En este artículo vamos a hablar de una de las novedades más interesantes que trajo SQL Server 2019: el Accelerated Database Recovery (ADR). Se trata de una característica que mejora el rendimiento y la disponibilidad de las bases de datos al reducir el tiempo de recuperación ante fallos o transacciones largas. ¿Quieres saber cómo funciona y cómo activarlo? ¡Sigue leyendo!
¿Qué es el Accelerated Database Recovery?
El Accelerated Database Recovery (ADR) es una funcionalidad que cambia la forma en que SQL Server gestiona el registro de transacciones y el proceso de recuperación. Con ADR, SQL Server utiliza una estructura de datos llamada Persistent Version Store (PVS) que almacena las versiones de las filas modificadas por las transacciones en curso. De esta forma, cuando se produce un rollback o un fallo del sistema, SQL Server no tiene que deshacer las modificaciones una por una, sino que simplemente recupera las versiones anteriores de las filas desde el PVS. Esto hace que el tiempo de recuperación sea mucho más rápido y predecible, independientemente del tamaño o la duración de las transacciones.
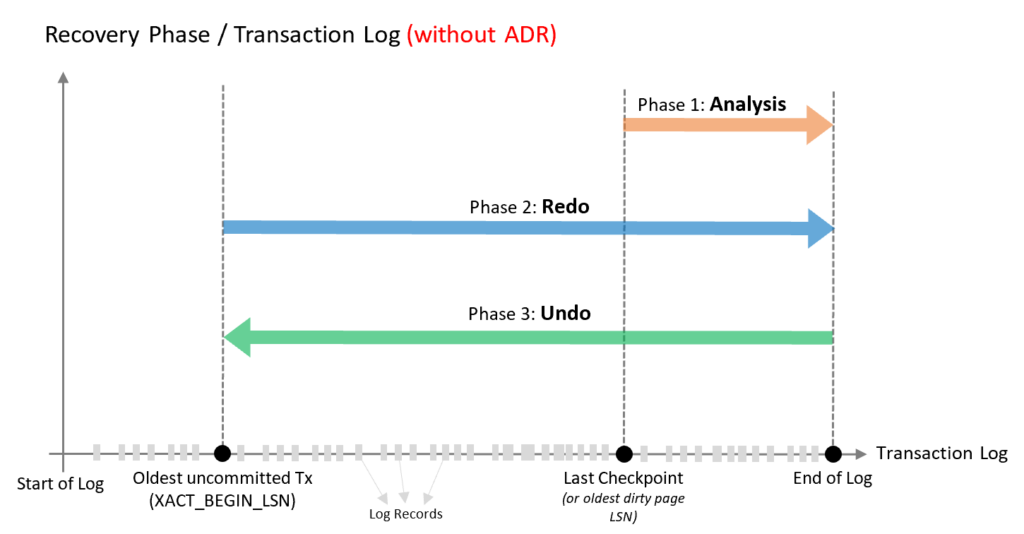
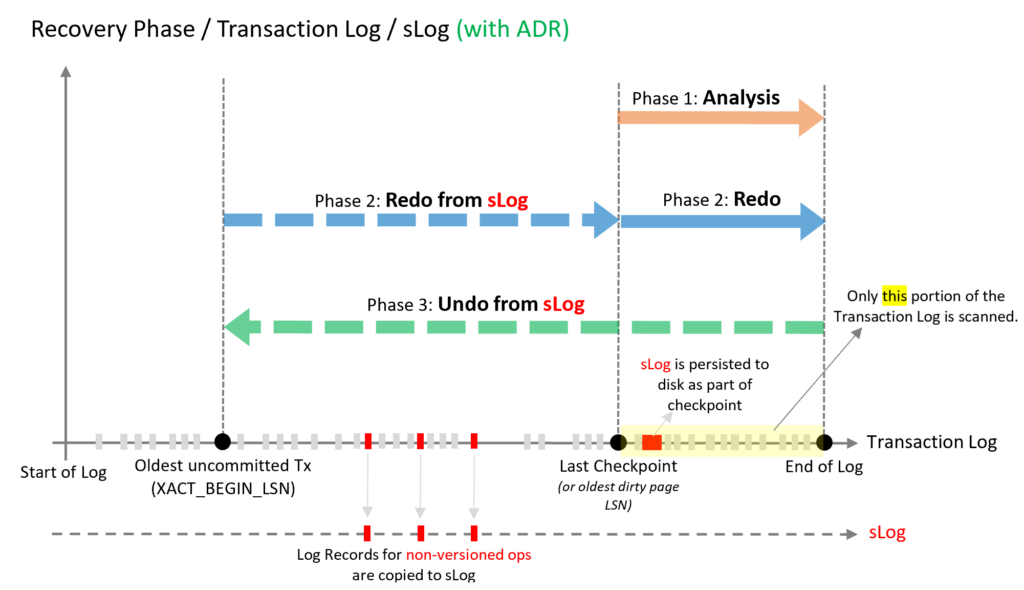
Además, el ADR también elimina el problema de los bloqueos por transacciones activas que consumen todo el espacio del log. Con ADR, SQL Server puede truncar el log sin esperar a que se completen las transacciones activas, ya que las versiones de las filas están en el PVS y no en el log. Esto evita que el log se llene y cause problemas de rendimiento o disponibilidad.
¿Qué ventajas tiene el Accelerated Database Recovery?
El Accelerated Database Recovery tiene varias ventajas para los administradores y desarrolladores de bases de datos:
- Reduce el tiempo de recuperación ante fallos o cancelaciones de transacciones. Con ADR, el tiempo de recuperación es constante y no depende del número o tamaño de las transacciones. Esto mejora la disponibilidad y la continuidad del negocio.
- Reduce el consumo de espacio del log. Con ADR, SQL Server puede truncar el log más frecuentemente y liberar espacio para nuevas transacciones. Esto reduce la necesidad de ampliar el log o hacer backups frecuentes.
- Reduce los bloqueos por transacciones activas. Con ADR, SQL Server no tiene que esperar a que se terminen las transacciones activas para truncar el log. Esto evita los bloqueos por falta de espacio en el log y mejora el rendimiento y la concurrencia.
- Facilita la gestión de transacciones largas o complejas. Con ADR, los desarrolladores pueden usar transacciones largas o complejas sin temor a que afecten al rendimiento o la disponibilidad de la base de datos. Esto permite implementar procesos de negocio más sofisticados y flexibles.
Una cosa más que debes saber sobre el ADR es que también afecta al funcionamiento de los checkpoints. Los checkpoints son procesos que escriben las páginas modificadas en memoria al disco para facilitar la recuperación. Con ADR, los checkpoints son más rápidos y eficientes, ya que solo escriben las páginas que han sido modificadas desde el último checkpoint y no dependen del estado de las transacciones. Esto también reduce la carga de E/S y mejora el rendimiento de la base de datos.
¿Cómo activar el Accelerated Database Recovery?
El Accelerated Database Recovery se activa a nivel de base de datos con el siguiente comando:
ALTER DATABASE <nombre_de_la_base_de_datos> SET ACCELERATED_DATABASE_RECOVERY = ON;Es importante tener en cuenta que para activar el ADR, la base de datos debe estar en modo de compatibilidad 150 o superior (SQL Server 2019 o Azure SQL Database). Además, se recomienda tener suficiente espacio libre en el disco donde se almacena el PVS, ya que este puede crecer según la actividad de las transacciones. PVS se almacena en TempDB
Práctica
En la teoría todo es muy bonito, ahora vamos a verlo en la práctica a ver si es cierto. Para ello crearemos dos bases de datos, una con ADR activado y otra sin ello. Vamos a ejecutar sobre ellas unas consultas pesadas que se inicien justo a la vez y antes de que terminen vamos a forzar un apagado del servicio de SQL Server. Para terminar levantaremos de nuevo el servicio y veremos en el Log de SQL Server cuánto han tardado en estar disponibles:
Para crear las bases de datos he usado este script:
USE MASTER
GO
CREATE DATABASE NOADR
GO
ALTER DATABASE NOADR SET ACCELERATED_DATABASE_RECOVERY = OFF;
GO
CREATE DATABASE ADR
GO
ALTER DATABASE ADR SET ACCELERATED_DATABASE_RECOVERY = ON;Lugo he ejecutado estos scripts en dos ventanas separadas (fijaos que se inician exactamente a la misma hora):
WAITFOR TIME '19:30:30';
USE ADR;
GO
DROP TABLE IF EXISTS dbo.t1, dbo.t2, dbo.t3;
SELECT o1.* INTO dbo.t1 FROM sys.all_columns c1 CROSS JOIN sys.all_objects o1
SELECT o2.* INTO dbo.t2 FROM sys.all_columns c2 CROSS JOIN sys.all_objects o2
SELECT o3.* INTO dbo.t3 FROM sys.all_columns c3 CROSS JOIN sys.all_objects o3WAITFOR TIME '19:30:30';
USE NOADR;
GO
DROP TABLE IF EXISTS dbo.t1, dbo.t2, dbo.t3;
SELECT o1.* INTO dbo.t1 FROM sys.all_columns c1 CROSS JOIN sys.all_objects o1
SELECT o2.* INTO dbo.t2 FROM sys.all_columns c2 CROSS JOIN sys.all_objects o2
SELECT o3.* INTO dbo.t3 FROM sys.all_columns c3 CROSS JOIN sys.all_objects o3En una tercera ventana he ejecutado este script para detener el servicio justo 5 minutos después de iniciar los anteriores:
WAITFOR TIME '19:35:30';
SHUTDOWN WITH NOWAIT;Este que podéis ver ha sido el resultado, el rollback y por tanto la recuperación de la base de datos baja de 70 segundos sin ADR a 8 segundos con ADR activado:
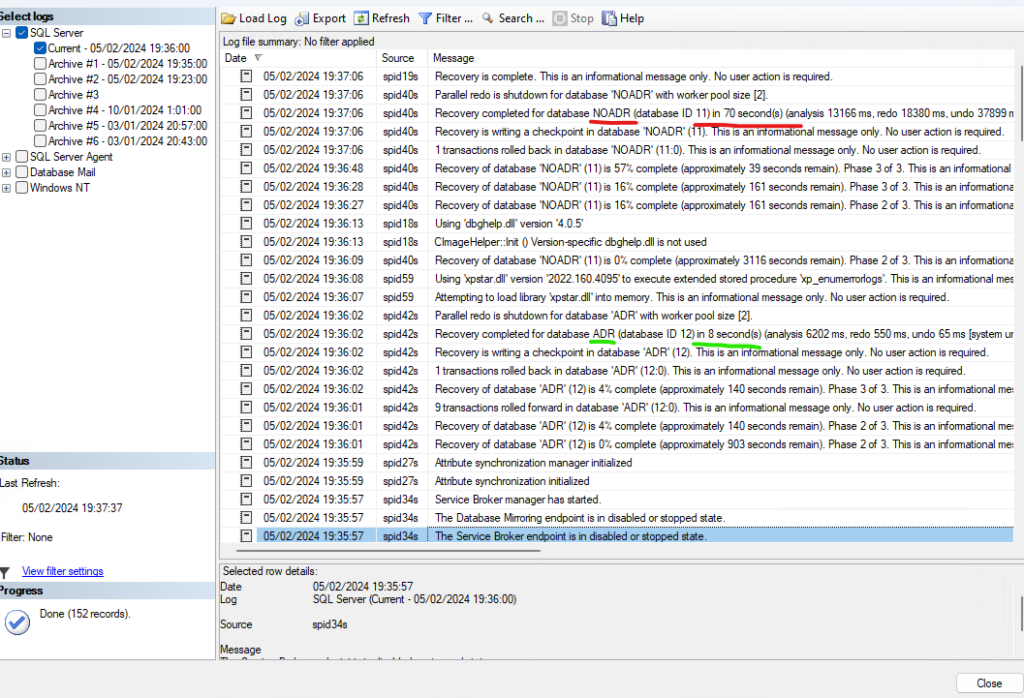
Esto creo que sobra decirlo pero, POR LO QUE MÁS QUERÁIS, NO HAGÁIS ESTA PRUEBA EN PRODUCCIÓN. Estamos probando a detener el servicio de SQL Server de manera forzada.
Conclusión
El Accelerated Database Recovery es una característica muy útil que mejora el rendimiento y la disponibilidad de las bases de datos en SQL Server 2019. Con ADR, se reduce el tiempo de recuperación ante fallos o cancelaciones de transacciones, se reduce el consumo de espacio del log, se reducen los bloqueos por transacciones activas y se facilita la gestión de transacciones largas o complejas. Si quieres aprovechar estas ventajas, te animamos a probar el ADR en tus bases de datos y a compartir tus experiencias con nosotros.
Espero que este artículo te haya resultado útil e interesante. Si tienes alguna duda o comentario, no dudes en contactarnos en Twitter o por mail o dejarnos un mensaje en los comentarios de aquí abajo. Y recuerda que también tenemos un grupo de LinkedIn al que te puedes unir.

