Cuando hablamos de consultas sobre las bases de datos, la eficiencia es clave. Como DBAs siempre buscamos formas de mejorar el rendimiento de las consultas. Pero no solo nosotros, los DBAs, nos vemos en esta necesidad, cualquier desarrollador que trabaje con bases de datos también debe perseguir el mismo objetivo. En este contexto, a veces, la solución puede ser tan simple como usar la sugerencia de consulta OPTION RECOMPILE. Pero, ¿qué es exactamente y cómo puede ayudarnos en SQL Server y Azure SQL? ¿Realmente es una solución mágica que podemos usar siempre como una carta comodín? Durante estas líneas voy a tratar de dar respuesta a estas preguntas.
¿Qué es OPTION RECOMPILE?
OPTION RECOMPILE es una directiva que podemos agregar al final de nuestras consultas en SQL Server para indicar que queremos que se recompile el plan de ejecución cada vez que se ejecuta la consulta. Esto puede ser útil en situaciones donde los datos subyacentes cambian con frecuencia y queremos asegurarnos de que estamos utilizando el plan de ejecución más eficiente posible.
¿Cómo funciona OPTION RECOMPILE?
Para entender este concepto, es importante recordar algunos de los conceptos que hemos discutido en artículos anteriores. En concreto hablo de los planes de ejecución de las consultas y de la caché de planes de ejecución.
Planes de ejecución
En nuestro artículo sobre planes de ejecución, exploramos cómo SQL Server y Azure SQL crean y utilizan estos planes para llevar a cabo las consultas de manera eficiente. Estos planes son esenciales para entender cómo OPTION RECOMPILE puede mejorar el rendimiento de nuestras consultas.
Caché de planes de ejecución
Además, en nuestro artículo sobre la caché de planes, vimos cómo SQL Server y Azure SQL almacenan los planes de ejecución para su reutilización. Este almacenamiento en caché puede ser muy eficiente, pero también puede llevar a problemas si los datos subyacentes cambian con frecuencia, lo que nos lleva de nuevo a la utilidad de OPTION RECOMPILE.
Option Recompile
Ahora sí, vamos a dar respuesta a la pregunta ¿cómo funciona OPTION RECOMPILE?
Ya sabemos que la primera vez que ejecutamos una consulta en SQL Server o Azure SQL, el motor de la base de datos crea un plan de ejecución. Este plan es básicamente una serie de pasos que la base de datos seguirá para recuperar los datos solicitados. Una vez que se ha creado un plan, además de usarse para la consulta en curso, se almacena en caché para su uso en futuras ejecuciones de la misma consulta.
Sin embargo, esto que la mayoría de las veces es una ventaja, puede no serlo si los datos subyacentes cambian significativamente. En estos casos el plan almacenado en caché puede no ser el más eficiente. También puede pasar que las estadísticas de la tabla no estuvieran bien actualizadas al momento de compilar el primer plan de ejecución y no este sea del todo correcto. Aquí es donde entra en juego OPTION RECOMPILE. Al agregar esta directiva a nuestra consulta, le estamos diciendo al motor de base de datos de SQL Server que ignore cualquier plan almacenado en caché y genere uno nuevo.
Esto no quiere decir que se vaya a usar un plan de ejecución distinto, simplemente el motor de base de datos va a analizar todas las opciones posibles para resolver la consulta y a elegir el que le parezca más óptimo. Puede ser que vuelva a elegir el mismo, sobre todo si tenemos un problema con las estadísticas.
¿Cuándo deberíamos usar OPTION RECOMPILE?
Aunque OPTION RECOMPILE puede ser una herramienta poderosa, no siempre es la mejor opción. La recompilación de un plan de ejecución tiene un coste en términos de recursos, en concreto en consumo de CPU, por lo que si una consulta se ejecuta con mucha frecuencia, el coste de la recompilación puede superar cualquier beneficio de rendimiento que obtengamos.
Por lo tanto, OPTION RECOMPILE es más adecuado para consultas que se ejecutan con poca frecuencia, pero que son críticas para el rendimiento, o para consultas donde los datos subyacentes cambian con tanta frecuencia que un plan almacenado en caché se vuelve ineficiente rápidamente. En esta línea, otro posible escenario son las consultas de procedimientos almacenados que interactúan con datos con gran variación entre un parámetro y otro. Para estos casos de gran desigualdad en los volúmenes de datos puede ser una gran alternativa a la utilización tradicional de planes en caché.
Personalmente también me gusta mucho utilizar esta opción de consulta cuando me enfrento a un problema de rendimiento de una consulta. En estas situaciones puede ser de gran ayuda, localizar a tiempo que el problema está en un plan de ejecución no óptimo cacheado puede ahorrarnos mucho tiempo y esfuerzo en la optimización.
Conclusión
En resumen, OPTION RECOMPILE es un truco muy potente y valioso en nuestra caja de herramientas de optimización de consultas. Aunque no es una solución para todos los problemas de rendimiento, y hay que medir muy bien su uso para no caer en problemas mayores, puede ser extremadamente útil en las circunstancias adecuadas. Como siempre, la clave es entender cómo funciona y cuándo usarlo. Y como digo siempre, solo plantéate este tipo de soluciones si realmente tienes un problema, las soluciones “por si acaso” nunca suelen ser una buena idea. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Iniciamos esta semana como terminamos la pasada, con otro artículo sobre análisis de datos e inteligencia de negocio. En concreto vamos a seguir hablando de buenas prácticas en Power BI. Si en nuestro último artículo hablábamos de la importancia de usar un modelo de estrella en Power BI hoy vamos a repasar el resto de buenas prácticas también muy importantes en esto del modelado de datos.
Antes de seguir quiero hacer un inciso (“Disclaimer cero” que diría el gran motero Isaac Feliú) todas las recomendaciones descritas en este artículo aplicadas a Power BI también son válidas para modelos tabulares como Power Pivot, Analisys Services y otros. Aun así, esto no quiere decir que tengamos que tomarnos estas buenas prácticas como los diez mandamientos escritos en piedra e inamovibles, son unas recomendaciones y no todas van a ser aplicables al 100% para todos los modelos.
Uso de vistas en Power BI
Las vistas son consultas almacenadas en la base de datos que generan un conjunto de resultados al ser invocadas. Podríamos decir que son tablas virtualizadas que se basan en el resultado de una consulta SQL y “no almacenan los datos” así entre unas comillas muy grandes. Cuando hablamos de modelado de datos, las vistas juegan un papel crucial. En Power BI, las vistas pueden ser una herramienta poderosa para simplificar y optimizar nuestros modelos de datos. Vamos ahora a ver estas ventajas:
Abstracción del modelo
Gracias al uso de vistas, cuando importamos datos desde entornos de bases de datos relacionales como SQL Server o Azure SQL vamos a poder abstraer nuestro modelo de datos del modelo original de las aplicaciones transaccionales. Esto que puede no parecer importante realmente es clave, ya que los modelos de datos suelen ser entidades vivas cambiantes con cada actualización de las aplicaciones. Gracias al uso de vistas, vamos a poder salvar este inconveniente, y en caso de cambios en el nombre de una columna, por ejemplo, vamos a poder corregirlo en un solo sitio sin tener que cambiarlo en todos los informes.
Simplificación del modelo de datos de Power BI
Las vistas pueden ayudar a simplificar nuestros modelos de datos en Power BI. Al encapsular la lógica de las consultas en una vista, podemos reducir la complejidad de nuestro modelo de datos y hacerlo más fácil de entender y mantener. En otras palabras, podremos aprovechar estas vistas para simplificar lo más posible el modelo de datos, eliminando de las consultas de la vista todas aquellas columnas que no necesitamos en el modelo analítico.
Mejora el rendimiento de Power BI
Las vistas también pueden contribuir a mejorar el rendimiento de nuestros informes de Power BI. Al utilizar vistas, podemos minimizar la cantidad de datos que necesitamos cargar en Power BI, lo que puede resultar en informes más rápidos y eficientes. También, gracias al uso de vistas indexadas, que ya vimos hace meses en este blog, podemos mejorar el rendimiento de manera sustancial, hasta pasando de horas de procesamiento de la consulta a segundos en los casos más extremos.
Seguridad de los Datos
Las vistas nos permiten implementar una capa adicional de seguridad en nuestros datos. Podemos utilizar vistas para restringir el acceso a ciertos datos, asegurando que sólo los usuarios autorizados puedan ver la información sensible.
Buenas prácticas en el uso de vistas
Ya hemos visto que el uso de vistas para alimentar nuestro modelo es una buena práctica en sí misma pero esto no queda ahí, existen unas buenas prácticas para la buena práctica de crear vistas. Gracias a estas “meta buenas prácticas” vamos a poder sacar todo el partido de las ventajas del uso de vistas que ya os he comentado. Vais a ver cómo, a medida que las vayamos viendo vamos a poder enlazarlo claramente con todo lo ya mencionado arriba.
Uso de esquemas
Crear un esquema dedicado a las vistas que se van a utilizar para alimentar el modelo de Power BI no solo sirve para mantener la organización, también nos va a ayudar a poder centralizar los permisos. Podemos incluso crear varios esquemas si tenemos varios grupos de informes o reportes en Power BI para tener más control sobre su seguridad y organización. A la hora de importar las tablas al modelo de Power BI no hay ningún problema en eliminar el nombre del esquema y dejar solo el de la vista.
Crear vistas por tabla de Power BI
Otra de las mejores recomendaciones que podemos encontrar sobre este aspecto es la creación de vistas independientes por cada tabla del modelo de Power BI y no por cada tabla del modelo relacional original. De esta manera podemos aprovechar la potencia de SQL Server o el SGBD relacional que usemos y sus índices para las uniones entre tablas y que se presenten a Power BI como una tabla plana.
Limitar el número de columnas
Otra de las ventajas del uso de vistas era optimizar el rendimiento reduciendo la lectura de datos que no van a ser explotados por el modelo de Power BI, esto lo lograremos declarando los campos necesarios en el select de la vista en lugar de un carácter *. De esta manera además podremos ver de una manera fácil en SQL Server que datos se están explotando en Power BI y los DBAs tendremos más fácil localizar las actuaciones del modelo relacional que pueden afectar al modelo analítico.
Otras buenas prácticas para Power BI
No solo de modelos en estrella y vistas vive un buen modelador de datos, existen además ciertas recomendaciones que también tendremos que tener en cuenta al diseñar nuestro modelo en Power BI. Vamos a repasar las más significativas:
Utiliza nombres significativos
Esto es de primero de modelador de datos, no solo para modelos analíticos, sin embargo, es común encontrarnos con situaciones en las que no se aplica, ya sea por desconocimiento, indiferencia o una mezcla de las dos (el típico ni lo sé ni me importa). Un nombre descriptivo a la hora de definir las columnas de las vistas que van a alimentar nuestro modelo en Power BI nos ayudará luego a crear los reportes con menos trabajo. Por supuesto evita repetir los mismos nombres para distintas columnas a no ser que sea en distintas tablas y esas columnas sean las claves por las que vas a relacionar las tablas. En ese caso un nombre común te ayudará a localizar las relaciones. Piensa que al usar vistas has perdido la capacidad de consultar las relaciones establecidas en las tablas de la base de datos por medio de claves foráneas.
Separa fechas y horas
En los sistemas de bases de datos relacionales es común el uso de tipos de datos que incluyen la fecha y la hora, incluso con presiones de microsegundos o más, por ejemplo en SQL Server el tipo de datos datetime2 tiene una precisión de 7 dígitos (hasta 100 nanosegundos). Esta precisión puede que sea clave para una aplicación pero, os aseguro, que al gerente que está visualizando un informe como mucho le importan los segundos, el resto de precisión suele ser despreciable. Cuando trasladamos estos datos a Power BI seguramente no necesitamos esa precisión, valora separar estos campos en un campo date y otro time y ajustar la precisión a los valores que vayan a necesitar los consumidores de tus reportes.
Mantén los modelos de Power BI sencillos
El título lo dice todo, no hay mucho más que añadir. Aunque Power BI puede manejar modelos de datos complejos, es mejor mantener los modelos lo más sencillos posible. Un modelo simple es más fácil de entender, mantener y optimizar.
Utiliza columnas calculadas y medidas de manera eficiente
Las columnas calculadas y las medidas son dos características poderosas de Power BI. Debemos utilizarlas de manera efectiva para mejorar el rendimiento y la funcionalidad de nuestros informes y valorar cuándo nos va a dar mejor rendimiento un cálculo en el motor de base de datos implementado en la propia vista y cuándo será mejor delegar ese trabajo en Power BI.
Marca las tablas de fecha de Power BI
En los inicios de Power BI, las tablas de dimensiones de fechas eran una tabla más, como todas las demás solo que almacenaban fechas. Sin embargo, desde la actualización de 2018 de Power BI, existe una marca para catalogar las tablas que contienen datos de fecha y hora como tablas de fechas. Esto optimizará el rendimiento y mejorará la experiencia de los usuarios.
Optimiza el Rendimiento
Para terminar, no es que sea una buena práctica como tal pero sí es importante remarcar que debemos revisar continuamente el rendimiento. Nuestro modelo va a crecer con el tiempo y puede que algunas soluciones que en un principio parecían aceptables ahora no lo sean. También podemos encontrarnos con casos como el anterior en el que una actualización de Power BI nos habilita una nueva funcionalidad para optimizar nuestro modelo. El rendimiento es un aspecto crítico del modelado de datos. Debemos tener en cuenta factores como el tamaño de los datos, la complejidad de las consultas y la capacidad de la máquina al diseñar y mantener nuestros modelos.
Conclusión
El modelado de datos es una ciencia y un arte a partes iguales. Conocer las buenas prácticas, y aplicarlas siempre que sea posible, nos ayudará a diseñar reportes optimizados que mejoren la experiencia de los usuarios finales. Espero que gracias a estos artículos estés más cerca de ese objetivo. Y ya sabes, si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
El artículo de hoy va para mis amigos analistas de datos, desarrolladores de BI y DBAs centrados en entornos datawarehouse aunque espero que sea también interesante para todos los demás. Hoy vamos a hablar del modelado en Power BI, existen muchas maneras de hacerlo pero al final, si el modelo va a tomar cierta envergadura, todo lo que no sea un modelo puro de estrella va a terminar dando mal rendimiento.
¿Qué es Power BI?
Empecemos por el principio, seguramente si eres analista de datos o desarrollador BI si sabes de lo que estoy hablando pero, permíteme un paréntesis, para que toda esa gente que está leyendo esto y no sabe muy bien de lo que hablamos parta desde el mismo punto. Al fin y al cabo este es un blog de DBAs.
Power BI es un software de Microsoft para inteligencia de negocio (de ahí su nombre) capaz de convertir datos de casi cualquier fuente en informes interactivos muy atractivos visualmente. Esta información que puede venir de cualquier fuente puede ser desde un fichero de texto plano separado hasta una potente base de datos relacional como SQL Server o las bases de datos SQL de Azure.
El flujo de trabajo de Power BI
A grandes rasgos, para empezar a trabajar en Power BI, debemos usar Power BI Desktop para conectar la información de las fuentes, modelarla en la propia aplicación y después, preparar los informes visuales.
Una vez generado el informe se puede almacenar en un archivo pbix para consumir con la aplicación Power BI Desktop en el equipo local o publicarla en Power BI Service que no es más que un SQL Server Reporting Service adaptado. Si habéis administrado este servicio anteriormente vais a ver que es prácticamente igual, solo cambia el origen de los reportes.
¿Qué es un modelo de estrella?
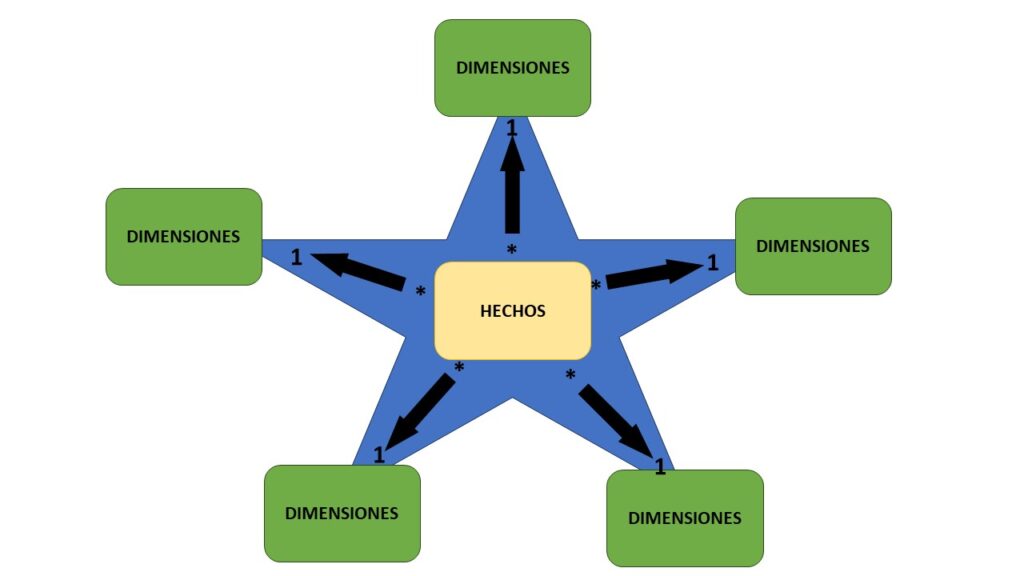
No es la primera vez que hablamos en el blog sobre los modelos de estrella, ya le dedicamos este artículo completo hace unos meses. Para refrescar las ideas, el modelo de estrella es una forma de organizar nuestros datos en base a una tabla central de hechos relacionada con varias tablas de dimensiones. Tener toda la información relevante en una misma tabla central lo convierte en un modelo optimizado para consultas de agrupaciones, justo lo que buscamos cuando elaboramos informes de BI. En este sentido, no es raro encontrarnos con tablas desnormalizadas, primando el rendimiento máximo de este tipo de lecturas sobre el ahorro de espacio y el rendimiento de escrituras.
Por qué usar un modelo de estrella en Power BI
Como ya hemos dicho, la mejor manera de modelar los datos en Power BI es con un modelo de estrella. Esto es así porque todos y cada uno de los objetos visuales que van a terminar componiendo los reportes van a realizar consultas contra el modelo de datos almacenado en la aplicación. Esas consultas además no tienen nada que ver con las consultas de selección de información a las que estamos acostumbrados a ver en una base de datos relacional, son consultas mucho más pesadas de filtrado, agregación, resumen y ordenación de los datos del modelo. Gracias a usar un modelo en estrella, las tablas de dimensiones admitirán el filtrado y la agregación mientras que sobre la tabla de hechos recaerá el resumen.
Es importante destacar que la tabla de hechos y las de dimensiones no se establecen como tal por ninguna propiedad que asigne el modelador de datos, simplemente son tablas normales que al aplicar las relaciones correctas terminan componiendo este modelo. Si seguimos a rajatabla los cánones y buenas prácticas, todas las relaciones serán de uno a muchos, siendo siempre uno en la tabla de dimensión y muchos en la de hechos.
Un diseño bien modelado tendrá este aspecto que vemos en la imagen, con una tabla central de hechos relacionada con tantas tablas de dimensiones como sean necesarias y sin mezclar en una misma tabla dimensiones con hechos (Si estás perdido en este punto y no sabes la diferencia entre una tabla de hechos y una tabla de relaciones pásate por nuestro artículo sobre el modelo de estrella para descubrirlo).
Conceptos clave del modelo de estrella en Power BI
Ahora que ya conocemos la estructura ideal del modelo de estrella en Power BI vamos a tratar de entender los conceptos clave necesarios para una correcta implementación del mismo.
Medidas
Normalmente, cuando hablamos de un modelo de estrella, una medida es la columna de la tabla de hechos que almacena información que se va a resumir. Cuando llevamos esta implementación del modelo de estrella a Power BI, esta medida va a ser una fórmula escrita en DAX que permita resumir la información. Lo más normal será encontrarnos con fórmulas MAX, MIN o AVG para generar un valor que consumir. Estos valores nunca se almacenan en el modelo.En Power BI, existen además una serie de medidas automáticas llamadas medidas implícitas para consumirse en el informe visual llamadas medidas implícitas.
Claves suplentes
Son el identificador único de las tablas de dimensiones, lo que en base de datos conocemos como clave primaria. Estas claves en Power BI tienen la particularidad de no poder ser compuestas, tienen que ser una única columna. Es común tener que generar una columna con los datos de otras concatenados para que actúe como clave suplente aunque la mejor idea es agregar un identificador único a la tabla ya que de esa manera las relaciones con la tabla de hechos serán más fluidas.
Tablas de hechos sin hechos
En ocasiones es posible encontrarnos con la necesidad de crear una tabla de hechos que realmente no almacene ningún hecho. Por ejemplo una tabla de log de logins donde almacenamos una fecha de inicio de sesión donde el hecho realmente será el conteo de filas correspondiente a los inicios de sesión de los usuarios. Otra opción para utilizar este tipo de tabla es la típica tabla que almacena relaciones con las claves de otras dos tablas, tabla que es necesaria muchas veces para tener el modelo normalizado.
Dimensiones especiales en Power BI
Ya vimos en nuestro artículo sobre el modelo de estrella lo que eran las dimensiones, también llevamos todas estas líneas hablando sobre ellas. Sin embargo, en el mundo del análisis de datos y en concreto en Power BI existen unos tipos especiales de dimensiones que debemos conocer.
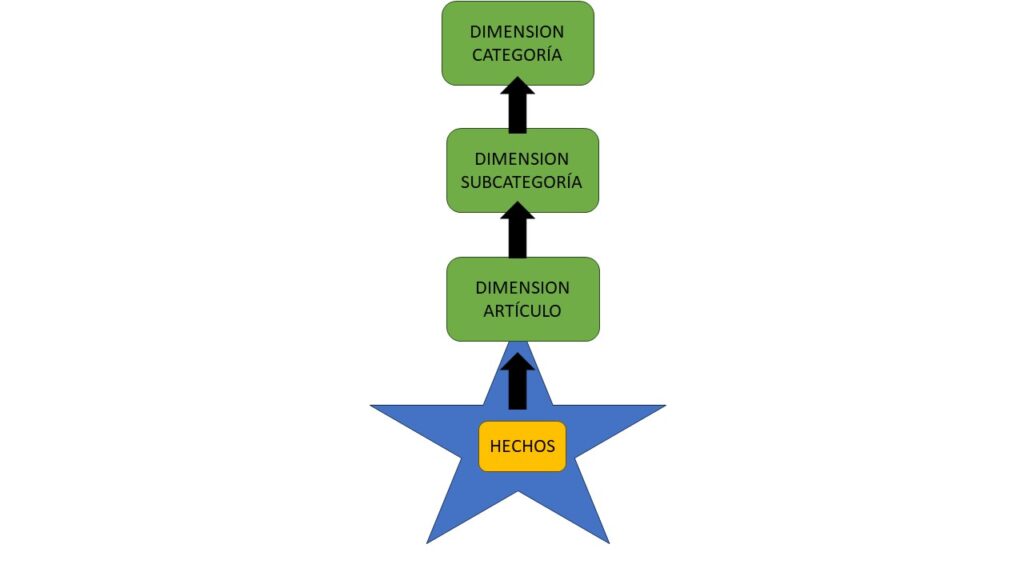
Dimensiones de copo de nieve
Las dimensiones de copo de nieve son conjuntos de tablas normalizadas que representan una única entidad de negocio o propiedad de un objeto. Por ejemplo, en la mayoría de ERP y software de gestión de almacén y ventas es común encontrar las propiedades categoría y subcategoría para los artículos. Esta idea, trasladada a un modelo normalizado, nos mostrará tres tablas, la de categorías, la de subcategorías y la de productos o artículos.
Si optamos por imitar el modelo de origen en Power BI en vez de desnormalizar el modelo y almacenar una única tabla de dimensiones no será lo más óptimo ya que deberemos cargar más tablas y más columnas clave. Además las fórmulas para definir las relaciones serán más largas y complejas complicando la propagación de filtros entre las tablas. Esto se traduce en un mayor número de campos en el panel para diseñar el informe visual, lo que también puede complicar la experiencia. Aunque parezca una buena idea a fin de tener el modelo normalizado y ahorrar espacio, a la larga, nos va a generar problemas debido a la limitación de Power BI de crear una jerarquía que abarque todas las tablas.
Dimensiones de variación lenta
Las dimensiones de variación lenta o dimensiones lentamente cambiantes (SCD por sus siglas en inglés) son aquellas que administran correctamente el cambio a lo largo del tiempo. Las SCD pueden admitir cambios de tipo 1, de tipo 2 o ambos a la vez.
El cambio tipo 1 es aquel que al producirse modifica todo el historial pasado, no nos interesa el histórico y solo queremos saber el valor actual. Sin embargo un cambio tipo 2 se almacena en un nuevo registro, sin sustituir el anterior. Por ejemplo, imaginad que tenemos una tienda de pulseras y nuestro principal cliente son hombres casados que compran regalos a sus esposas. Nuestra tabla de clientes es una dimensión, en esta tabla tenemos datos como el correo electrónico o el teléfono para enviarles promociones. Si estos datos cambian, no nos interesa almacenar el historial, con tener el dato actualizado es suficiente. Esto es un cambio tipo 1.
Sin embargo, hay otro campo de la dimensión clientes que es el estado civil y, en ese, si que necesitamos un historial. Saber cuántas veces pasan nuestros clientes de soltero a casado o casado a soltero y cuánto tiempo pasa de media entre cada etapa puede ser de gran ayuda para nuestros analistas de datos y sus modelos de predicción de ventas.
Podríamos tener otro tipo de dimensión cambiante como el precio de nuestros artículos de venta pero, si estos cambian rápidamente, lo mejor será almacenar esa información en la tabla de hechos.
Dimensiones realizadoras de roles
Existen dimensiones que, por sus características, pueden filtrar los hechos de maneras diferentes. Por ejemplo, imagina nuestro ejemplo anterior donde teníamos una tienda de pulseras, la dimensión fecha es capaz de realizar filtros por fecha de pedido, fecha de envío, fecha de cobro o incluso por fecha de alta de un cliente.
En Power BI podríamos definir varias relaciones entre nuestra dimensión fecha y la tabla con los hechos, sin embargo, solo una de las relaciones puede estar activa. Tener una única relación activa implicará la propagación de filtros sobre la dimensión a la tabla de hechos. Técnicamente es posible usar relaciones inactivas pero para ello el desarrollador del informe tendrá que usar la función DAX USERELATIONSHIP. Esto puede resultar complicado tanto por el uso de código extra como por la cantidad de campos generados en el panel de construcción de reportes.
Un enfoque común para superar estas limitaciones es, al modelar, crear varias tablas de dimensiones con la misma información duplicada de manera que cada una de ellas tenga una instancia realizadora de roles (filtrados). Es un precio menor a pagar ya que, por lo general ( y por definición), las tablas de dimensiones son relativamente pequeñas en comparación con los hechos.
Dimensiones no deseadas
Al trasladar datos de un modelo origen a nuestro modelo de Power BI es común encontrarnos con dimensiones no deseadas. Una dimensión no deseada puede ser útil cuando las dimensiones constan de pocos atributos y a su vez estos de pocos valores. En estos casos, puede ser una buena idea realizar un producto cartesiano de ambas dimensiones en una sola. Por ejemplo, volvamos a nuestra tienda, tenemos una dimensión que almacena un único atributo que es el estado de los pedidos y los valores que acepta son pedido recibido, pedido recibido y pedido completado. A su vez, tenemos otra dimensión con otro único atributo que es el estado de envío del pedido y admite los valores no enviado, enviado y entregado. En este caso, podríamos combinar ambas dimensiones del origen en una sola en nuestro modelo de estrella.
Dimensiones degeneradas
Una dimensión degenerada en el modelado de Power BI se refiere a un atributo de datos que funciona como una dimensión, pero que en realidad se almacena en la tabla de hechos, en lugar de en su propia tabla de dimensión separada. Es una excepción a la regla de oro que hemos comentado al principio de no mezclar hechos y dimensiones en una sola tabla. En otras palabras, es una clave de dimensión que se almacena en una tabla de hechos y no se une a una tabla de dimensiones correspondiente porque todos sus atributos ya se han colocado en otras dimensiones. Esto elimina la necesidad de unir otra tabla de dimensiones.
Conclusión
¿Aún sigues leyendo a estas alturas? ¿Después de casi 2000 palabras? Si es así y no has saltado directamente a este apartado gracias. Como habrás podido ver el modelado en power BI pasa por un modelo de estrella estricto para obtener un buen rendimiento. Sin embargo, esto de la ciencia de datos tiene mucho de arte también y son los analistas, científicos y arquitectos de datos los que van a modelar los datos a medida para el mejor rendimiento de sus informes. De la teoría a la práctica ya sabes que hay un mundo y eso solo te lo da la experiencia y haber hecho muchas pruebas. Como hemos visto en el artículo, sobre todo en esta última parte, hay excepciones incluso para el primer mandamiento del modelador de no mezclar hechos con dimensiones. Espero que hayas aprendido los fundamentos básicos de esta ciencia.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
En este quinto video blog vamos a aprender a usar el monitor de rendimiento de Windows (PERFMON) para medir el rendimiento de SQL Server y poder detectar cuando hay algún problema. Es importante conocer previamente el estado normal de nuestros servidores para ser capaces de identificar cuando estamos ante un problema de rendimiento.
En el video hemos visto como usar en perfmon las métricas de uso de CPU combinadas con los lotes por segundo que procesa SQL Server así como la velocidad de lectura y escritura de los discos. Además de estas métricas también podemos revisar las compilaciones y recompilaciones de nuestro SQL Server cuyo valor ideal será un 10% o menos del total de lotes por segundo.
Espero que te haya gustado el video, si es así por favor, deja tu me gusta y suscríbete al canal que nos ayuda mucho. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram al que te puede unir. En este grupo estamos creando una comunidad de usuarios y administradores de SQL Server donde cualquiera pueda preguntar sus dudas y compartir sus casos prácticos para que todos seamos mejores profesionales. ¡Hasta la próxima!
En este tercer Video Blog nos adentramos en QueryStore, una de las herramientas más potentes que Microsoft pone a nuestra disposición de manera nativa para monitorizar el rendimiento de nuestras bases de datos SQL ya sea en SQL Server o en Azure.
Como ya os prometí en el post de ayer donde vimos la teoría que rodea a esta herramienta, hoy vamos a aprovechar las ventajas del formato de Video Blog para ver todas las opciones de visualización de datos y configuración de la herramienta que necesitamos para convertirnos en verdaderos profesionales del rendimiento en SQL.
Vistas de QueryStore
QueryStore pone a nuestra disposición varias vistas con diferente información de lo más útil.
Regresed Queries: Nos va a permitir localizar las consultas que han sufrido una degradación de rendimiento.
Overall Resource Consumption: Muestra el consumo de los diferentes recursos a lo largo del tiempo en diferentes gráficos de barras.
Top Resource Consuming Queries: Nos va a mostrar las consultas que más recursos han consumido de un recurso que nosotros elijamos en un periodo a elegir entre 5 minutos y varios años.
Queries With Forced Plans: Aquí podremos encontrar las consultas a las que les hemos forzado un plan de ejecución en concreto.
Queries With High Variation: Esta vista nos mostrará las consultas con gran variación en su consumo de recursos, ya sea a mejor o peor.
Query Waits Statistics: Este informe es uno de los más importantes y por el que yo siempre empiezo a mirar. En el vamos a ver cuales son los recursos que causan cuellos de botella en el rendimiento de nuestras consultas.
Tracked Queries: En este último dashboard vamos a poder hacer seguimiento del rendimiento de una consulta en concreto que nosotros elijamos.
Objetivos de la optimización en QueryStore
El fin principal de esta herramienta no es otro que ayudarnos a mejorar el rendimiento de nuestras consultas. Es importante remarcar, que una buena optimización no solo mejorará los tiempos de nuestros procesos sino que, además, reducirá el consumo de recursos permitiéndonos un gran ahorro en infraestructura tanto si tenemos servidores locales como en la nube. En este último escenario, donde el pago por uso parece ya un estándar este ahorro de recursos puede marcar la diferencia entre que nuestro proyecto sea o no rentable.
Conclusión
QueryStore es una gran herramienta que nos va a permitir optimizar el rendimiento de las consultas y ahorrar costes tanto en SQL Server como en Azure SQL. A través de sus diferentes informes vamos a ser capaces de localizar y poner solución a los problemas de nuestro servidor. Espero que este artículo te haya proporcionado una visión profunda del almacén de consultas en SQL Server y Azure. Como siempre, estamos aquí para ayudarte. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Todos los que nos dedicamos al mundo de las bases de datos, ya sea como administradores o como usuarios, siempre deberíamos estar buscando formas de mejorar el rendimiento y la eficiencia de las consultas. Por eso, hoy vamos a explorar una herramienta muy poderosa que puede ayudarnos a hacer precisamente eso: el almacén de consultas o Query Store disponible de forma nativa tanto en SQL Server como en Azure.
¿Qué es el Query Store?
El almacén de consultas es una característica que permite rastrear y revisar el historial de ejecución de consultas en SQL Server y Azure. Es como la “caja negra” de los aviones pero para nuestras consultas SQL en SQL Server o Azure. Gracias a esta información de Query Store vamos a lograr una visión detallada de cómo se están ejecutando nuestras consultas a lo largo del tiempo y con ello, localizar problemas o puntos de mejora en el rendimiento.
Beneficios de Query Store
Query Store ofrece muchos beneficios, vamos a centrarnos en los principales. Lo principal para mi es que nos permite identificar consultas de alto consumo de recursos. Esto, por sí solo ya sería un motivo de peso para valorar configurarlo en nuestros sistemas pero, además, nos va a facilitar ver cómo cambia el rendimiento de las consultas con el tiempo y entender cómo las diferentes configuraciones afectan el rendimiento de las consultas.
Configuración en SQL Server
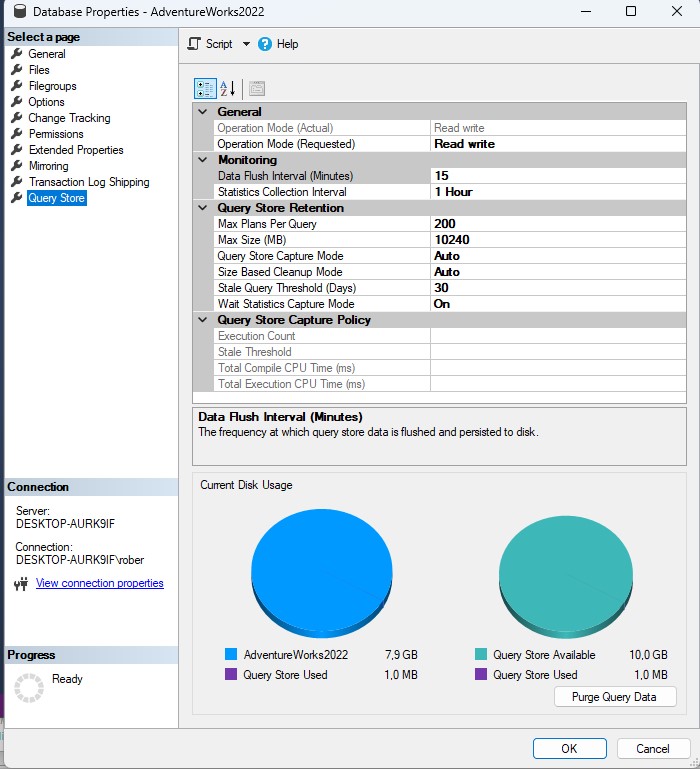
En SQL Server, el almacén de consultas se puede habilitar a nivel de base de datos. Una vez habilitado, comenzará a recopilar datos sobre las consultas ejecutadas en la base de datos. Y ya está, desde ese preciso momento podemos usar esta información para identificar consultas problemáticas y tomar medidas para mejorar su rendimiento. Pero, no nos saltemos pasos, vamos a ver en detalle la ventana de configuración y repasar sus opciones.
Como podemos ver la configuración es bastante sencilla. Deberemos indicar algo más de media docena de parámetros y aplicar los cambios. Como es habitual, tenemos un cuadro de texto bajo las opciones donde se nos especifica que hace cada una de esas configuraciones. Profundizaremos en esta configuración en futuros post así que no vamos a complicar más esta explicación.
Configuración en Azure
En Azure es incluso más sencillo, Query Store es una característica incorporada y habilitada por defecto tanto en Azure SQL Database como en Azure SQL Managed Instance. Al igual que en SQL Server, nos proporciona información valiosa sobre el rendimiento de nuestras consultas. Además, como pudimos ver en la beta presentada este fin de semana en el evento Global Azure Spain, se integra con Azure Copilot para que podamos preguntar directamente a la IA de Microsoft cuáles son los problemas y obtener toda la información en lenguaje natural.
Uso de Query Store
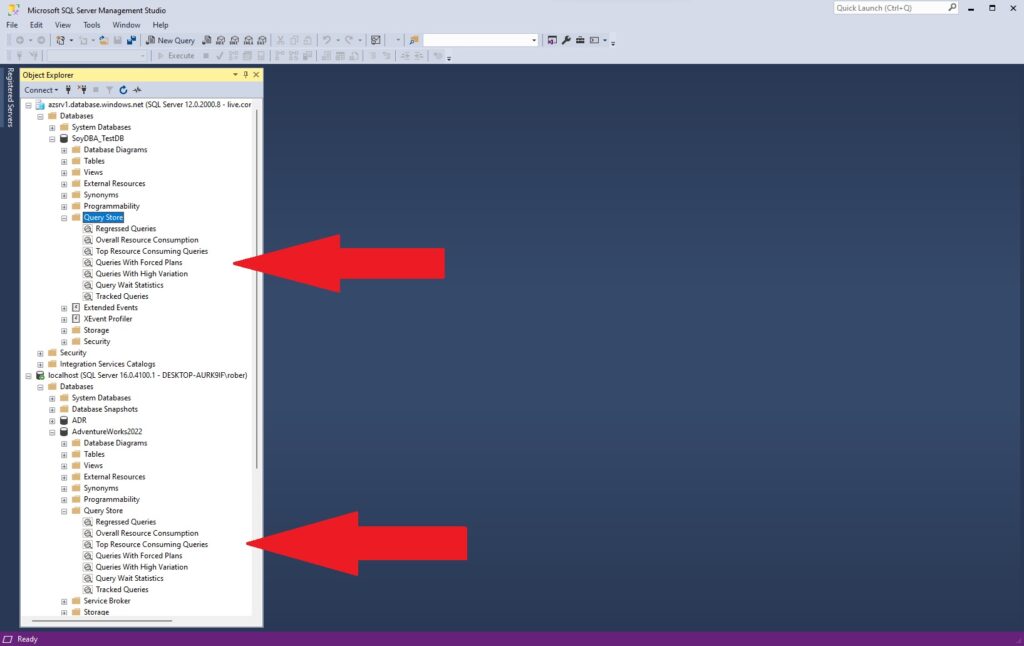
Una vez habilitado Query Store en SQL Server o de manera automática en las bases de datos de Azure ya dispondremos de los informes correspondientes dentro del apartado Query Store en la base de datos.
Podéis apreciar en la imagen que, una vez en nuestro SSMS no hay diferencias entre la base de datos de Azure y la que está en mi instancia local. Los informes son los mismos y van a tener la misma información. Si queréis profundizar más sobre los distintos informes y su funcionamiento estad atentos al blog que mañana publicaremos un video donde os lo enseñaré en detalle.
Conclusión
El almacenamiento de consultas es una herramienta poderosa para la administración de bases de datos en SQL Server y Azure. Nos permite rastrear y analizar el rendimiento de nuestras consultas, lo que nos ayuda a optimizar nuestras bases de datos y mejorar la eficiencia. Si aún no estás utilizando el almacenamiento de consultas, te animamos a que lo explores y veas cómo puede beneficiar a tu entorno de base de datos.
Esperamos que este artículo te haya proporcionado una visión profunda del almacén de consultas en SQL Server y Azure. Como siempre, estamos aquí para ayudarte en tu viaje de administración de bases de datos. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de Telegram y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Volvemos a la carga con un artículo sobre índices de esos que tanto nos gustan. Esta vez vamos a hablar de un tema muy importante y es detectar qué índices están más fragmentados y cómo solucionarlo. A menudo vemos que una mala gestión de los planes de mantenimiento provocan una degradación del rendimiento de las consultas y eso, gran parte de las veces es debido a un problema de fragmentación de índices o falta de mantenimiento de las estadísticas. Hoy vamos a centrarnos en el primero de estos aspectos.
¿Cómo detectar fragmentación en los índices?
Para ver la fragmentación de un índice en concreto podemos hacerlo desde el entorno gráfico de nuestro SSMS, haciendo click derecho sobre el objeto y mirando sus propiedades. Sin embargo, esto no es práctico cuando tenemos cientos de índices en nuestra base de datos y queremos saber de un vistazo cuales son los más fragmentados y cuanto. Para ello, usaremos una consulta sobre la función de sistema sys.dm_db_index_physical_stats.
Otra de las cosas que debemos tener en cuenta es el tamaño de nuestra tabla, con menos de 1000 páginas, el motor de base de datos directamente ignorará los índices nonclustered y, en el caso de los clustered, tampoco vamos a notar diferencia.
Con esto en mente vamos a preparar el script.
SELECT SCHEMA_NAME(ob.[schema_id]) Esquema, ob.[name] AS Objeto, i.[name] AS Indice, ob.type_desc AS TipoObjeto, i.type_desc AS TipoIndice, stats.page_count AS Paginas, stats.avg_fragmentation_in_percent AS Fragmentacion FROM sys.dm_db_index_physical_stats (db_id(), NULL, NULL, NULL, NULL) stats INNER JOIN sys.indexes i ON stats.[object_id] = i.[object_id] AND stats.index_id = i.index_id INNER JOIN sys.objects ob ON i.[object_id] = ob.[object_id] WHERE ob.[type] IN('U','V') AND ob.is_ms_shipped = 0 AND i.[type] IN(1,2,3,4) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND stats.alloc_unit_type_desc = 'IN_ROW_DATA' AND stats.index_level = 0 AND stats.page_count >= 1000 AND stats.avg_fragmentation_in_percent > 5 ORDER BY stats.avg_fragmentation_in_percent desc
Revisemos el script, por un lado podemos ver que a la función para ver las estadísticas de los índices le estamos pasando el id de la base de datos actual para que se ejecute en ese contexto. Esto es para evitar que se ejecute por todas las bases de datos y podamos tener un problema de rendimiento con esta consulta. Por otro lado vemos que solo afecta a tablas y vistas de usuario que tengan un índice clustered, el tipo de índice 0 está excluido de los filtros. Las tablas HEAP (sin índice clustered) necesitan otro tipo de tratamiento. Podemos ver también el filtro para solo mostrar índices con más de 1000 páginas y el de fragmentación superior al 5%, que suele considerarse el umbral de fragmentación aceptable.
Solucionar fragmentación de índices
Ahora que sabemos cuales son los índices más fragmentados debemos actuar y solucionar el problema. Sabemos que tenemos a nuestra disposición dos alternativas: reorganizar o reconstruir. Para elegir entre una opción u otra tenemos varios factores a tener en cuenta.
Por un lado tenemos el modo de operación de estas instrucciones, reorganizar siempre es una operación online lo que significa que solo generará sobre nuestro índice un intento de bloqueo compartido. El índice se podrá seguir leyendo durante la reordenación sin causar bloqueos. En cuanto a la reconstrucción, solo es online si se lo especificamos manualmente y eso solo es posible en ediciones Enterprise de SQL Server o en las bases de datos o instancias gestionadas de Azure. Si la reconstrucción es offline se generará un bloqueo exclusivo sobre el índice.
Por otro lado, la reconstrucción es más eficiente que la reorganización para porcentajes elevados de fragmentación y eso deberemos tenerlo también muy en cuenta.
¿Debería reorganizar o reconstruir mis índices con mucha fragmentación?
Esto no es una ciencia exacta y es un tema sobre el que hay muchas opiniones discordantes. Normalmente se habla de reorganizar los índices con una fragmentación superior al 5 o 10% y menor al 15 o 30%. Como veis es una horquilla muy amplia y para atinar tenemos que pensar en las las implicaciones de estas operaciones que ya hemos visto antes. Yo os voy a contar cómo lo hago yo pero esto es totalmente personal y deberás adaptarlo a cada caso.
Escenario 1: Mantenimiento programado
En este primer escenario estamos hablando de un mantenimiento programado dentro de una ventana de mantenimiento en la que no hay interferencia con otros procesos. Este caso es el más sencillo porque no tenemos que pensar en no entorpecer a nadie. En estos casos yo pongo el umbral para empezar a actuar en un 5%. Si estamos hablando de una edición Standard de SQL Server reorganizaré los índices con una fragmentación entre un 5 y un 20% y reconstruiré los de mayor fragmentación. Para ediciones Enterprise o Azure reduciré esa horquilla para reorganizar entre un 5 y un 15% y haré reorganizaciones online a partir del 15%.
Escenario 2: Problema puntual de rendimiento
En este escenario estamos hablando de un momento de carga de trabajo elevada en el que hemos recibido o detectado una incidencia por problemas de rendimiento. Tenemos que actuar rápido para solventar la situación pero entorpeciendo lo menos posible a los procesos de negocio que ya de partida tienen un rendimiento mermado. En estos casos pongo el umbral para empezar a actuar en fragmentaciones por encima del 10% en vez del 5. A partir de ahí, si tenemos la suerte de contar con una edición Enterprise, o estamos en Azure, no hay más problema, reconstruiremos con las mismas condiciones que en el escenario anterior, a partir del 15%. Para una edición Standard, donde si vamos a generar bloqueos si reconstruimos, intentaremos reorganizar hasta el 30% de fragmentación.
Solucionar estadísticas desactualizadas
Las estadísticas son clave para SQL Server. Como ya hemos comentado en este blog muchas veces, unas estadísticas desfasadas pueden tener el mismo impacto negativo o peor que un índice fragmentado. Por este motivo, es importante tenerlas en cuenta a la hora de realizar nuestros mantenimientos o enfrentar una incidencia por degradación de rendimiento. Una reconstrucción de índices siempre actualizará las estadísticas asociadas a ese índice pero en el caso de las reorganizaciones deberemos hacerlo manualmente. Tenemos que contar también con que una actualización de estadísticas es más ligera y rápida que un mantenimiento de índices por lo que, en caso de una degradación de rendimiento de una consulta puntual, yo siempre actualizo las estadísticas de las tablas involucradas como primera medida.
Conclusión
Ante un problema de rendimiento, tenemos que verificar el estado de nuestros índices y estadísticas. Además, consultar su nivel de fragmentación será clave a la hora de decidir si vamos a reorganizarlo o reconstruirlo y, todo esto, siempre sin dejar de lado las estadísticas. Tened en cuenta que por mucho que tengamos implementada una solución de mantenimiento de índices y estadísticas nunca vamos a estar 100% seguros de que no va a haber una variación tal de datos que nos va a generar fragmentación o a dejar desfasadas nuestras estadísticas. Es importante que mantengamos una monitorización y vigilancia continua para garantizar el mejor desempeño de nuestros SQL Server.
Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!
Colabora con nosotros
SoyDBA.es es gratis para ti y siempre va a serlo. Sin embargo, a nosotros si que nos cuesta dinero además de mucho esfuerzo. Puedes colaborar con nosotros con un donativo por PayPal o usando nuestros enlaces de afiliado para colaborar sin que te cueste nada. Tenemos enlace de Amazon y de Aliexpress
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.