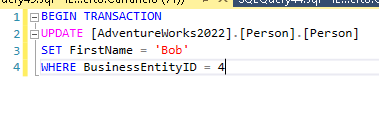En esta segunda entrada sobre los niveles de aislamiento vamos a ver qué significa en la práctica lo que vimos en el post de ayer. Si aún no lo has leído te recomiendo que vayas primero a él para saber de lo que hablamos. Vamos a comparar el mismo caso práctico con los niveles de aislamiento READ UNCOMMITTED, READ COMMITTED y READ COMMITTED SNAPSHOT.
Para que todos podáis hacer las pruebas en vuestra instalación de SQL vamos a usar la base de datos de ejemplo AdventureWorks. AdventureWorks es una base de datos de ejemplo que proporciona Microsoft y que está disponible para descargar en su web. Tanto si estáis empezando a aprender SQL como si ya lleváis tiempo y queréis estar al día os recomiendo siempre que tengáis una instalación donde hacer pruebas con alguna base de datos de ejemplo. Otra buena base de datos que no debería faltar en vuestra instalación de pruebas es la versión SQL de los datos anonimizados de stackoverflow que proporciona Brent Ozar.
Caso Práctico
Este ejemplo es uno de los más típicos que nos vamos a encontrar en nuestro día a día como DBA. Vamos a simular 2 transacciones, la primera va a hacer una actualización de la tabla de personas y mientras la actualización esté en progreso una segunda transacción va a intentar leer los datos.
NIVEL DE AISLAMIENTO READ COMMITTED
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla. Se genera un bloqueo exclusivo sobre el registro.
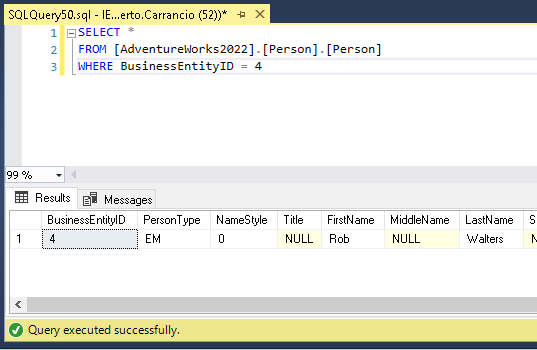
Cuando la segunda sesión va a leer se queda en espera, el intento de bloqueo compartido sobre el registro no es compatible con el bloqueo exclusivo de la transacción de la primera sesión.
rollback
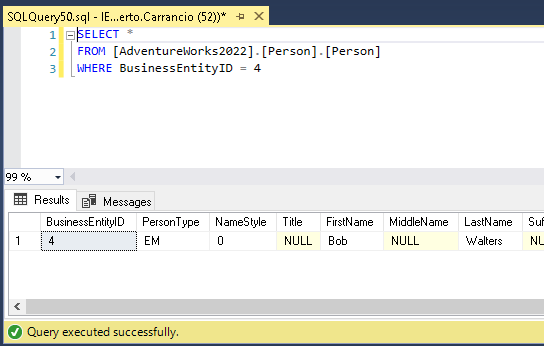
La transacción se aborta. Se genera un rollback y se libera el bloqueo exclusivo.
Con el bloqueo exclusivo liberado la segunda sesión ya es capaz de devolver los datos solicitados.
NIVEL DE AISLAMIENTO READ COMMITTED SNAPSHOT
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla. Se genera un snapshot del dato anterior a la transacción en TempDB
Cuando la segunda sesión solicita ese registro lo puede recuperar del snapshot en TempDB.
rollback
La transacción se aborta. Se genera un rollback y se elimina el snapshot.
NIVEL DE AISLAMIENTO READ UNCOMMITTED
SESIÓN 1
SESIÓN 2
NOTAS
La primera sesión inicia una operación de escritura sobre la tabla.
Cuando la segunda sesión solicita ese registro lo lee directamente aunque se esté modificando.
rollback
La transacción se aborta y se genera un rollback
En una segunda lectura la sesión 2 recupera un dato diferente.
Conclusión
Hemos podido ver que significa leer datos sucios y qué implicaciones tiene. Además, hace unos días vimos también el peligro de las lecturas fantasma de NOLOCK que también se producen en el nivel de aislamiento READ UNCOMMITTED. Tras esta serie de artículos estamos preparados para elegir los niveles de aislamiento correctos para nuestras bases de datos.
Ahí va mi recomendación personal: si tenemos que hacer una prueba o leer un dato puntualmente en un entorno productivo pero sin afectar a la producción podemos usar READ UNCOMMITTED. No deberíamos usar este nivel de aislamiento en ningún caso más. Usaremos un nivel de aislamiento READ COMMITTED SNAPSHOT si nuestra base de datos tiene un problema de bloqueos. Si estamos desarrollando una base de datos nueva mi recomendación también sería READ COMMITTED SNAPSHOT. Por el contrario, en la mayoría de los casos, si todo funciona con la configuración por defecto mejor dejarlo como está. Al fin y al cabo, un cambio que va a afectar a todas las transacciones requiere un esfuerzo en pruebas que rara vez nos será rentable si no es para solucionar un problema específico.
Como os prometí en el pasado artículo sobre el uso de NOLOCK hoy vamos a profundizar sobre los distintos niveles de aislamiento que implementa SQL Server. Es teoría básica de bases de datos, pero me parece imprescindible volver a ello frecuentemente y afianzar conceptos clave que marcarán el funcionamiento de nuestra base de datos. Aunque los niveles de aislamiento son algo común de todos los gestores de bases de datos, no todos implementan todos ni usan el mismo nivel por defecto. Aunque según el estándar SQL existen 4 niveles de aislamiento, en este artículo nos vamos a centrar en los niveles de aislamiento que implementa SQL Server. No solo porque es mi base de datos principal, sino también porque SQL Server implementa 5+1 niveles de aislamiento frente a los 3 que soporta Oracle o los 4 del estándar de PostgreSQL.
Antes de profundizar en los niveles de aislamiento, hay que afianzar otra serie de conceptos básicos como las propiedades ACID de una base de datos y la gestión de concurrencia basada en bloqueos.
Gestión de transacciones
Tenemos que entender las transacciones como la operación más básica del motor de base de datos. Son operaciones indivisibles y tienen que terminar completamente. Para entenderlo podemos compararlo con una transacción comercial, Tu pides un producto y esperas a que el vendedor te diga el precio. El vendedor te dice el precio y espera a que le des el dinero. Tu le das el dinero y esperas a que te de el producto. Si la transacción es correcta llegará hasta el final, pero si se detiene en cualquiera de las fases se volverá a la situación inicial donde tu tienes el dinero pero no el producto.
Con este ejemplo en mente vamos a explicar lo que son las propiedades ACID (siglas en inglés de Atomicidad, Consistencia, Aislamiento y Durabilidad).
Atomicidad: Como hemos dicho, las transacciones son la operación básica de las bases de datos y deben ser indivisibles. Al igual que en nuestro ejemplo de la compra, para que la operación se finalice se tienen que completar todos los pasos de la transacción.
Consistencia: Toda transacción debe mantener la coherencia de la base de datos. Si no termina correctamente tiene que hacer rollback (deshacer los cambios) y volver al estado original. Es lo mismo que cuando decíamos que si nuestra compra se interrumpe volvemos a tener el dinero pero no el producto.
Aislamiento: Cada transacción es independiente de las demás. El comportamiento de esta característica cambiará en función del nivel, que es lo que vamos a ver más adelante. En nuestro ejemplo, nuestra compra no se ve afectada por las demás compras.
Durabilidad: Todas las transacciones tienen que estar registradas en la base de datos y permanecer en ella después de una interrupción de servicio. Cuando el servicio se reanude, las transacciones confirmadas se verán reflejadas en la base de datos, mientras que las no confirmadas sufrirán un rollback.
Gestión de concurrencia
Tipos de bloqueos
Por defecto, SQL Server implementa los bloqueos para garantizar el aislamiento de las transacciones. En este contexto podemos encontrarnos con dos tipos de bloqueos, los bloqueos compartidos y los bloqueos exclusivos. Entenderemos el bloqueo compartido como el tipo de bloqueo para operaciones de lectura y los bloqueos exclusivos como los bloqueos para las escrituras.
Compatibilidad entre bloqueos
Cada operación de lectura generará un bloqueo compartido sobre el recurso que lea. Pueden existir varias operaciones de lectura simultáneas sobre un mismo recurso y cada una de ellas generará un bloqueo compartido. Las operaciones de escritura, sin embargo, generarán un bloqueo exclusivo, ya que mientras hay una escritura en curso no puede haber más operaciones (ni lecturas ni escrituras) sobre ese recurso.
Cuando se inicia una operación de escritura, intentará generar un bloqueo exclusivo en el recurso afectado. Si existen bloqueos (compartidos o exclusivos) en el recurso este intento de bloqueo exclusivo no podrá iniciarse y esperará a que termine el resto de transacciones.
Niveles de aislamiento
Como a estas alturas ya sabrás, los niveles de aislamiento son una forma de controlar el acceso concurrente a los datos de una base de datos, es decir, cómo se comporta el sistema cuando varios usuarios o procesos intentan leer o modificar los mismos registros al mismo tiempo. Los niveles de aislamiento afectan al rendimiento y a la consistencia de los datos, así que vamos a verlos en detalle.
Read uncommitted isolation
Este es el nivel más bajo de aislamiento, permite leer los datos que están siendo modificados por otras transacciones, incluso si éstas no han terminado o confirmado sus cambios. Esto puede provocar problemas como lecturas sucias, lecturas no repetibles o lecturas fantasma, que veremos más adelante. Este nivel tiene el mejor rendimiento, pero el peor nivel de consistencia. Es el equivalente al uso de NOLOCK que vimos en el post anterior.
Read committed isolation
Este es el nivel predeterminado de SQL Server. Impide leer los datos que están siendo modificados por otras transacciones hasta que éstas terminen y confirmen sus cambios. Esto evita las lecturas sucias, pero no las lecturas no repetibles o las lecturas fantasma. Este nivel tiene un buen equilibrio entre rendimiento y consistencia, pero puede no ser suficiente para algunas operaciones críticas.
Read committed snapshot isolation (RCSI)
Este es el nivel predeterminado de Azure SQL Database y de Oracle, por ejemplo. Es, simplemente, una variación de Read Committed que en vez de generar bloqueos genera snapshots. Los snapshots son la versión original de los datos modificados, se almacenan en tempdb mientras dure la transacción bloqueante. El resultado es que una transacción de lectura nunca bloqueará a una escritura y viceversa. Se diferencia de read uncommitted en que, aunque el dato que estás leyendo pueda estarse cambiando, lo que lees si que ha sido un dato confirmado en algún momento.
Repeatable read isolation
Este nivel garantiza que si una transacción lee un registro, nadie podrá modificarlo hasta que la transacción termine. Esto evita las lecturas no repetibles, pero no las lecturas fantasma. Este nivel tiene un peor rendimiento que el anterior, ya que bloquea más registros y puede generar más contención.
Serializable isolation
Este es el nivel más alto de aislamiento, que impide cualquier modificación concurrente de los datos que lee una transacción. Esto evita tanto las lecturas no repetibles como las lecturas fantasma, pero tiene el peor rendimiento y el mayor riesgo de bloqueos y esperas.
Snapshot isolation
Este nivel permite leer los datos tal y como estaban al inicio de la transacción, sin importar si otros usuarios o procesos los han modificado después. Esto evita todos los problemas de consistencia mencionados, pero tiene un mayor coste de almacenamiento y procesamiento, ya que requiere mantener varias versiones de los datos en la base de datos. Puede generar errores cuando concurren varios procesos de escritura.
A modo resumen podemos ver estas dos tablas:
* Snapshot es un nivel de aislamiento solo a nivel de transacción. En caso de colisión en la escritura devuelve un error. ** SERIALIZABLE También bloquea la inserción de registros nuevo
Problemas de no elegir el nivel de aislamiento correcto
Hemos hablado de que los niveles de aislamiento nos puede ocasionar una serie de problemas como lecturas sucias, lecturas no repetibles y lecturas fantasma, pero, ¿qué son estos términos?
– Lectura sucia: No es leer “50 sombras de Grey”. Ocurre cuando una transacción lee un dato que está siendo modificado por otra transacción, pero ésta no ha confirmado sus cambios. Por ejemplo, si la transacción A modifica el precio de un producto, pero no lo confirma, y la transacción B lee ese precio, puede obtener un valor incorrecto o inconsistente.
– Lectura no repetible: Ocurre cuando una transacción lee dos veces el mismo dato, pero obtiene valores distintos porque otra transacción lo ha modificado entre medias. Por ejemplo, si la transacción A lee el stock de un producto, luego la transacción B lo reduce al comprarlo, y la transacción A lo vuelve a leer, obteniendo un valor menor al esperado.
– Lectura fantasma: Ocurre cuando una transacción lee un conjunto de datos que cumple cierto criterio, pero luego otra transacción inserta o elimina registros que también cumplen ese criterio. Por ejemplo, si la transacción A cuenta el número de clientes que viven en una ciudad, luego la transacción B añade o borra clientes de esa ciudad, y la transacción A vuelve a contarlos, puede obtener un número diferente al inicial.
Conclusión
Como hemos visto, elegir el nivel de aislamiento ideal para nuestra base de datos es un pulso entre rendimiento y coherencia de los datos. Recuerda que debes elegir el nivel adecuado para cada caso, teniendo en cuenta las ventajas e inconvenientes de cada uno. Un nivel de aislamiento serializable sería lo más seguro pero prácticamente imposibilita la concurrencia entre varios procesos, mientras que un Read Uncommitted ofrece el mejor rendimiento a un precio demasiado alto.
A partir de aquí, en tu mano está elegir el nivel de aislamiento ideal para tu base de datos. Solo espero que este post te haya ayudado a entender mejor qué son los niveles de aislamiento en SQL Server y cómo afectan a la consistencia y al rendimiento de tu base de datos. Si tienes alguna duda o comentario, puedes dejarlo abajo en los comentarios, mandarme un mail o contactarme por Twitter.
SQL Server implementa varios niveles de aislamiento sobre los que hablaremos más en profundidad en un futuro post, aunque por defecto se implementa el nivel READ COMMITTED o lecturas confirmadas. Sin embargo, esto se puede cambiar a nivel base de datos, transacción o incluso para una tabla dentro de una misma transacción. Hoy nos vamos a centrar en este último caso para lo que vamos a usar el HINT NOLOCK. Vamos a ver casos prácticos de uso aunque antes aclararemos algunos conceptos básicos.
Primero de todo, ¿qué es un HINT?
Un HINT (en español sugerencia de consulta) es un parámetro que indicamos a la hora de escribir nuestras consultas SQL y modifican el comportamiento del optimizador de consultas y del motor de base de datos. En SQL Server tenemos HINTS de 3 tipos: los HINTS de combinación, para especificar el tipo de JOIN que va a aplicar el motor de base de datos (Loop, Merge, Hash o Remote). Los HINTS de consulta, que se aplican con la cláusula OPTION y afectan a todos los operadores de la consulta y, por último, los HINTS de tabla que requieren la cláusula WITH y se usan para invalidar el comportamiento predeterminado del optimizador de consultas sobre esa tabla durante la instrucción DML.
Los HINT de tabla se pueden aplicar sin la cláusula WITH aunque esto es una característica en desuso que dejará de tener compatibilidad en futuras versiones de SQL Server. Deberemos declarar la cláusula WITH para asegurarnos la futura compatibilidad de nuestro código.
WITH (NOLOCK) un poco (más) de teoría
Entrando ya en lo que nos ocupa, NOLOCK es, como hemos podido ver, un HINT de tabla que le dice al motor de base de datos que no mire ni aplique bloqueos sobre esa tabla. En resumidas cuentas, es como si leyéramos nuestra tabla en un nivel de aislamiento READ UNCOMMITTED.
Así, a priori, puede parecer una buena idea usarlo, no bloqueos significa menos tiempos de espera y hasta menos consumo de recursos al no tener que dedicar esfuerzos en gestionar los bloqueos de filas, páginas o tablas. Podemos pensar, también, que los datos que estamos leyendo no cambian y por eso no nos preocupa. Sin embargo, NOLOCK tiene un “problema” y son las lecturas fantasma (no te preocupes si no entiendes nada, lo vamos a ver en la práctica).
Demostración
Preparación de un entorno de laboratorio
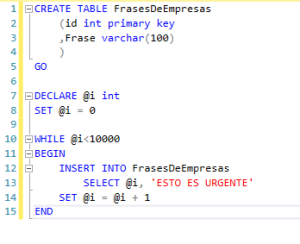
Para comprobar cómo funciona NOLOCK y sus efectos vamos a crear una tabla que vamos a llamar FrasesDeEmpresa. A continuación, vamos a añadirle 10.000 registros con una frase que normalmente se ha dicho más de 10.000 veces en todas las empresas del mundo: “ESTO ES URGENTE”
Uso de NOLOCK
Tenemos creada nuestra tabla FrasesDeEmpresa con sus 10.000 registros. Pongamos que alguien decide cambiarla y ahora la frase más escuchada es “Si funciona no lo toques”. Supongamos también que mientras alguien está cambiando todos los registros nosotros queremos leerlo. Como hemos dicho el comportamiento normal de SQL es READ COMMITTED así que hasta que quién está escribiendo no termine nosotros no podemos leer y sufriremos un bonito bloqueo.
Oh vaya, lecturas confirmadas significa que no puedo leer hasta que el que escribe no confirme que ha terminado. ¿Quién lo iba a decir? Esto era urgente así que voy a usar NOLOCK y voy a leer lo que haya en ese momento aunque esté a medias.
Problemas de NOLOCK
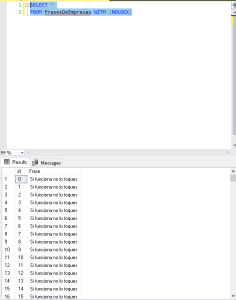
Como hemos visto gracias al HINT NOLOCK hemos podido leer lo que se estaba escribiendo. El problema viene si por lo que sea la transacción de escritura no termina y deja todo como estaba, habríamos leído una información que nunca ha sido correcta. Pero hay más, como os decía antes este no es el único problema de NOLOCK, podemos tener las denominadas lecturas fantasmas. Esto es que por leer datos que se están manipulando nos encontremos con más o menos registros de los que verdaderamente hay. Veamos un ejemplo:
¿Qué ha pasado aquí? Nosotros teníamos 10.000 registros y solo los estaban actualizando. No se ha borrado ninguno y sin embargo nuestra cuenta ha contado un registro menos la mayoría de las veces.
Para entender esto tenemos que entender el comportamiento de los índices clustered. Si os fijáis, cuando he definido la tabla he definido el campo id como Primary Key lo que automáticamente lo convierte en índice clustered. Los datos están almacenados en mi disco duro ordenados por id. Cuando yo voy recorriendo todos los registros de mi tabla FrasesDeEmpersas para contar mientras otro mueve los registros de sitio me puedo encontrar con que un registro que ya he leido se mueve hacia delante y lo cuento 2 veces o con el caso contrario, que un registro que voy a leer simplemente ya no está ahí porque está detrás. Esto es lo que se conoce como lecturas fantasma y es el verdadero problema de NOLOCK y del nivel de aislamiento READ UNCOMMITTED.
Conclusión
A veces nos podemos sentir tentados de usar lecturas sucias para evitar bloqueos. Cuando esto pase, lo mejor es que dejemos lo que estamos haciendo, vayamos a tomar una cerveza y esperemos a que se nos pase. Siento ser tan tajante pero para mi no es una opción una configuración que pone en peligro cualquiera de las propiedades ACID de nuestra base de datos. Existen alternativas a los bloqueos como el nivel de aislamiento READ COMMITTED SNAPSHOT (el que implementa Oracle y no se ha acabado el mundo) que veremos en futuras entradas del blog y que nos solucionarán el problema sin poner el peligro la integridad de nuestros resultados.
Las vistas son tablas virtuales que nos devuelven datos de una consulta sobre una o varias tablas. Igual que una tabla tiene sus columnas y sus filas pero al contrario que estas ese conjunto de datos como tal no está almacenado en ningún sitio. Cada tabla tiene sus datos y la vista los lee de ahí. Entonces, ¿los resultados de datos de las vistas no se guardan en ningún sitio? En realidad hay algunos tipos de vistas que sí guardan los datos finales como es el caso de las vistas materializadas que implementan algunos gestores de bases de datos (Oracle, por ejemplo). En el caso de SQL Server este tipo de vista no está disponible, aunque no podemos descartar que se implemente en un futuro (en Azure Synapse Analytics han existido desde siempre).
¿Qué alternativa tenemos en SQL Server?
Como hemos visto antes, las vistas las vemos como si fueran una tabla pero en realidad no tienen datos, los recuperan dinámicamente de las tablas a las que se referencia. Esto es muy útil en la mayoría de los casos ya sea por simplicidad de las consultas, para abstraernos de la estructura original y simplificar la estructura saliente o para gestionar permisos. Sin embargo el uso de una vista no afecta en nada al rendimiento pues ejecuta la consulta tal cual como si la escribiéramos a mano. Si una vista lee sobre varias tablas grandes generará mucho consumo de E/S y si la definición de la vista incluye procesamientos complejos y muchas uniones entre tablas tendremos una notoria degradación de rendimiento.
Como alternativa, en SQL Server podemos hacer uso de un tipo de vista especial que son las Vistas Indexadas (o indizadas), son vistas que tienen un índice clustered por lo que si van a almacenar el conjunto de resultados en la base de datos para poder hacer una lectura plana.
Dónde usar las vistas indexadas
Las vistas indexadas ofrecen un rendimiento de lecturas mejorado al hacer uso del índice para leer los datos y no tener que ejecutar la consulta subyacente. Sin embargo, nos pueden llegar a penalizar considerablemente las operaciones de escritura al añadir no sólo otro índice donde escribir los datos sino complejidad a ese índice. Adicionalmente podremos crear tantos índices nonclustered sobre la vista como necesitemos. Al igual que ocurre con los índices de las tablas en nuestra mano queda medir el coste/beneficio y valorar su idoneidad.
Con las vistas indexadas notaremos una mejora sustancial en el rendimiento de nuestras consultas si las aplicamos sobre entornos con una gran diferencia de lecturas frente a escrituras, se me viene a la cabeza sobre todo entornos Data Warehouse, bases de datos OLAP o entornos de minería de datos. Rara vez serán recomendables en entornos con alta carga de transacciones IUD (insert, update y delete) en bases de datos OLTP.
Limitaciones de las vistas indexadas
Como ya hemos visto uno de los inconvenientes de las vistas indexadas es que la degradación en rendimiento de las escrituras es mayor que la mejora en las lecturas, esto nos limita en gran medida su uso. Sin embargo no es su única limitación, la verdad es que tienen una amplia lista de incompatibilidades y requisitos. Uno de los principales requisitos de las vistas indexadas es que hay que crearlas con la opción SCHEMABINDING esto implica que no se podrán modificar las tablas referenciadas.
Consideraciones para crear vistas indexadas
Además de tener que crear la vista como SCHEMABINDING tenemos que tener en cuenta otros aspectos importantes:
Las vistas indexadas no admiten expresiones no deterministas. Es decir, las expresiones de la vista siempre deben devolver el mismo resultado no como GETDATE() que nos devolvería un valor distinto en cada ejecución.
Las tablas y funciones dentro de la vista deben declararse con el nombre completo (esquema.tabla).
No se admiten subconsultas.
No se admiten OUTER JOINS, esto deja fuera RIGHT JOIN y LEFT JOIN.
El índice clustered de nuestra vista ocupará espacio en disco.
Solo se puede hacer referencia a tablas de la misma base de datos.
Si tenemos GROUP BY, la definición de la vista debe contener COUNT_BIG(*), pero no HAVING.
No se puede usar EXISTS, NOT EXISTS, COUNT(*), MIN, MAX, hints de tablas, TOP ni UNION.
No puede utilizar los tipos de datos text, ntext , image o XML. El tipo de datos float se puede utilizar en la vista, pero no en el índice agrupado
Como crear vistas indexadas
Para crear una vista indexada lo primero que haremos será crear la vista con la opción SCHEMABINDING
CREATE VIEW VI_Facturas_Ventas WITH SCHEMABINDING AS SELECT FC.cliente, FD.Articulo, COUNT_BIG(*) FROM Ventas.FacturasCabeceras FC INNER JOIN Ventas.FacturasDetalle FD ON FC.NumFactura = FD.NumFactura GROUP BY FC.cliente, FD.Articulo
Una vez que tenemos creada la vista tendremos que crear el índice clustered.
CREATE UNIQUE CLUSTERED INDEX CI_Facturas_Ventas ON VI_Facturas_Ventas (Cliente, Articulo);
En este punto el optimizador de consultas podrá usar nuestro índice para cualquier consulta sobre la tabla, incluso para consultas sobre las tablas sin que se use la vista aunque, esto último, sólo en ediciones Enterprise de SQL Server.
Conclusiones
Un gran poder conlleva una gran responsabilidad y las vistas indexadas son una increíble herramienta en entornos o tablas con gran cantidad de lectura y pocas modificaciones pero si no es así nos pueden hacer mucho daño al servidor. El uso de vistas indexadas de SQL Server puede ser una buena técnica para mejorar el rendimiento de las consultas al reducir el costo de E/S y la duración de las consultas, pero requiere pruebas, planificación y un estudio pormenorizado de donde usar vistas indexadas. Se debe realizar un análisis completo del impacto en el rendimiento, midiendo las mejoras en el rendimiento de lecturas frente al coste en las escrituras.
Hola, amigos y amigas del blog. Hoy vamos a hablar sobre algunos aspectos a tener en cuenta y las buenas prácticas antes de instalar SQL Server. Sé que a muchos os puede parecer una tarea trivial pero es clave para el rendimiento futuro de nuestro servidor, no queremos que nuestra instalación termine siendo un desastre, ¿verdad?
Lo primero que hay que hacer es verificar los requisitos mínimos del sistema para instalar SQL Server. No vaya a ser que nos quedemos sin espacio en el disco duro, o que nuestra memoria RAM no dé la talla. Para eso, podemos consultar la documentación oficial de Microsoft, o usar alguna herramienta como el Asistente de instalación de SQL Server, que nos ayuda a comprobar si nuestro equipo cumple con los requisitos.
Lo segundo que hay que hacer es planificar la configuración de SQL Server. Esto implica decidir qué características vamos a instalar, cómo vamos a organizar las instancias y las bases de datos, qué tipo de autenticación vamos a usar, cómo vamos a configurar la seguridad y el rendimiento, y otras opciones más. Para esto, yo siempre tengo en cuenta estos 4 puntos fundamentales:
ENTORNO
Se debe intentar que los servidores SQL sean dedicados, solo deben alojar aplicaciones de SQL server. En caso de que por necesidades de un aplicativo en SQL deba convivir con otros servicios de terceros debemos extremar la vigilancia sobre el rendimiento y la seguridad. Si seguimos las buenas prácticas de Microsoft, SQL Server no se instalará en ningún caso sobre un servidor que albergue el rol de controlador de dominio. Tampoco es recomendable instalar más de una instancia en un mismo servidor, si lo hacemos deberemos jugar después con resource governor para asegurarnos que el rendimiento de las instancias es el deseado.
SISTEMA OPERATIVO
La instalación de SQL Server se puede hacer sobre entornos Windows Server o Windows de usuario. Desde SQL Server 2017 también es posible instalar SQL Server sobre entornos Linux aunque en este caso es posible que no tengamos disponibles todas las características. En el caso de un sistema operativo Mac no hay soporte nativo, sin embargo, es posible beneficiarse de la posibilidad de instalación de SQL Server sobre contenedores Docker para tener una instancia funcional en estos entornos.
En caso de una instalación de un entorno de alta disponibilidad debe existir un Windows Server Failover Cluster entre los servidores o en el caso de Linux un clúster pacemaker.
DISCOS DUROS
Según las buenas prácticas, todo servidor SQL debe tener al menos 4 discos, uno para el sistema operativo y los de SQL: datos, log, y TempDB. Adicionalmente podrán existir más discos de datos o logs. A la hora de dimensionar los discos debemos dimensionar el disco de datos de manera que tenga capacidad suficiente para los datos actuales y futuros a medio plazo (en un mundo ideal este dato nos lo dará el equipo que solicita el servidor). Los discos de TempDB y Log deberán ser entre el 10 y el 30% de la capacidad total de los datos.
Si no nos ha quedado más remedio que instalar nuestro SQL en un servidor compartido con aplicaciones, estas deberemos instalarlas en un disco independiente a SQL Server. Del mismo modo, no es buena idea compartir discos duros entre varias instancias de SQL Server.
Para terminar con el apartado de discos duros, todos los discos de SQL server deben estar formateados con el valor bytes per cluster a 64kb. Para comprobarlo podemos ejecutar el siguiente comando de powershell: “fsutil fsinfo ntfsinfo <drive>”
SEGURIDAD
En un entorno dedicado para SQL Server solo los administradores del sistema operativo y los DBAs deberían tener acceso. Los servicios de SQL deben ejecutarse bajo cuentas de servicio que cumplan con las políticas de seguridad. En este sentido, tenemos que tener en cuenta que las cuentas que configuremos para el motor de bases de datos y para el agente de SQL Server deberán tener permisos sobre los directorios de datos o backups en función de lo que esperemos hacer en un futuro.
Con todo esto definido ya habríamos terminado de prepararnos y podemos pasar a descargar la versión de SQL que más se adapte a nuestras necesidades y, por fin, a instalar, que en este punto ya estaréis todos deseosos de empezar a cacharrear.
Esto sería todo por hoy, espero que os haya gustado este post sobre los aspectos a tener en cuenta y las buenas prácticas antes de instalar SQL Server. Si han quedado dudas o tenéis algún comentario, no dudéis en dejarlo abajo. Y si os ha gustado, compartidlo con vuestros colegas DBAs. Hasta la próxima.
Recientemente un cliente me pidió ayuda porque uno de sus campos numéricos pierde precisión con los decimales. Como me parece muy importante quiero aprovechar para aclarar conceptos, es algo complejo, pero voy a tratar de dejarlo lo más claro posible. Como sabemos tenemos varios tipos de datos que nos van a permitir almacenar números en SQL Server. Vamos a ir viendo uno a uno, pero antes tenemos que saber que significan una serie de conceptos. Los tipos de datos en SQL Server tienen 3 cualidades:
PRECISIÓN: Cantidad máxima de dígitos que puede tener en total (entero + decimal).
ESCALA: Cantidad máxima de dígitos después del decimal que puede tener.
PRECISION_RADIX: Especifica la potencia en la que se expresa la precisión, admite los valores 2 o 10, luego profundizamos más sobre esto.
Ahora sí, los tipos de datos, partamos de esta imagen y vamos viendo en detalle:
Tipos de Datos: BIGINT, INT, SMALLINT y TINYINT
Estos tipos de datos se usan para almacenar datos numéricos exactos y enteros. NO ADMITEN DECIMALES. Tenemos que usar uno u otro en función de nuestras necesidades, aunque, siempre es recomendable el más pequeño posible para ahorrar espacio en disco y ganar rendimiento. Por ejemplo, para un valor de edad de una persona con un tinyint es más que suficiente (con el estado actual de la ciencia nadie va a vivir más de 255 años o no habría dinero para pagarle la pensión), pero para un ID de una tabla 255 posibles opciones se queda corto.
Tipos de Datos: DECIMAL y NUMERIC
Antes de seguir, vamos a aclarar una de las mayores dudas que tiene la gente en SQL Server: DECIMAL y NUMERIC son sinónimos, da igual cual uses, es lo mismo, no hay uno mejor, va a rendir igual, van a comportarse igual y cualquier otra cosa que podáis imaginar. ¿Claro esto? Vale genial, esta es la pregunta que más veces me han hecho desde que me dedico a las bases de datos y a partir de ahora al que me lo pregunte le mandaré a vosotros. Volviendo a lo nuestro, estos datos son numéricos con una precisión y una escala fija. La precisión máxima que pueden tener es de 38 y la escala puede ser desde 0 hasta la precisión que hayamos definido. El tamaño que ocupa en disco y por tanto su rendimiento dependerá de la precisión que definamos así que, como es lógico, tenemos que usar una precisión suficiente para almacenar lo que necesitamos, pero sin pasarnos.
Tipos de Datos: MONEY y SMALLMONEY
La teoría dice que son tipos de datos que usa SQL para almacenar valores monetarios, pero, permitidme ser muy claro en esto, es una GRANDISIMA MIERDA. No voy a decir más, os dejo una foto y al que vea usando datos de este tipo le cortaré las manos.
Nota: Ya sé lo que me vais a decir, que no se puede dividir dinero entre dinero, pero no lo uséis y os ahorraréis problemas.
Tipos de Datos: FLOAT Y REAL
Estos son tipos de datos numéricos y aproximados que se utilizan con datos numéricos de coma flotante. Para que nos entendamos son datos numéricos para operaciones científicas y no los vamos a usar para almacenar nuestros valores. Como máximo admiten hasta 15 dígitos el FLOAT y 7 el REAL, aunque en al consultar su precisión vemos 53 o 24 para estos tipos de datos, eso es el número de bits que almacena internamente. Lo importante aquí es que no son números exactos y cuando llegas a la precisión máxima va a redondear por lo que bajo ningún concepto deberíamos utilizarlos para almacenar nuestros valores numéricos. No tienen escala por defecto, admite tantos decimales como precisión tenga. Si os fijáis otra vez en la primera captura que os he puesto al principio, estos dos tipos de datos tienen un valor NUMERIC_PRECISION_RADIX distinto a los demás, esto es porque se almacenan en binario no en base decimal en la base de datos. Como esto está muy bien explicado en la Wikipedia y este post ya se ha alargado demasiado os dejo el enlace por si os interesa profundizar en el tema https://es.wikipedia.org/wiki/Coma_flotante.
Enhorabuena por haber llegado hasta aquí abajo, espero que hayáis aprendido tanto leyendo esto como yo me he desasnado escribiéndolo😝 Antes de cerrar os dejo un apunte más copiado directamente de la web de SQL y ya no os robo más tiempo.
CONVERISIONES DE DATOS
Al convertir de decimal o numeric a float o real se puede provocar una pérdida de precisión. Al convertir de int, smallint, tinyint, float, real, money o smallmoney a decimal o numeric se puede provocar un desbordamiento. De forma predeterminada, SQL Server usa el redondeo cuando convierte un número a un valor decimal o numeric con una precisión y una escala inferiores. Y a la inversa, si la opción SET ARITHABORT está establecida en ON, SQL Server genera un error cuando se produce un desbordamiento. La pérdida de únicamente precisión y escala no es suficiente para generar un error.
Colabora con nosotros
SoyDBA.es es gratis para ti y siempre va a serlo. Sin embargo, a nosotros si que nos cuesta dinero además de mucho esfuerzo. Puedes colaborar con nosotros con un donativo por PayPal o usando nuestros enlaces de afiliado para colaborar sin que te cueste nada. Tenemos enlace de Amazon y de Aliexpress
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.