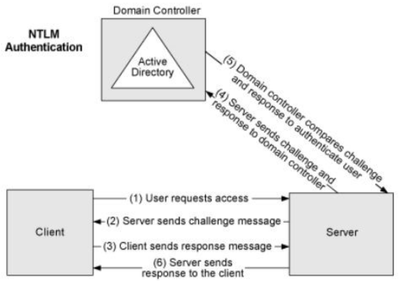
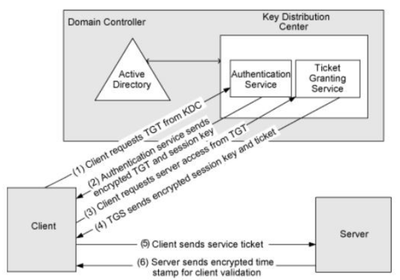
Hoy vamos a seguir hablando de PBIRS, si en el pasado artículo vimos sus características, licenciamiento y cómo se compara con el servicio de Power BI en la nube (más bien cómo se complementa) hoy toca el turno de la configuración y mantenimiento del mismo. Lo primero que tenemos que saber es que la instalación de un servidor de Power BI Report Server (PBIRS), como la de cualquier otro servicio de producción, es un proceso que requiere una planificación meticulosa y un mantenimiento continuo para garantizar un rendimiento óptimo y la satisfacción de los usuarios.
En este artículo, explicaremos algunas de las mejores prácticas que he identificado en mi experiencia con PBIRS, centrándonos en cómo implementarlas eficazmente y en cómo mantener la infraestructura una vez que esté en funcionamiento. La finalidad es maximizar la eficiencia, mejorar la seguridad y garantizar que los informes se ejecuten sin problemas, todo ello sin sacrificar la experiencia del usuario.
Planificando la Implementación de PBIRS
Como ya vimos cuando hablamos del despliegue de un servidor SQL Server, la planificación es un componente crucial en cualquier implementación, por tanto también cuando hablamos de PBIRS. Debemos comenzar con un análisis detallado de los requisitos de negocio y la capacidad técnica del entorno en el que se va a desplegar. Es esencial comprender no solo las necesidades actuales, sino también prever el crecimiento futuro y la escalabilidad de la plataforma.
Dimensionamiento y configuración del Servidor
Uno de los primeros pasos es dimensionar adecuadamente el servidor. La configuración del hardware debe estar alineada con la carga esperada de usuarios y la complejidad de los informes. Por ejemplo, si prevemos un uso intensivo de gráficos complejos o de grandes volúmenes de datos, será necesario disponer de un hardware más potente, con suficiente memoria RAM y capacidad de procesamiento para manejar las demandas sin comprometer el rendimiento.
Es recomendable dividir los recursos en diferentes servidores si el tráfico de usuarios o la carga de trabajo lo justifican, esto es un escalado horizontal. De esta manera, podemos evitar que un único punto de fallo impacte en la disponibilidad del servicio. Por supuesto, no debemos olvidar la importancia de configurar adecuadamente el almacenamiento, utilizando discos rápidos para el almacenamiento de bases de datos y optimizando las rutas de acceso para minimizar latencias.
Seguridad y gobernanza de los datos
A nadie le sorprende si os digo que la seguridad de los datos es primordial. PBIRS no es una excepción, y por ello es crucial establecer políticas de seguridad estrictas desde el inicio. Esto incluye la implementación de medidas como la autenticación segura, la encriptación de datos y la segregación de funciones para evitar accesos no autorizados.
Además, la gobernanza de los datos es otro aspecto que debemos considerar. Normalmente las organizaciones más grandes cuentan con equipos de gobierno del dato con quien deberemos trabajar estrechamente para establecer roles y permisos claros, así como auditar regularmente los accesos y las actividades dentro del servidor, nos ayudará a mantener un entorno seguro y conforme con las normativas vigentes. Es probable que en este proceso también intervenga el equipo de ciberseguridad, tanto en la toma de decisiones como en la monitorización continua de las auditorías.
Buenas Prácticas en PBIRS
Una vez que hemos planificado adecuadamente la implementación, es el momento de poner manos a la obra. Aquí es donde entran en juego las mejores prácticas específicas de implementación que nos permitirán maximizar el rendimiento y la funcionalidad de PBIRS.
Despliegue y Configuración Inicial
Durante el despliegue, es fundamental seguir las guías de instalación recomendadas por Microsoft, asegurándonos de que todas las dependencias están en su lugar y configuradas correctamente. Una vez instalado el servidor, debemos proceder con la configuración inicial, que incluye la creación de la base de datos de reportes, la configuración del servicio web y la aplicación de las políticas de seguridad definidas previamente.
Configuración de HTTPS en PBIRS
Un aspecto clave para la seguridad de PBIRS es el uso de HTTPS en lugar de HTTP para el servidor web. HTTPS asegura que los datos transmitidos entre los clientes y el servidor estén encriptados, lo que protege la información sensible de accesos no autorizados o ataques de intermediarios.
Implementar HTTPS en PBIRS requiere configurar el servidor web para aceptar conexiones seguras. Para ello, es necesario obtener e instalar un certificado SSL/TLS válido emitido por una autoridad de certificación de confianza. Los certificados SSL permiten que el servidor establezca una conexión segura y encriptada con los usuarios, lo que es fundamental para proteger la integridad y confidencialidad de los datos transmitidos.
Una vez que tenemos el certificado, debemos configurarlo en el servidor web de PBIRS. Este proceso generalmente implica asociar el certificado con el puerto 443, que es el puerto estándar para las conexiones HTTPS. Es crucial asegurarse de que todas las páginas y recursos del servidor se sirvan a través de HTTPS, redirigiendo automáticamente cualquier tráfico HTTP para evitar conexiones inseguras.
Mantenimiento Continuo de PBIRS
El mantenimiento es un aspecto que a menudo se subestima, pero es crucial para asegurar que el servidor siga funcionando de manera óptima a lo largo del tiempo. Este mantenimiento no solo incluye las actualizaciones regulares del software, sino también la monitorización proactiva y la gestión del rendimiento.
Monitorización y Rendimiento
Una de las mejores prácticas en el mantenimiento de PBIRS es la monitorización constante del rendimiento. Esto incluye la revisión de los logs de uso para identificar posibles cuellos de botella y la supervisión de los recursos del servidor para detectar cualquier signo de sobrecarga.
Utilizar herramientas de monitorización que permitan visualizar en tiempo real el uso de CPU, memoria y disco es fundamental. Esto nos permitirá anticiparnos a posibles problemas antes de que afecten a los usuarios finales. Además, realizar pruebas de estrés de manera periódica puede ayudarnos a ajustar la configuración del servidor para manejar mejor las cargas pico.
Actualizaciones y Parches
Mantener PBIRS actualizado es una práctica indispensable para asegurar tanto la estabilidad como la seguridad del sistema. Microsoft publica regularmente actualizaciones, normalmente 3 al año, que corrigen errores, mejoran el rendimiento y añaden nuevas funcionalidades. Sin embargo, antes de aplicar cualquier actualización, es recomendable realizar pruebas en un entorno de desarrollo o de preproducción para asegurarnos de que no introducirá nuevos problemas en el entorno de producción.
Además, es importante mantener actualizadas las bases de datos y los sistemas operativos subyacentes, ya que cualquier vulnerabilidad en estos componentes podría comprometer la seguridad y la integridad de los datos.
Gestión de la Capacidad y Escalabilidad
A medida que el uso de PBIRS crece, también lo hará la demanda de recursos. Por ello, es esencial gestionar la capacidad de manera proactiva, añadiendo recursos o distribuyendo la carga cuando sea necesario. Implementar una estrategia de escalabilidad, que incluya tanto la escalabilidad horizontal (añadir más servidores) como la vertical (mejorar los recursos de los servidores existentes), nos permitirá mantener un rendimiento óptimo a medida que crece la base de usuarios y la complejidad de los informes.
Optimización en la entrega de Informes
Para garantizar que los informes se entreguen de manera eficiente, es necesario optimizarlos. Esto implica una revisión continua tanto de consultas DAX como SQL para asegurarnos de que están bien escritas y no consumen recursos innecesarios. También es aconsejable utilizar particiones de datos en modelos grandes y evitar el uso excesivo de gráficos o visualizaciones que puedan ralentizar el rendimiento.
Otro punto clave es configurar adecuadamente los tiempos de actualización de los informes. Definir horarios de actualización en momentos de baja demanda puede reducir significativamente el impacto en el rendimiento general del servidor.
Renovación de certificados
Por último no se nos debe olvidar que la implementación de HTTPS, de la que hemos hablado antes, no es un proceso único; es necesario que renovemos los certificados periódicamente para mantener la seguridad del sistema. Los certificados SSL tienen una validez limitada (de uno o dos años por norma general), por lo que debemos estar atentos a su fecha de expiración y renovarlos con antelación para evitar interrupciones en el servicio o alertas de seguridad para los usuarios.
Además, es recomendable utilizar certificados de autoridades de certificación reconocidas y evitar los certificados autofirmados en entornos de producción, ya que estos no son confiables por los navegadores modernos y pueden generar advertencias de seguridad para los usuarios.
Conclusión
La implementación y el mantenimiento de Power BI Report Server requieren un enfoque detallado y proactivo para garantizar que el sistema funcione de manera eficiente y segura. Desde la planificación inicial hasta el mantenimiento continuo, cada etapa del proceso ofrece oportunidades para optimizar el rendimiento y mejorar la experiencia del usuario. Al seguir las mejores prácticas descritas en este artículo, estaremos mejor preparados para abordar los desafíos que puedan surgir y asegurar que PBIRS continúe siendo una herramienta valiosa para la organización.
En última instancia, la clave del éxito radica en la planificación cuidadosa, la optimización constante y la monitorización proactiva, lo que nos permitirá maximizar el valor de nuestra inversión en Power BI Report Server y garantizar que sigue cumpliendo con las necesidades de negocio a lo largo del tiempo.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!