En nuestro trabajo como administradores de bases de datos, una de las tareas más cruciales y desafiantes a las que nos vamos a enfrentar es calcular el dimensionamiento de un servidor SQL Server. Este proceso implica determinar la cantidad de recursos necesarios para que el servidor funcione de manera óptima, teniendo en cuenta factores como el número de usuarios, la cantidad de datos y las operaciones de la base de datos.
Consideraciones Iniciales
El dimensionamiento adecuado de un servidor SQL Server no es una tarea sencilla. Requiere un conocimiento profundo de las características y capacidades del servidor, así como de las necesidades y demandas de la base de datos y las aplicaciones que se ejecutan en él. Antes de sumergirnos en cálculos y métricas, es esencial entender la carga de trabajo que manejará nuestro nuevo servidor. Esto implica analizar el volumen de transacciones, la concurrencia de usuarios, y los patrones de acceso a los datos. Solo con un conocimiento profundo de estas variables podemos comenzar a esbozar los requisitos de nuestro servidor.
Si el nuevo servidor se va a usar para sustituir uno ya existente lo vamos a tener mucho más fácil, podremos basarnos en el estado actual y analizar sus puntos flacos para tratar de mejorarlos. Hablamos de migraciones en este otro artículo.
El verdadero reto lo tendremos cuando nos enfrentemos a un escenario nuevo, desde 0. En este caso, será crucial la colaboración de los equipos responsables de los datos o de las aplicaciones, en especial de un buen project manager, además de otros departamentos de negocio que nos puedan indicar previamente las expectativas de carga de trabajo y necesidades de almacenamiento. En un mundo ideal, todas estas necesidades estarían especificadas en la documentación del proyecto y no tendríamos que hacer más preguntas. Pero, como eso no es lo que nos solemos encontrar (y menos mal, porque así tengo algo de lo que escribiros), vamos a analizar en profundidad que debemos tener en cuenta.
Aspectos a evitar
A lo largo de mis años de experiencia me he enfrentado a las suficientes migraciones y nuevos despliegues como para haber elaborado una lista con los aspectos que si o si debo evitar si quiero llevar el proyecto a buen puerto. Os comparto un pequeño resumen:
- Subestimar el crecimiento: Y no solo me refiero a los datos, eso es quizá lo de menos. Debemos tener una idea clara de las necesidades de recursos del servidor para que un futuro aumento de la carga de trabajo no nos degrade el rendimiento o, directamente, tumbe el servicio.
- Falta de monitorización: Es imprescindible monitorizar completamente el servidor tanto antes de la migración si es el caso, como tras la implementación, SIEMPRE. Si disponemos de un servidor antiguo que tenemos que migrar, no monitorizarlo y conocer su comportamiento completamente nos llevará a problemas en un futuro. No hagamos conjeturas, y apoyémonos en datos.
- No conocer los objetivos comerciales: Este punto está muy ligado al primero pero tiene su razón de ser como punto independiente. Puede que el equipo de desarrollo haya desplegado una aplicación para los 500 clientes actuales y esos sean los datos que tenemos nosotros pero, si desde la dirección se han marcado el objetivo de doblar esa cifra cada ejercicio, pronto nuestro servidor no dará más de sí.
- Sobreaprovisionamiento: Puede parecer una buena opción visto lo visto pero nada más lejos de la realidad. Aprovisionar más recursos de los que necesitamos o vamos a necesitar a corto plazo será un malgasto de recursos y no nos dejará en buen lugar como profesionales.
Cómo calcular un dimensionamiento correcto
Ahora que ya sabemos los puntos clave que debemos evitar vamos a ver uno a uno como debemos hacerlo.
Carga de trabajo
Como ya hemos dicho, comprender la carga de trabajo que afrontará nuestro servidor es el aspecto fundamental para un correcto dimensionamiento. Si hablamos de un servidor completamente nuevo nos tendremos que basar en las necesidades que nos indiquen los responsables del proyecto y cobrarán más sentido el resto de apartados. Si por el contrario estamos sustituyendo un servidor existente este punto es de vital importancia. Usaremos todos los recursos que tengamos a nuestra disposición y en ocasiones un trabajo de monitorización previo nos facilitará el trabajo.
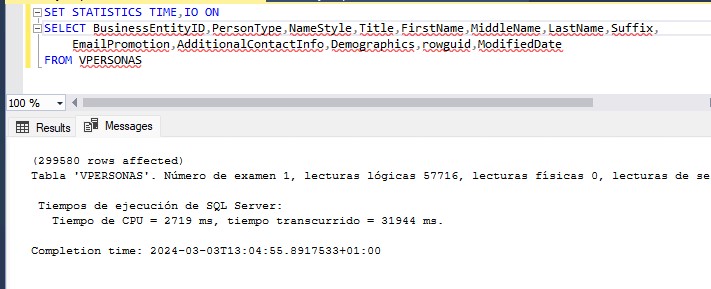
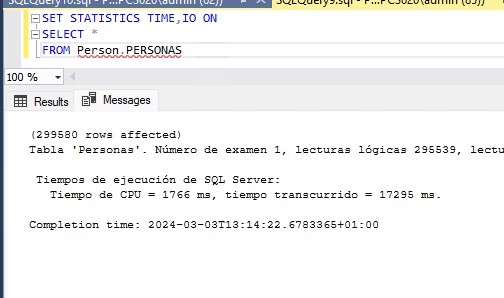
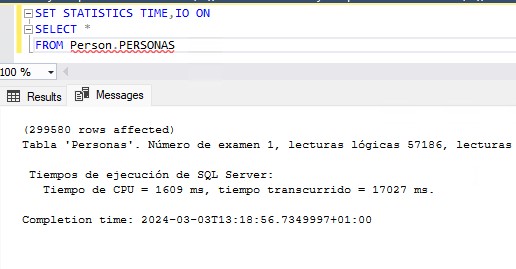
En este sentido, a mi me gusta tener siempre en mis servidores un proceso que controle el crecimiento de los ficheros de base de datos (usando la vista sys.master_files por ejemplo) y que lo persista en una tabla de configuración. De esta manera a la hora de calcular el dimensionamiento podremos hacernos una idea clara del histórico de crecimiento de nuestras bases de datos.
Para calcular las necesidades de otros recursos echaremos mano de las DMV que SQL Server pone a nuestra disposición, de Query Store o del monitor de rendimiento de Windows. Prestaremos especial atención a los tiempos de espera de nuestras consultas para, en la medida de lo posible, acabar con esos cuellos de botella.
Estrategia proactiva
Las bases de datos no son objetos estáticos, están continuamente cambiando y como tal, nosotros tendremos que monitorizar y verificar que las previsiones iniciales que hicimos son correctas. No solo hablo de las pruebas antes del “go live” sino de todo el ciclo de vida del servidor. Una buena monitorización nos permitirá pronosticar una futura necesidad de recursos y anticiparnos a ese dimensionamiento antes de que exista degradación en el rendimiento del servidor.
El mercado está repleto de soluciones integrales de monitorización de rendimiento de SQL Server pero, cuando el presupuesto no lo permite, tendremos que ser creativos con las soluciones nativas sin dejar de lado esta tarea. Nuevamente las DMV de SQL Server, Query Store y el monitor de rendimiento de Windows serán nuestros aliados. Además, si persistimos estos datos, seremos capaces de analizar tendencias y predecir comportamientos en un futuro (de esto sabe mucho la gente de BI).
Objetivos Comerciales y dimensionamiento
No trabajamos solos, en la mayoría de los casos nuestras bases de datos son una pieza clave para el desempeño de la actividad de negocio. Sería de necios pensar que podemos hacer nuestro trabajo sin alinearnos con el resto de departamentos e ignorando los objetivos comerciales de nuestra organización. En este sentido, cuanto mayor sea nuestro conocimiento del sector, de la empresa en particular y de sus objetivos mejores previsiones podremos hacer.
Igualmente, esto va en los dos sentidos, es nuestra responsabilidad hacernos valer y que los jefes que toman las decisiones sepan que tienen que contar con nosotros. He trabajado en sitios donde no era así, se tomaban decisiones de negocio sin comunicar los objetivos comerciales al departamento de IT y sin trasladar las necesidades de crecimiento. ¿De verdad piensas que tus sistemas están preparados para asumir de la noche a la mañana una fusión que duplique la cantidad de clientes?
Podríamos resumir este apartado en tres aspectos fundamentales, conoce los objetivos comerciales, involucra a todas las partes interesadas en la planificación y pronostica de manera adecuada la capacidad de los sistemas antes de que sea tarde.
Escalabilidad, prepárate para un ajuste en el dimensionamiento
Como último punto a tener en cuenta pero no por ello menos importante tenemos que ser capaces de diseñar un sistema capaz de crecer. Ya hemos dicho que nuestras bases están vivas y cambian con el tiempo, normalmente, si todo va bien, crecerán. También hemos visto que sobredimensionar de primeras un sistema puede ser un malgasto de recursos. Aquí es donde entra en juego la escalabilidad. No voy a profundizar más en el concepto porque ya le hemos dedicado un artículo completo al tema que puedes leer aquí.
Es importante que conozcas y que trabajes conjuntamente con el equipo de infraestructura para brindar a tus servidores de esta capacidad. Y no solo con sistemas, confirma con los equipos de desarrollo si sus aplicativos están preparados para un escalado horizontal. Si es así, considera planificar nuevas máquinas, licencias y todo lo necesario para asumir el crecimiento futuro, aunque solo sea una planificación y no se implante a corto plazo es importante tenerlo documentado.
Sin embargo, este escenario no es lo más común. Normalmente priorizaremos un escalado vertical, aumentando los recursos de nuestro servidor siempre que sea posible. Aquí entra en juego ese trabajo conjunto con los compañeros de sistemas del que estábamos hablando antes. No es lo mismo un escalado vertical en una máquina física que en una virtual o en la nube. Asegúrate de que tienes el presupuesto y la capacidad para crecer y hacer frente a las futuras capacidades del servicio.
Conclusión
El dimensionamiento adecuado de un servidor SQL Server es esencial para garantizar su rendimiento y eficiencia. Al tener en cuenta factores como la carga de trabajo, el rendimiento, la capacidad de almacenamiento y la concurrencia, y al utilizar las herramientas y técnicas adecuadas, podemos hacer una estimación precisa de los recursos necesarios para nuestro servidor. Aun así, el trabajo no termina ahí, las bases de datos están en constante crecimiento y tenemos que ser capaces de adelantarnos a las necesidades de recurso y redimensionar el servidor correctamente.
Espero que este artículo te haya sido útil y que te ayude a dimensionar correctamente tus SQL Server. Si tenéis alguna duda o sugerencia, podéis dejarla en Twitter, por mail o dejarnos un mensaje en los comentarios. Y recuerda que también tenemos un grupo de LinkedIn y un canal de YouTube a los que te puede unir. ¡Hasta la próxima!