Ayer hablamos en profundidad sobre las instancias administradas de SQL Server en Azure y os prometí dedicar el post de hoy a temas de administración. Vamos a empezar hablando de los modos de licenciamiento y lo que nos ofrece cada uno de ellos y, a continuación, ya entraremos en materia con la administración.
Licenciamiento de instancias administradas en Azure
Como DBAs es probable que recaiga sobre nosotros la elección de la arquitectura SQL y por tanto su licenciamiento. En el caso de las instancias administradas de SQL Server en Azure el modelo de compra se basa en núcleos virtuales. Esto quiere decir que recursos como la RAM dependerán de la cantidad de núcleos de CPU que seleccionemos y no podremos ampliar un recurso sin el resto. Además de los núcleos tenemos otras opciones, por un lado podremos elegir el tipo de hardware y el nivel de servicio. Sé que es un poco lioso así, no os preocupéis que vamos a verlo con detalle.
En base al hardware, tenemos tres planes disponibles: el Gen5, el Premium y el Premium optimizados para memoria. La diferencia entre el Gen5 y el Premium es el tipo de procesador y, por tanto, su velocidad. Además el plan Premium nos da algo más de RAM por cada núcleo que contratemos. El Premium y Premium optimizado para memoria solo se diferencian en que este segundo da aún más RAM por cada núcleo.
Además, como hemos comentado, cualquiera de estos tres planes se puede contratar en dos niveles de servicio: estándar o crítico para la empresa. El nivel estándar nos proporcionará 16Tb de Azure Blob Storage de alto rendimiento y alta disponibilidad basada en Azure Blob Storage y Azure Service Factory. El nivel crítico para la empresa cambia la opción de almacenamiento por un SSD local extremadamente rápido que reduce la latencia de E/S. El tamaño del SSD variará en función del plan de hardware. Otras ventajas del nivel de servicio crítico es la alta disponibilidad Always On y una réplica de solo lectura adicional. Por último, este nivel, añade OLTP en memoria para usarse en cargas con necesidades de rendimiento muy altas.
La siguiente tabla resume todo lo que hemos comentado, para precios Microsoft ha puesto a nuestra disposición esta calculadora.
Operaciones de administración
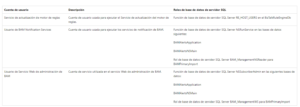
Ahora que ya sabemos que opción contratar es momento de crear nuestra primera instancia. Para crear instancias, igual que para cambiar su configuración o eliminarlas, podremos hacerlo desde Azure Portal, usando PowerShell o la CLI (Command Line Interface) de Azure. Al crear una instancia tenemos que elegir el nombre, la ubicación, la versión y la edición de SQL Server, el tamaño del almacenamiento y la configuración del firewall. En cuanto a la configuración, podremos cambiar algunos parámetros como el número de núcleos virtuales (vCores), la cantidad de memoria RAM o el tamaño del almacenamiento. También podemos habilitar o deshabilitar algunas características como el Always On Availability Groups o el Transparent Data Encryption.
Copias de seguridad y restauraciones en instancias en Azure
Antes de empezar con este tema, vamos a hablar de una cosa que todos estáis pensando y que no es para menos. Con la presentación de SQL Server 2022 se nos mostró una funcionalidad llamada “Vínculo para Azure Managed Instance” que, haciendo uso de grupos de disponibilidad distribuidos, nos permitiría mantener sincronizados nuestro entorno On Premise con Azure. Sin embargo, aunque SQL Server 2022 salió al mercado en diciembre de 2022, a día de hoy (Enero de 2024) sigue siendo una versión preliminar que no está disponible para todo el mundo. Sé lo que estáis pensando, es una CHAPUZA que, habiendo pasado más de un año siga sin estar disponible esta característica. No olvidemos que es una de las principales novedades que justificaría la migración a esta versión de SQL Server. Yo tampoco lo entiendo.
Vale, pasemos página y dejemos atrás lo malo (aunque no lo olvidemos) y hablemos de las copias de seguridad en las instancias de Azure. Las copias de seguridad principales, son automáticas y no vamos a poder configurar nada. Las instancias administradas realizan copias de seguridad automáticas cada 5-10 minutos (dependiendo del tamaño de las bases de datos) y las almacenan en un almacenamiento redundante. Podemos restaurar nuestras bases de datos desde estas copias usando Azure Portal o PowerShell.
Sin embargo, nosotros también podemos realizar copias de seguridad manuales por nuestra cuenta usando T-SQL o PowerShell y almacenarlas en un almacenamiento externo como Azure Blob Storage o un recurso compartido SMB. Estas copias siempre serán Copy-Only para no interferir en la cadena principal de copias automáticas.
En cuanto a restauración de copias manuales, podremos usar T-SQL o PowerShell para restaurar nuestras copias en la instancia de Azure. Nuestra instancia administrada admitirá copias de otras bases de datos de Azure y de cualquier SQL Server superior a 2008. En el otro sentido, solo podremos restaurar copias de seguridad de Azure en SQL Server 2022.
Actualizaciones de instancias administradas en Azure
Las instancias administradas se actualizan solas con los últimos parches y mejoras de SQL Server sin necesidad de intervención manual. Sin embargo, sí tendremos que elegir entre dos modos de actualización: automático o manual. En el modo automático, las actualizaciones se aplican tan pronto como están disponibles mientras que en modo manual, podemos elegir cuándo aplicarlas. Os recomiendo este último modo para actualizar siempre dentro de una ventana de mantenimiento.
Monitorización de instancias administradas en Azure
Podemos monitorizar y diagnosticar nuestras instancias administradas usando las herramientas habituales que ya conocemos como SQL Server Management Studio o Extended Events. También podemos usar los servicios integrados de Azure como Azure Monitor o Azure SQL Analytics para obtener métricas e insights sobre el rendimiento, la disponibilidad y la salud de nuestras instancias.
Conclusión
Como hemos visto en este artículo y en el anterior, las instancias SQL Server administradas de Azure son una gran solución PAAS en el cloud de Microsoft. Nos ofrecen prácticamente todas las características de un SQL Server local sin necesidad de tenerlo en nuestra infraestructura. Además, Azure se encarga de las copias de seguridad por nosotros y nos garantiza una disponibilidad con un SLA cercano al 100%. Por contra, perdemos flexibilidad a la hora de gestionar ciertos temas de configuración de recursos y nos limita a 16 Tb de espacio en disco. ¿Qué opináis? ¿Trabajáis con esta solución?¿Os planteáis migrar a este servicio? Os leo en comentarios. También podéis dejar vuestro feedback en nuestro Twitter o en nuestro nuevo grupo de LinkedIn.