Seguimos con el tema de ayer sobre el Parameter Sniffing en SQL Server y, como prometimos, vamos a ver cómo podemos hacer para controlarlo y beneficiarnos de ello minimizando sus inconvenientes. Es este, por tanto, una segunda parte del artículo de ayer que os recomiendo encarecidamente leer antes de continuar con este. Como ya sabemos, si la distribución de nuestros datos es relativamente equitativa, un reaprovechamiento del plan de ejecución de una consulta será muy beneficioso para el rendimiento. De lo contrario, si la distribución de datos tiene gran variación, reutilizar un plan hará que este no sea el óptimo para esa ocasión.
¿Es malo el parameter sniffing?
Empecemos por el principio, la pregunta que todos os estáis haciendo ¿es malo el parameter sniffing para el rendimiento? Para mi la respuesta es no, aun con todos sus inconvenientes, conociendo su comportamiento podremos beneficiarnos en gran medida de ello. En la mayoría de escenarios OLTP, el comportamiento normal del parameter sniffing mejora el rendimiento de las consultas. Para los escenarios en los que nos encontramos con inconvenientes, normalmente será en algún procedimiento almacenado y no todos y, por suerte, tenemos varias alternativas para solventar el problema.
Identificando el problema del parameter sniffing
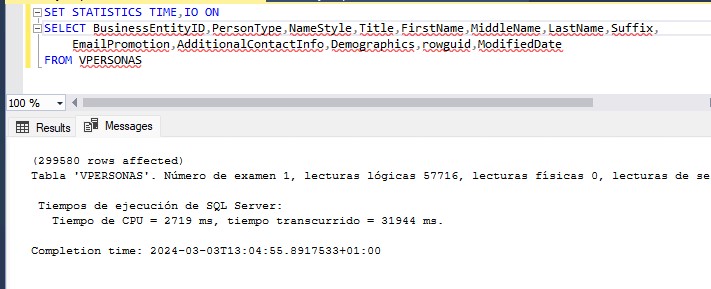
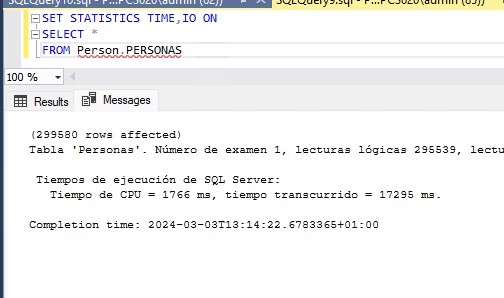
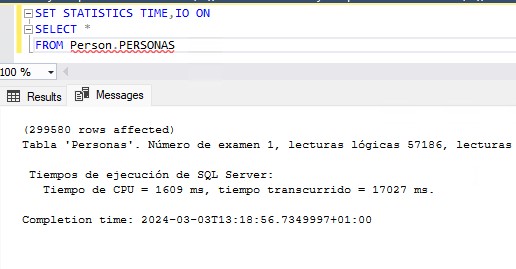
El primer paso cuando tenemos un problema es reconocerlo y en esta ocasión será sencillo. Si no tenemos habilitado la parametrización forzada bastará con ejecutar nuestra consulta fuera del procedimiento almacenado para comparar los planes. En otras ocasiones los usuarios nos darán pistas sin quererlo, como cuando unos clientes me decían que tras reiniciar el servidor el procedimiento volvía a funcionar. Reiniciar, por si solo no resuelve nada y si no somos capaces de saber que provocaba el problema antes del reinicio nos volveremos a encontrar en esa misma situación antes o después. Pero esta discusión es para otra ocasión, volvamos a mi anécdota.
Lo que les pasaba a mis clientes es que si la primera ejecución del plan de la caché era con un parámetro con un volumen de datos muy inferior a la media, el plan cacheado iba a ir mal para todas las siguientes ejecuciones. Como la caché de SQL se vacía al reiniciar y ellos estaban esperando el reinicio para ejecutar el SP con los parámetros que antes daban problemas ya se almacenaba en caché el plan correcto y todo iba bien hasta que por presión de memoria ese plan se borraba y la siguiente ejecución era de un parámetro distinto.
Soluciones al problema del parameter sniffing
Bien, sabemos que el causante de nuestro problema de rendimiento es un problema de parameter sniffing. Ahora tenemos que solucionarlo. Para ello os voy a proponer distintas soluciones.
No cambiar nada
Sabemos lo que está pasando y que es el comportamiento natural de SQL Server, expliquemos todo esto a nuestros usuarios y que se conformen con el resultado. No va a funcionar, ¿verdad?. Habéis soltado una carcajada al leerlo que se ha oído en la luna, que os conozco. Los usuarios de SQL necesitan sus datos y los necesitan rápido y por mucho que nosotros les contemos no se van a conformar. Y están en su derecho así que descartemos este punto y vayamos a por los siguientes.
Pasa el marrón a otro
La siguiente solución que tengo que poner, pero que, al igual que la anterior, tampoco os recomiendo es pasar la pelota al equipo que desarrolla el código del procedimiento. Podríais explicarles lo que está pasando y que creen un SP distinto para cada parámetro. Como os digo esto es una mala idea, malísima en realidad. Acaba completamente con todas las ventajas de un procedimiento almacenado y ni hablar de si problema si es causado por tener activada la parametrización forzada. Descartemos este punto también por favor.
Actualiza tu SQL
Ya comentamos ayer que el las últimas versiones de SQL Server (a partir de 2019) entran en juego los planes de ejecución con joins adaptativos lo que nos permitirá que pasadas unas ejecuciones se persistirá un plan dinámico en caché con varias alternativas en función de los parámetros. Esto es un avance, sin embargo, aún no lo veo una solución pues necesitas de varias ejecuciones lentas para que SQL se de cuenta de lo que pasa y en un entorno con gran cantidad de consultas donde los planes en caché no duran tanto como nos gustaría puede no ser una solución.
Recompilaciones del procedimiento
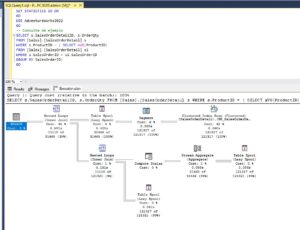
En este punto, ya hemos descartado no hacer nada y también crear varios procedimientos almacenados, veamos cómo podemos hacer para que nuestro procedimiento problemático rinda como debería. Una de estas soluciones es crear el procedimiento para que no haga uso de los planes en caché y recompile siempre el plan de ejecución. Esto lo haremos en la declaración del procedimiento con la sugerencia de procedimiento almacenado RECOMPILE. Por ejemplo:
CREATE PROCEDURE GET_OrderDetail
@id INT
WITH RECOMPILE
AS
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = @idCon esa simple sugerencia conseguiremos que los planes de ejecución de todas las consultas del procedimiento almacenado se recopilen antes de la ejecución, lo que nos supondrá un mayor coste de CPU pero nos garantizará un plan óptimo. Si es uno o unos pocos procedimientos en los que tenemos problemas al final compensa.
Recompilaciones de las consultas
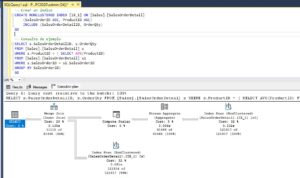
Si el problema lo estamos teniendo fuera de un procedimiento almacenado por tener habilitada la parametrización forzada o si queremos hilar más fino porque sabemos que solo una de las muchas consultas de un procedimiento es la que tiene problemas podemos hilar más fino y aplicar la sugerencia RECOMPILE a nivel de consulta. Por ejemplo
CREATE PROCEDURE GET_OrderDetail
@id INT
AS
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = @id
OPTION (RECOMPILE)
INSERT INTO log_sp (SP_Name, Fecha) VALUES ('GET_OrderDetail', GETDATE())En este ejemplo tenemos dos consultas, un select y un insert, sin embargo solo recopilaremos el plan de ejecución de la primera.
Optimizado para valor
Otra de las opciones que tenemos a nivel de consulta es utilizar una sugerencia que indique que calcule el plan de ejecución para un valor concreto y no para el que se pase como parámetro de nuestro SP. En algunas ocasiones puede ser una solución pero a mi no me gusta porque genera planes ultra dimensionados cuando no son necesarios y requiere mucho mantenimiento a medida que los datos cambian. Si recordáis el ejemplo del almacén que vimos ayer es como si desplegamos todos los recursos necesarios para mover maquinaria industrial pesada para al final realmente mover un clavo. Aun así os dejo un ejemplo de cómo sería:
CREATE PROCEDURE GET_OrderDetail
@id INT
AS
SELECT *
FROM Sales.SalesOrderDetail
WHERE ProductID = @id
OPTION (OPTIMIZE FOR (@ProductID=897))Conclusión
Aunque siempre digo que no debemos influir sobre el comportamiento normal de SQL Server en estos casos siempre hago una excepción. Nosotros conocemos nuestros datos (o deberíamos) y cuando el parameter sniffing no termine de adaptarse a nuestras necesidades no debemos tener miedo de actuar. Usa todas las herramientas que SQL pone a nuestra disposición y anticipate a las llamadas de usuarios descontentos, Query Store tiene una vista de consultas recursivas que nos mostrará estos casos de una manera muy cómoda. Añade tus sugerencias de consulta o procedimientos y no dejes que nada frene tus consultas.
Espero que este artículo te haya sido útil y que te ayude a optimizar el rendimiento de tus consultas en SQL Server. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!