador único numérico. También debemos definir el catálogo sobre el que se creará el índice. Si no definimos el catálogo se usará el por defecto y si no hay uno por defecto veremos un bonito error, así que, aseguraos de definirlo bien.
Para terminar con esta sección de creación e índices FullText es importante destacar la opción de Change_Tracking que definirá la propagación de nuestro índice. Esto significa que define el comportamiento cuando hay una modificación de la tabla (Insert, Update o Delete). Por defecto está en modo AUTO y los cambios se propagan de la tabla al índice FullText en tiempo real pero podemos definirlo en modo manual y que solo se propaguen con una sentencia SQL que ejecutaremos a voluntad o programaremos en un job. La sentencia para propagar los cambios de la tabla al índice es:
ALTER FULLTEXT INDEX ON table_name START UPDATE POPULATIONPalabras irrelevantes
Como podéis imaginar, indexar todo un texto puede suponer unos requisitos de espacio tremendos, para evitar esto en la medida de lo posible SQL Server implementa lo que se llaman las palabras irrelevantes y las listas de palabras irrelevantes (stopword y stoplist). Si os habéis fijado antes, a la hora de crear un índice FullText podíamos definir una de estas stoplist.
Palabras irrelevantes
Una palabra irrelevante puede ser por ejemplo un código que guardamos pero que no se usa o palabras que sí tienen significado lingüístico pero que no son relevantes para las búsquedas como podrían ser preposiciones y otras. Por ejemplo en español no puede que no queramos indexar las palabras “un”, “y”, “el”, «de «, «hasta «, etc.
Listas de palabras irrelevantes
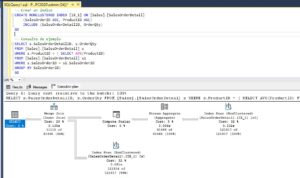
Para poder gestionar las palabras irrelevantes SQL Server usa unos objetos que se llaman lista de palabras irrelevantes o stoplists. Podemos encontrarlos desplegando la carpeta almacenamiento dentro de la base de datos (mirad en la imagen de antes). Para crear nuestras propias stoplists podemos hacerlo desde este apartado de SSMS o con la sintaxis CREATE FULLTEXT STOPLIST.
Mantenimiento de índices FullText
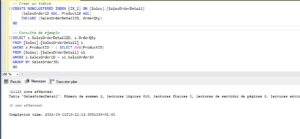
Como ya adelantamos en el artículo de ayer, el mantenimiento de los índices FullText se realiza sobre los catálogos. Para ello podemos hacerlo desde el SSMS haciendo click derecho sobre el catálogo y dando a Rebuild o por T-SQL. Si lo hacemos por T-SQL tendremos la posibilidad de reorganizar los índices sin necesidad de reconstruirlos. Si optamos por un REBUILD se borrarán todos los índices del catálogo y se volverán a crear eliminando así la fragmentación. Puede ser que solo queramos hacer el mantenimiento a un índice, en este caso podemos borrarlo y crearlo de nuevo manualmente. La sintaxis para hacer el mantenimiento de un catálogo es:
ALTER FULLTEXT CATALOG catalog_name
{ REBUILD [ WITH ACCENT_SENSITIVITY = { ON | OFF } ]
| REORGANIZE
| AS DEFAULT
} Si os fijáis, con esta instrucción podríamos también definir este catálogo como el por defecto.
Conclusión
Hoy hemos aprendido cómo podremos lidiar con los FullText índices como DBAs, esto sumado a lo que vimos ayer y a lo que veremos en el próximo artículo sobre su uso es todo lo que necesitamos para controlar este tema. Si queréis profundizar más en detalle os recomiendo bucear por la documentación oficial que os he compartido y por todas las demás páginas de Microsoft sobre los índices de texto completo. A mi me parece un mundo apasionante y del que poca gente conoce todos los detalles. ¿Quién sabe? Igual algún día tener estos conocimientos puede marcar la diferencia para el trabajo de vuestros sueños.
Espero que este artículo te haya proporcionado una visión profunda de los índices FullText o de texto completo en SQL Server. Como siempre, te animo a experimentar con estas técnicas y a explorar todas las posibilidades que ofrecen. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!